Category Archives: Database

SQL Server 2005中的分区表(五):添加一个分区
所谓天下大事,分久必合,合久必分,对于分区表而言也一样。前面我们介绍过如何删除(合并)分区表中的一个分区,下面我们介绍一下如何为分区表添加一个分区。 为分区表添加一个分区,这种情况是时常会 发生的。比如,最初在数据库设计时,只预计了存放3年的数据,可是到了第4天怎么办?这样的话,我们就可以为分区表添加一个分区,让它把新的数据放在新的分区里。再比如,最初设计时,一个分区用于存放一年的数据,结果在使用的时候才发现,一年的数据太多,想将一个分区中的数据分为两个分区来存放。 遇到这种情况,就必须要为分区表添加一个分区了。 当然,我们也可以使用修改分区函数的方式来添加一个分区,但是在修改分区函数时,我们必须要注意另一个问题——分区方案。为什么还要注意分区方案呢?我们回过头来看一下前面是怎么定义分区函数和分区方案的,如以下代码所示: [c-sharp] view plaincopy --添加分区函数 CREATE PARTITION FUNCTION partfunSale (datetime) AS RANGE RIGHT FOR VALUES ('20100101′,’20110101′,’20120101′,’20130101') --添加分区方案 CREATE PARTITION SCHEME partschSale AS PARTITION partfunSale TO ( Sale2009, Sale2010, Sale2011, Sale2012, Sale2013) 从以上代码中可以看出,分区函数定义了用于分区的数据边界,而分区函数指定了符合分区边界的数据存放在文件组。因此,分区方案中指定的文件组个数应该是比分区函数中指定的边界数大1的。如上例中,分区函数中指定的边界数为4,那么在分区方案中指定的文件组数就为5。 如果,我们将分区函数中的边界数增加一个,那么分区方案中的文件组数也就要相应地增加一个。因此,我们不能简简单单地通过修改分区函数的方式来为分区表添加一个分区。 那么,我们应该怎么做呢?是不是要先为分区方案添加一个文件组? 这种想法是没有错的,想要为分区表添加一个分区,可以通过以下两个步骤来实现: 1、为分区方案指定一个可以使用的文件组。 2、修改分区函数。 在为分区方案指定一个可用的文件组时,该分区方案并没有立刻使用这个文件组,只是将文件组先备用着,等修改了分区函数之后分区方案才会使用这个文件组(不要忘记了,如果分区函数没有变,分区方案中的文件组个数就不能变)。 为分区方案指定一个可用的文件组的代码如下所示: [c-sharp] view plaincopy ALTER PARTITION SCHEME partschSale NEXT USED [Sale2010] 其中: 1、ALTER PARTITION SCHEME意思是修改分区方案 2、partschSale是分区方案名 3、NEXT USED意思是下一个可使用的文件组 4、[Sale2010]是文件组名 为分区方案添加了下一个可使用的文件组之后,分区方案并没有立刻使用这个文件组,此时我们可以通过查看分区方案的源代码来证实。查看方法是:在SQL Server Management Studio中,选择数据库-->存储-->分区方案,右击分区方案名,在弹出的菜单中选择“编写分区方案脚本为”-->CREATE到-->新查询编辑器窗口,如下图所示: 为分区方案添加了下一个可使用的文件组之后,我们就可以动手修改分区函数了,使用代码如下所示: [c-sharp] view plaincopy ALTER PARTITION FUNCTION partfunSale() SPLIT RANGE ('20100101') 其中: 1、ALTER PARTITION FUNCTION意思是修改分区函数 2、partfunSale()为分区函数名 3、SPLIT RANGE 意思是分割界限 4、’20100101′ 是用于分割的界限值 当然,我们在修改分区函数前后都可以统计一下各物理分区的数据记录情况,如以下代码所示: [c-sharp] view plaincopy --统计所有分区表中的记录总数 select $PARTITION.partfunSale(SaleTime) as 分区编号,count(id) as 记录数 from Sale group by $PARTITION.partfunSale(SaleTime) --原来的分区函数是将2010-1-1之前的数据放在第1个分区表中,将2010-1-1至2011-1-1之间的数据放在第2个分区表中 --现在需要将2011-1-1之前的数据都放在第1个分区表中,也就是将第1个分区表和第2个分区表中的数据合并 --修改分区函数 ALTER PARTITION FUNCTION partfunSale() SPLIT RANGE ('20100101') --统计所有分区表中的记录总数 select $PARTITION.partfunSale(SaleTime) as 分区编号,count(id) as 记录数 from Sale group by $PARTITION.partfunSale(SaleTime) 以上代码的运行结果如下图所示: 从上图中可以看出,分区表中已经添加了一个分区,我们也可以再一次查看分区方案的源代码,如下图所示,这个时候分区方案也自动添加了一个文件组。 原创不容易,转载请注明出处。http://blog.csdn.net/smallfools/archive/2009/12/04/4940185.aspx
View DetailsSQL Server 2005中的分区表(四):删除(合并)一个分区
在前面我们介绍过如何创建和使用一个分区表,并举了一个例子,将不 同年份的数据放在不同的物理分区表里。具体的分区方式为: 第1个小表:2010-1-1以前的数据(不包含2010-1-1)。 第2个小表:2010-1-1(包含2010-1-1)到2010-12-31之间的数据。 第3个小表:2011-1-1(包含2011-1-1)到2011-12-31之间的数据。 第4个小表:2012-1-1(包含2012-1-1)到2012-12-31之间的数据。 第5个小表:2013-1-1(包含2013-1-1)之后的数据。 分区函数的代码如下所示: [c-sharp] view plaincopy CREATE PARTITION FUNCTION partfunSale (datetime) AS RANGE RIGHT FOR VALUES ('20100101′,’20110101′,’20120101′,’20130101') 假设我们在创建分区表之后发现,2010年以前的数据并不多,完全可以将它们与2010年的数据进行合并,放在同一个分区里,也就是说,具体的分区方式改为: 第1个小表:2011-1-1以前的数据(不包含2011-1-1)。 第2个小表:2011-1-1(包含2011-1-1)到2011-12-31之间的数据。 第3个小表:2012-1-1(包含2012-1-1)到2012-12-31之间的数据。 第4个小表:2013-1-1(包含2013-1-1)之后的数据。 由于上面的需求更改了数据分区的条件,因此,我们必须要修改分区函数,因为分区函数的作用就是要来告诉SQL Server怎么存放数据的。只要分区函数修改了,SQL Server会自动将数据重新分配,按照新的分区函数指定的方式来存储数据。 先假设我们还没有创建过分区表,要满足上面的条件,我们必须要写出如下代码的创建分区函数的SQL语句 [c-sharp] view plaincopy CREATE PARTITION FUNCTION partfunSale (datetime) AS RANGE RIGHT FOR VALUES ('20110101′,’20120101′,’20130101') 比较一个新的分区函数和老的分区函数,看看他们有什么区别? 的确,我们很容易就可以发现,老的分区函数里多了一个分界值——也就是’20100101’。那么,修改老的分区函数,事实上就是将这分界值删除。简单一点说,删除(合并)一个分区,事实上就是在分区函数中将多余的分界值删除。 删除分区函数中的分界值,也就是修改分区函数的方法如下所示: [c-sharp] view plaincopy ALTER PARTITION FUNCTION partfunSale() MERGE RANGE ('20100101') 其中: 1、ALTER PARTITION FUNCTION 意思是修改分区函数 2、partfunSale()为分区函数名 3、MERGE RANGE意思是合并界限。事实上,合并界限和删除分界值是一个意思。 我们可以在修改分区函数时先统计一下各物理分区中的记录总数,在修改分区之后,再统计一下各物理分区中的记录总数,看一下修改分区函数后的数据变化情况,代码如下所示: [c-sharp] view plaincopy --统计所有分区表中的记录总数 select $PARTITION.partfunSale(SaleTime) as 分区编号,count(id) as 记录数 from Sale group by $PARTITION.partfunSale(SaleTime) --原来的分区函数是将2010-1-1之前的数据放在第1个分区表中,将2010-1-1至2011-1-1之间的数据放在第2个分区表中 --现在需要将2011-1-1之前的数据都放在第1个分区表中,也就是将第1个分区表和第2个分区表中的数据合并 --修改分区函数 ALTER PARTITION FUNCTION partfunSale() MERGE RANGE ('20100101') --统计所有分区表中的记录总数 select $PARTITION.partfunSale(SaleTime) as 分区编号,count(id) as 记录数 from Sale group by $PARTITION.partfunSale(SaleTime) 运行结果如下图所示: 现在还有一个问题,就是通过修改分区函数合并数据之后,数据都存放在哪里了?在修改之前,数据分别存放在文件组Sale2009和Sale2010中,修改之后,数据放到哪里去了呢? 事实上,在修改分区函数之后,SQL Server也会自动修改分区方案,将处于两个物理分区中的数据放在同一个物理分区里了。可以通过查看分区方案的方式来查看数据具体的存放位置。 查看分区方案的方式为:在SQL Server Management Studio中,选择数据库-->存储-->分区方案,右击分区方案名,在弹出的菜单中选择“编写分区方案脚本为”-->CREATE到-->新查询编辑器窗口 然后在新查询编辑器窗口可以看到下图代码。 从上图中可以看出,分区方案将原来Sale2010文件组中的数据合并到了Sale2009文件组中。 原创不容易,转载请注明出处。http://blog.csdn.net/smallfools/archive/2009/12/04/4937878.aspx
View DetailsSQL Server 2005中的分区表(三):将普通表转换成分区表
在设计数据库时,经常没有考虑到表分区的问题,往往在数据表承重的负担越来越重时,才会考虑到分区方式,这时,就涉及到如何将普通表转换成分区表的问题了。 那么,如何将一个普通表转换成一个分区表 呢?说到底,只要将该表创建一个聚集索引,并在聚集索引上使用分区方案即可。 不过,这回说起来简单,做起来就复杂了一点。还是接着上面的例子,我们先使用以下SQL语句将原有的Sale表删除。 [c-sharp] view plaincopy --删除原来的数据表 drop table Sale 然后使用以下SQL语句创建一个新的普通表,并在这个表里插入一些数据。 [c-sharp] view plaincopy --新建一个普通的数据表 CREATE TABLE Sale( [Id] [int] IDENTITY(1,1) NOT NULL, --自动增长 [Name] [varchar](16) NOT NULL, [SaleTime] [datetime] NOT NULL, CONSTRAINT [PK_Sale] PRIMARY KEY CLUSTERED --创建主键 ( [Id] ASC ) ) --插入一些记录 insert Sale ([Name],[SaleTime]) values ('张三',’2009-1-1′) insert Sale ([Name],[SaleTime]) values ('李四',’2009-2-1′) insert Sale ([Name],[SaleTime]) values ('王五',’2009-3-1′) insert Sale ([Name],[SaleTime]) values ('钱六',’2010-4-1′) insert Sale ([Name],[SaleTime]) values ('赵七',’2010-5-1′) insert Sale ([Name],[SaleTime]) values ('张三',’2011-6-1′) insert Sale ([Name],[SaleTime]) values ('李四',’2011-7-1′) insert Sale ([Name],[SaleTime]) values ('王五',’2011-8-1′) insert Sale ([Name],[SaleTime]) values ('钱六',’2012-9-1′) insert Sale ([Name],[SaleTime]) values ('赵七',’2012-10-1′) insert Sale ([Name],[SaleTime]) values ('张三',’2012-11-1′) insert Sale ([Name],[SaleTime]) values ('李四',’2013-12-1′) insert Sale ([Name],[SaleTime]) values ('王五',’2014-12-1′) 使用以上代码创建的表是普通表,我们来看一下表的属性,如下图所示。 在以上代码中,我们可以看出,这个表拥有一般普通表的特性——有主键,同时这个主键还是聚集索引。前面说过,分区表是以某个字段为分区条件,所以,除了这个字段以外的其他字段,是不能创建聚集索引的。因此,要想将普通表转换成分区表,就必须要先删除聚集索引,然后再创建一个新的聚集索引,在该聚集索引中使用分区方案。 可惜的是,在SQL Server中,如果一个字段既是主键又是聚集索引时,并不能仅仅删除聚集索引。因此,我们只能将整个主键删除,然后重新创建一个主键,只是在创建主键时,不将其设为聚集索引,如以下代码所示: [c-sharp] view plaincopy --删掉主键 ALTER TABLE Sale DROP constraint PK_Sale --创建主键,但不设为聚集索引 ALTER TABLE Sale ADD CONSTRAINT PK_Sale PRIMARY KEY NONCLUSTERED ( [ID] ASC ) ON [PRIMARY] 在重新非聚集主键之后,就可以为表创建一个新的聚集索引,并且在这个聚集索引中使用分区方案,如以下代码所示: [c-sharp] view plaincopy --创建一个新的聚集索引,在该聚集索引中使用分区方案 CREATE CLUSTERED INDEX CT_Sale ON Sale([SaleTime]) ON partschSale([SaleTime]) 为表创建了一个使用分区方案的聚集索引之后,该表就变成了一个分区表,查看其属性,如下图所示。 我们可以再一次使用以下代码来看看每个分区表中的记录数。 [c-sharp] view plaincopy --统计所有分区表中的记录总数 select $PARTITION.partfunSale(SaleTime) as 分区编号,count(id) as 记录数 from Sale group by $PARTITION.partfunSale(SaleTime) 以上代码的运行结果如下所示,说明在将普通表转换成分区表之后,数据不但没有丢失,而且还自动地放在了它应在的分区表中了。 原创不容易,转载请注明出处。http://blog.csdn.net/smallfools/archive/2009/12/03/4934119.aspx
View Details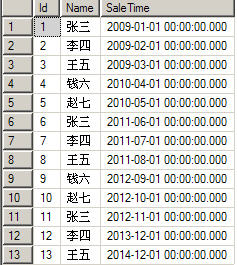
SQL Server 2005中的分区表(二):如何添加、查询、修改分区表中的数据
在创建完分区表后,可以向分区表中直接插入数据,而不用去管它这些数据放在哪个物理上的数据表中。接上篇文章,我们在创建好的分区表中插入几条数据: 从以上代码中可以看出,我们一共在数据表中插入了13条数据,其中第1至3条数据是插入到第1个物理分区表中的;第4、5条数据是插入到第2个物理分区表中的;第6至8条数据是插入到第3个物理分区表中的;第9至11条数据是插入到第4个物理分区表中的;第12、13条数据是插入到第5个物理分区表中的。 从SQL语句中可以看出,在向分区表中插入数据方法和在普遍表中插入数据的方法是完全相同的,对于程序员而言,不需要去理会这13条记录研究放在哪个数据表中。当然,在查询数据时,也可以不用理会数据到底是存放在哪个物理上的数据表中。如使用以下SQL语句进行查询: [c-sharp] view plaincopy select * from Sale 查询的结果如下图所示: 从上面两个步骤中,根本就感觉不到数据是分别存放在几个不同的物理表中,因为在逻辑上,这些数据都属于同一个数据表。如果你非想知道哪条记录是放在哪个物理上的分区表中,那么就必须使用到$PARTITION函数,这个函数的可以调用分区函数,并返回数据所在物理分区的编号。 说起来有点难懂,不过用起来很简单。$PARTITION的语法是: $PARTITION.分区函数名(表达式) 假设,你想知道2010年10月1日的数据会放在哪个物理分区表中,你就可以使用以下语句来查看。 [c-sharp] view plaincopy select $PARTITION.partfunSale ('2010-10-1') 在以上语句中,partfunSale()为分区函数名,括号中的表达式必须是日期型的数据或可以隐式转换成日期型的数据,如果要问我为什么,那么就回想一个怎么定义分区函数的吧(CREATE PARTITION FUNCTION partfunSale (datetime))。在定义partfunSale()函数时,指定了参数为日期型,所以括号中的表达式必须是日期型或可以隐式转换成日期型的数据。以上代码的运行结果如下图所示: 在该图中可以看出,分区函数返回的结果为2,也就是说,2010年10月1日的数据会放在第2个物理分区表中。 再进一步考虑,如果想具体知道每个物理分区表中存放了哪些记录,也可以使用$PARTITION函数。因为$PARTITION函数可以得到物理分区表的编号,那么只要将$PARTITION.partfunSale(SaleTime)做为where的条件使用即可,如以下代码 所示: [c-sharp] view plaincopy select * from Sale where $PARTITION.partfunSale(SaleTime)=1 select * from Sale where $PARTITION.partfunSale(SaleTime)=2 select * from Sale where $PARTITION.partfunSale(SaleTime)=3 select * from Sale where $PARTITION.partfunSale(SaleTime)=4 select * from Sale where $PARTITION.partfunSale(SaleTime)=5 以上代码的运行结果如下图所示: 从上图中我们可以看到每个分区表中的数据记录情况——和我们插入时设置的情况完全一致。同理可得,如果要统计每个物理分区表中的记录数,可以使用如下代码: [c-sharp] view plaincopy select $PARTITION.partfunSale(SaleTime) as 分区编号,count(id) as 记录数 from Sale group by $PARTITION.partfunSale(SaleTime) 以上代码的运行结果如下图所示: 除了在插入数据时程序员不需要去考虑分区表的物理情况之外,就是连修改数据也不需要考虑。SQL Server会自动将记录从一个分区表移到另一个分区表中,如以下代码所示: [c-sharp] view plaincopy --统计所有分区表中的记录总数 select $PARTITION.partfunSale(SaleTime) as 分区编号,count(id) as 记录数 from Sale group by $PARTITION.partfunSale(SaleTime) --修改编号为1的记录,将时间改为2019年1月1日 update Sale set SaleTime=’2019-1-1′ where id=1 --重新统计所有分区表中的记录总数 select $PARTITION.partfunSale(SaleTime) as 分区编号,count(id) as 记录数 from Sale group by $PARTITION.partfunSale(SaleTime) 在以上代码中,程序员将其中一条数据的时间改变了,从分区函数中可以得知,这条记录应该从第一个分区表移到第五个分区表中,如下图所示。而整个操作过程,程序员是完全不需要干预的。 原创不容易,转载请注明出处。http://blog.csdn.net/smallfools/archive/2009/12/03/4932936.aspx
View Details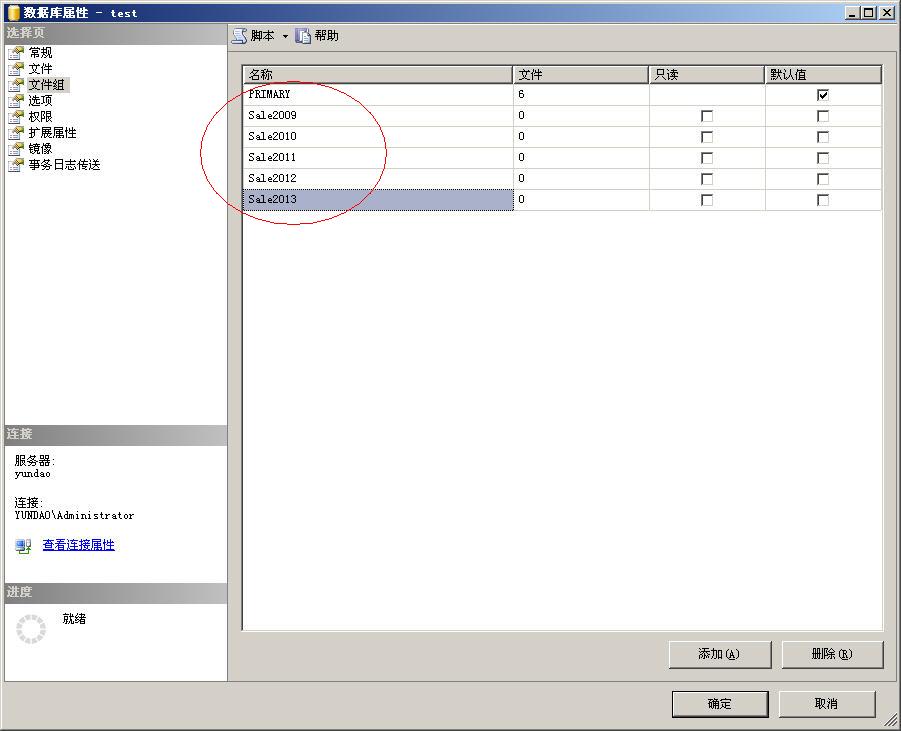
SQL Server 2005中的分区表(一):什么是分区表?为什么要用分区表?如何创建分区表?
如果你的数据库中某一个表中的数据满足以下几个条件,那么你就要考虑创建分区表了。 1、数据库中某个表中的数据很多。很多是什么概念?一万条?两万条?还是十万条、一百万条?这个,我觉得是仁者见仁、智者见智的问题。当然数据表中的数据多到查询时明显感觉到数据很慢了,那么,你就可以考虑使用分区表了。如果非要我说一个数值的话,我认为是100万条。 2、但是,数据多了并不是创建分区表的惟一条件,哪怕你有一千万条记录,但是这一千万条记录都是常用的记录,那么最好也不要使用分区表,说不定会得不偿失。只有你的数据是分段的数据,那么才要考虑到是否需要使用分区表。 3、什么叫数据是分段的?这个说法虽然很不专业,但很好理解。比如说,你的数据是以年为分隔的,对于今年的数据而言,你常进行的操作是添加、修改、删除和查询,而对于往年的数据而言,你几乎不需要操作,或者你的操作往往只限于查询,那么恭喜你,你可以使用分区表。换名话说,你对数据的操作往往只涉及到一部分数据而不是所有数据的话,那么你就可以考虑什么分区表了。 那么,什么是分区表呢? 简单一点说,分区表就是将一个大表分成若干个小表。假设,你有一个销售记录表,记录着每个每个商场的销售情况,那么你就可以把这个销售记录表按时间分成几个小表,例如说5个小表吧。2009年以前的记录使用一个表,2010年的记录使用一个表,2011年的记录使用一个表,2012年的记录使用一个表,2012年以后的记录使用一个表。那么,你想查询哪个年份的记录,就可以去相对应的表里查询,由于每个表中的记录数少了,查询起来时间自然也会减少。 但将一个大表分成几个小表的处理方式,会给程序员增加编程上的难度。以添加记录为例,以上5个表是独立的5个表,在不同时间添加记录的时候,程序员要使用不同的SQL语句,例如在2011年添加记录时,程序员要将记录添加到2011年那个表里;在2012年添加记录时,程序员要将记录添加到2012年的那个表里。这样,程序员的工作量会增加,出错的可能性也会增加。 使用分区表就可以很好的解决以上问题。分区表可以从物理上将一个大表分成几个小表,但是从逻辑上来看,还是一个大表。 接着上面的例子,分区表可以将一个销售记录表分成五个物理上的小表,但是对于程序员而言,他所面对的依然是一个大表,无论是2010年添加记录还是2012年添加记录,对于程序员而言是不需要考虑的,他只要将记录插入到销售记录表——这个逻辑中的大表里就行了。SQL Server会自动地将它放在它应该呆在的那个物理上的小表里。 同样,对于查询而言,程序员也只需要设置好查询条件,OK,SQL Server会自动将去相应的表里查询,不用管太多事了。 这一切是不是很诱人? 的确,那么我们就可以开始动手创建分区表了。 第一、创建分区表的第一步,先创建数据库文件组,但这一步可以省略,因为你可以直接使用PRIMARY文件。但我个人认为,为了方便管理,还是可以先创建几个文件组,这样可以将不同的小表放在不同的文件组里,既便于理解又可以提高运行速度。创建文件组的方法很简单,打开SQL Server Management Studio,找到分区表所在数据库,右键单击,在弹出的菜单里选择“属性”。然后选择“文件组”选项,再单击下面的“添加”按钮,如下图所示: 第二,创建了文件组之后,还要再创建几个数据库文件。为什么要创建数据库文件,这很好理解,因为分区的小表必须要放在硬盘上,而放在硬盘上的什么地方呢?当然是文件里啦。再说了,文件组中没有文件,文件组还要来有啥用呢?还是在上图的那个界面,选择“文件”选项,然后添加几个文件。在添加文件的时候要注意以下几点: 1、不要忘记将不同的文件放在文件组中。当然一个文件组中也可以包含多个不同的文件。 2、如果可以的话,将不同的文件放在不同的硬盘分区里,最好是放在不同的独立硬盘里。要知道IQ的速度往往是影响SQL Server运行速度的重要条件之一。将不同的文件放在不同的硬盘上,可以加快SQL Server的运行速度。 在本例中,为了方便起见,将所有数据库文件都放在了同一个硬盘下,并且每个文件组中只有一个文件。如下图所示。 第三、创建一个分区函数。这一步是必须的了,创建分区函数的目的是告诉SQL Server以什么方式对分区表进行分区。这一步必须要什么SQL脚本来完成。以上面的例子,我们要将销售表按时间分成5个小表。假设划分的时间为: 第1个小表:2010-1-1以前的数据(不包含2010-1-1)。 第2个小表:2010-1-1(包含2010-1-1)到2010-12-31之间的数据。 第3个小表:2011-1-1(包含2011-1-1)到2011-12-31之间的数据。 第4个小表:2012-1-1(包含2012-1-1)到2012-12-31之间的数据。 第5个小表:2013-1-1(包含2013-1-1)之后的数据。 那么分区函数的代码如下所示: [c-sharp] view plaincopy CREATE PARTITION FUNCTION partfunSale (datetime) AS RANGE RIGHT FOR VALUES ('20100101′,’20110101′,’20120101′,’20130101') 其中: 1、CREATE PARTITION FUNCTION意思是创建一个分区函数。 2、partfunSale为分区函数名称。 3、AS RANGE RIGHT为设置分区范围的方式为Right,也就是右置方式。 4、FOR VALUES ('20100101′,’20110101′,’20120101′,’20130101')为按这几个值来分区。 这里需要说明的一下,在Values中,’20100101’、’20110101’、’20120101’、’20130101’,这些都是分区的条件。“ 20100101”代表2010年1月1日,在小于这个值的记录,都会分成一个小表中,如表1;而小于或等于’20100101’并且小于’20110101’的值,会放在另一个表中,如表2。以此类推,到最后,所有大小或等于’20130101’的值会放在另一个表中,如表5。 也许有人会问,为什么值“ 20100101”会放在表2中,而不是表1中呢?这是由AS RANGE RIGHT中的RIGHT所决定的,RIGHT的意思是将等于这个值的数据放在右边的那个表里,也就是表2中。如果您的SQL语句中使用的是Left而不是RIGHT,那么就会放在左边的表中,也就是表1中。 第四、创建一个分区方案。分区方案的作用是将分区函数生成的分区映射到文件组中去。分区函数的作用是告诉SQL Server,如何将数据进行分区,而分区方案的作用则是告诉SQL Server将已分区的数据放在哪个文件组中。分区方案的代码如下所示: [c-sharp] view plaincopy CREATE PARTITION SCHEME partschSale AS PARTITION partfunSale TO ( Sale2009, Sale2010, Sale2011, Sale2012, Sale2013) 其中: 1、CREATE PARTITION SCHEME意思是创建一个分区方案。 2、partschSale为分区方案名称。 3、AS PARTITION partfunSale说明该分区方案所使用的数据划分条件(也就是所使用的分区函数)为partfunSale。 4、TO后面的内容是指partfunSale分区函数划分出来的数据对应存放的文件组。 […]
View Details第18章:分区
本章讨论MySQL 5.1.中实现的分区。关于分区和分区概念的介绍可以在18.1节,“MySQL中的分区概述”中找到。MySQL 5.1 支持哪几种类型的分区,在18.2节,“分区类型” 中讨论。关于子分区在18.2.5节,“子分区” 中讨论。现有分区表中分区的增加、删除和修改的方法在18.3节,“分区管理” 中介绍。 和分区表一同使用的表维护命令在18.3.3节,“分区维护” 中介绍。 请注意:MySQL 5.1中的分区实现仍然很新(pre-alpha品质),此时还不是可生产的(not production-ready)。 同样,许多也适用于本章:在这里描述的一些功能还没有实际上实现(分区维护和重新分区命令),其他的可能还没有完全如所描述的那样实现(例如, 用于分区的数据目录(DATA DIRECTORY)和索引目录(INDEX DIRECTORY)选项受到Bug #13520) 不利的影响). 我们已经设法在本章中标出这些差异。在提出缺陷报告前,我们鼓励参考下面的一些资源: MySQL 分区论坛这是一个为对MySQL分区技术感兴趣或用MySQL分区技术做试验提供的官方讨论论坛。来自MySQL 的开发者和其他的人,会在上面发表和更新有关的材料。它由分区开发和文献团队的成员负责监控。 分区缺陷报告已经归档在缺陷系统中的、所有分区缺陷的一个列表,而无论这些缺陷的年限、严重性或当前的状态如何。根据许多规则可以对这些缺陷进行筛选,或者可以从MySQL缺陷系统主页开始,然后查找你特别感兴趣的缺陷。 Mikael Ronström’s BlogMySQL分区体系结构和领先的开发者Mikael Ronström 经常在这里贴关于他研究MySQL 分区和MySQL簇的文章。 PlanetMySQL一个MySQL 新闻网站,它以汇集MySQL相关的网誌为特点,那些使用我的MySQL的人应该对此有兴趣。我们鼓励查看那些研究MySQL分区的人的网誌链接,或者把你自己的网誌加到这些新闻报道中。 MySQL 5.1的二进制版本目前还不可用;但是,可以从BitKeeper知识库中获得源码。要激活分区,需要使用--with-分区选项编译服务器。关于建立MySQL 的更多信息,请参见2.8节,“使用源码分发版安装MySQL”。如果在编译一个激活分区的MySQL 5.1创建中碰到问题,可以在MySQL分区论坛中查找解决办法,如果在论坛中已经贴出的文章中没有找到问题的解决办法,可以在上面寻找帮助。 18.1. MySQL中的分区概述 本节提供了关于MySQL 5.1.分区在概念上的概述。 SQL标准在数据存储的物理方面没有提供太多的指南。SQL语言的使用独立于它所使用的任何数据结构或图表、表、行或列下的介质。但是,大部分高级数据库管理系统已经开发了一些根据文件系统、硬件或者这两者来确定将要用于存储特定数据块物理位置的方法。在MySQL中,InnoDB存储引擎长期支持表空间的概念,并且MySQL服务器甚至在分区引入之前,就能配置为存储不同的数据库使用不同的物理路径(关于如何配置的解释,请参见7.6.1节,“使用符号链接”)。 分区又把这个概念推进了一步,它允许根据可以设置为任意大小的规则,跨文件系统分配单个表的多个部分。实际上,表的不同部分在不同的位置被存储为单独的表。用户所选择的、实现数据分割的规则被称为分区函数,这在MySQL中它可以是模数,或者是简单的匹配一个连续的数值区间或数值列表,或者是一个内部HASH函数,或一个线性HASH函数。函数根据用户指定的分区类型来选择,把用户提供的表达式的值作为参数。该表达式可以是一个整数列值,或一个作用在一个或多个列值上并返回一个整数的函数。这个表达式的值传递给分区函数,分区函数返回一个表示那个特定记录应该保存在哪个分区的序号。这个函数不能是常数,也不能是任意数。它不能包含任何查询,但是实际上可以使用MySQL 中任何可用的SQL表达式,只要该表达式返回一个小于MAXVALUE(最大可能的正整数)的正数值。分区函数的例子可以在本章后面关于分区类型的讨论中找到 (请参见18.2节,“分区类型” ),也可在13.1.5节,“CREATE TABLE语法”的分区语法描述中找到。 当二进制码变成可用时(也就是说,5.1 -max 二进制码将通过--with-partition 建立),分区支持就将包含在MySQL 5.1的-max 版本中。如果MySQL二进制码是使用分区支持建立的,那么激活它不需要任何其他的东西 (例如,在my.cnf 文件中,不需要特殊的条目)。可以通过使用SHOW VARIABLES命令来确定MySQL是否支持分区,例如:
|
1 2 3 4 5 6 7 |
mysql> SHOW VARIABLES LIKE '%partition%'; +-----------------------+-------+ | Variable_name | Value | +-----------------------+-------+ | have_partition_engine | YES | +-----------------------+-------+ 1 row in set (0.00 sec) |
在如上列出的一个正确的SHOW VARIABLES 命令所产生的输出中,如果没有看到变量have_partition_engine的值为YES,那么MySQL的版本就不支持分区。(注意:在显示任何有关分区支持信息的命令SHOW ENGINES的输出中,不会给出任何信息;必须使用SHOW VARIABLES命令来做出这个判断)。 对于创建了分区的表,可以使用你的MySQL 服务器所支持的任何存储引擎;MySQL 分区引擎在一个单独的层中运行,并且可以和任何这样的层进行相互作用。在MySQL 5.1版中,同一个分区表的所有分区必须使用同一个存储引擎;例如,不能对一个分区使用MyISAM,而对另一个使用InnoDB。但是,这并不妨碍在同一个 MySQL 服务器中,甚至在同一个数据库中,对于不同的分区表使用不同的存储引擎。 要为某个分区表配置一个专门的存储引擎,必须且只能使用[STORAGE] ENGINE 选项,这如同为非分区表配置存储引擎一样。但是,必须记住[STORAGE] ENGINE(和其他的表选项)必须列在用在CREATE TABLE语句中的其他任何分区选项之前。下面的例子给出了怎样创建一个通过HASH分成6个分区、使用InnoDB存储引擎的表:
|
1 2 3 4 |
CREATE TABLE ti (id INT, amount DECIMAL(7,2), tr_date DATE) ENGINE=INNODB PARTITION BY HASH(MONTH(tr_date)) PARTITIONS 6; |
(注释:每个PARTITION 子句可以包含一个 [STORAGE] ENGINE 选项,但是在MySQL 5.1版本中,这没有作用)。 创建分区的临时表也是可能的;但是,这种表的生命周期只有当前MySQL 的会话的时间那么长。对于非分区的临时表,这也是一样的。 注释:分区适用于一个表的所有数据和索引;不能只对数据分区而不对索引分区,反之亦然,同时也不能只对表的一部分进行分区。 可以通过使用用来创建分区表的CREATE TABLE语句的PARTITION子句的DATA DIRECTORY(数据路径)和INDEX DIRECTORY(索引路径)选项,为每个分区的数据和索引指定特定的路径。此外,MAX_ROWS和MIN_ROWS选项可以用来设定最大和最小的行数,它们可以各自保存在每个分区里。关于这些选项的更多信息,请参见18.3节,“分区管理”。注释:这个特殊的功能由于Bug #13250的原因,目前还不能实用。在第一个5.1二进制版本投入使用时,我们应该已经把这个问题解决了。 分区的一些优点包括: · 与单个磁盘或文件系统分区相比,可以存储更多的数据。 · 对于那些已经失去保存意义的数据,通常可以通过删除与那些数据有关的分区,很容易地删除那些数据。相反地,在某些情况下,添加新数据的过程又可以通过为那些新数据专门增加一个新的分区,来很方便地实现。 通常和分区有关的其他优点包括下面列出的这些。MySQL 分区中的这些功能目前还没有实现,但是在我们的优先级列表中,具有高的优先级;我们希望在5.1的生产版本中,能包括这些功能。 · 一些查询可以得到极大的优化,这主要是借助于满足一个给定WHERE 语句的数据可以只保存在一个或多个分区内,这样在查找时就不用查找其他剩余的分区。因为分区可以在创建了分区表后进行修改,所以在第一次配置分区方案时还不曾这么做时,可以重新组织数据,来提高那些常用查询的效率。 · 涉及到例如SUM() 和 COUNT()这样聚合函数的查询,可以很容易地进行并行处理。这种查询的一个简单例子如 “SELECT salesperson_id, COUNT(orders) as order_total FROM sales GROUP BY salesperson_id;”。通过“并行”, 这意味着该查询可以在每个分区上同时进行,最终结果只需通过总计所有分区得到的结果。 · 通过跨多个磁盘来分散数据查询,来获得更大的查询吞吐量。 要经常检查本页和本章,因为它将随MySQL 5.1后续的分区进展而更新。 18.2. 分区类型 18.2.1. RANGE分区 18.2.2. LIST分区 18.2.3. HASH分区 18.2.4. KEY分区 18.2.5. 子分区 18.2.6. MySQL分区处理NULL值的方式 本节讨论在MySQL 5.1中可用的分区类型。这些类型包括: · RANGE 分区:基于属于一个给定连续区间的列值,把多行分配给分区。参见18.2.1节,“RANGE分区”。 […]
View DetailsMYSQL表分区
范围分区: CREATE TABLE BIGTABLE ( ID INT, SNPTIME DATETIME NOT NULL, VALUE VARCHAR(20), PRIMARY KEY (SNPTIME, ID) ) ENGINE=InnoDB partition by range (TO_DAYS(SNPTIME)) ( PARTITION p1 VALUES LESS THAN (to_days('2009-1-31')), PARTITION p2 VALUES LESS THAN (to_days('2009-2-28')), PARTITION p3 VALUES LESS THAN (to_days('2008-3-31')), PARTITION p4 VALUES LESS THAN (to_days('2008-4-30')), PARTITION p5 VALUES LESS THAN (to_days('2008-5-31')), PARTITION p6 VALUES LESS THAN (to_days('2008-6-30')), PARTITION p7 VALUES LESS THAN (to_days('2008-7-31')), PARTITION p8 VALUES LESS THAN (to_days('2008-8-31')), PARTITION p9 VALUES LESS THAN (to_days('2008-9-30')), PARTITION p10 VALUES LESS THAN (to_days('2008-10-31')), PARTITION p11 VALUES LESS THAN (to_days('2008-11-30')), PARTITION p12 VALUES LESS THAN (to_days('2008-12-31')), PARTITION p13 VALUES LESS THAN MAXVALUE ) ; 注意一点:一定要有主键,并且主键要包括分区键。 但是,如果必须要分区,而分区中的分区键不想使用(业务不允许)主键的时候,可以采用两步走的办法。 1、建立表,带有主键。 2、删除主键,建立独立索引。 这样在插入数据的时候还是能够按部就班地进入各自所属的分区表。 给已存在的表加分区 ALTER TABLE SNP_SWITCH partition by RANGE (TO_DAYS(RPTTIME)) (PARTITION P1210 VALUES LESS THAN (735172) ENGINE = MYISAM, PARTITION P1211 VALUES LESS THAN (735202) ENGINE = MYISAM, […]
View Details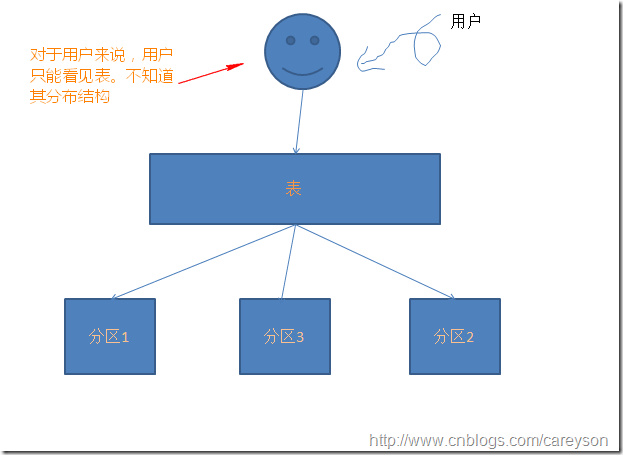
理解SQL SERVER中的分区表
简介 分区表是在SQL SERVER2005之后的版本引入的特性。这个特性允许把逻辑上的一个表在物理上分为很多部分。而对于SQL SERVER2005之前版本,所谓的分区表仅仅是分布式视图,也就是多个表做union操作. 分区表在逻辑上是一个表,而物理上是多个表.这意味着从用户的角度来看,分区表和普通表是一样的。这个概念可以简单如下图所示: 而对于SQL SERVER2005之前的版本,是没有分区这个概念的,所谓的分区仅仅是分布式视图: 本篇文章所讲述的分区表指的是SQL SERVER2005之后引入的分区表特性. 为什么要对表进行分区 在回答标题的问题之前,需要说明的是,表分区这个特性只有在企业版或者开发版中才有,还有理解表分区的概念还需要理解SQL SERVER中文件和文件组的概念. 对表进行分区在多种场景下都需要被用到.通常来说,使用表分区最主要是用于: 存档,比如将销售记录中1年前的数据分到一个专门存档的服务器中 便于管理,比如把一个大表分成若干个小表,则备份和恢复的时候不再需要备份整个表,可以单独备份分区 提高可用性,当一个分区跪了以后,只有一个分区不可用,其它分区不受影响 提高性能,这个往往是大多数人分区的目的,把一个表分布到不同的硬盘或其他存储介质中,会大大提升查询的速度. 分区表的步骤 分区表的定义大体上分为三个步骤: 定义分区函数 定义分区构架 定义分区表 分区函数,分区构架和分区表的关系如下: 分区表依赖分区构架,而分区构架又依赖分区函数.值得注意的是,分区函数并不属于具体的分区构架和分区表,他们之间的关系仅仅是使用关系. 下面我们通过一个例子来看如何定义一个分区表: 假设我们需要定义的分区表结构如下: 第一列为自增列,orderid为订单id列,SalesDate为订单日期列,也就是我们需要分区的依据. 下面我们按照上面所说的三个步骤来实现分区表. 定义分区函数 分区函数是用于判定数据行该属于哪个分区,通过分区函数中设置边界值来使得根据行中特定列的值来确定其分区,上面例子中,我们可以通过SalesDate的值来判定其不同的分区.假设我们想定义两个边界值(boundaryValue)进行分区,则会生成三个分区,这里我设置边界值分别为2004-01-01和2007-01-01,则前面例子中的表会根据这两个边界值分成三个区: 在MSDN中,定义分区函数的原型如下:
|
1 2 3 4 |
<a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=CREATE&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">CREATE</a> PARTITION <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=FUNCTION&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">FUNCTION</a> partition_function_name ( input_parameter_type ) <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=AS&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">AS</a> RANGE [ <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=LEFT&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">LEFT</a> | <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=RIGHT&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">RIGHT</a> ] <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=FOR&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">FOR</a> <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=VALUES&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">VALUES</a> ( [ boundary_value [ ,...n ] ] ) [ ; ] |
通过定义分区函数的原型,我们看出其中并没有具体涉及具体的表.因为分区函数并不和具体的表相绑定.上面原型中还可以看到Range left和right.这个参数是决定临界值本身应该归于“left”还是“right”: 下面我们根据上面的参数定义分区函数: 通过系统视图,可以看见这个分区函数已经创建成功 定义分区构架 定义完分区函数仅仅是知道了如何将列的值区分到了不同的分区。而每个分区的存储方式,则需要分区构架来定义.使用分区构架需要你对文件和文件组有点了解. 我们先来看MSDN的分区构架的原型:
|
1 2 3 4 |
<a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=CREATE&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">CREATE</a> PARTITION SCHEME partition_scheme_name <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=AS&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">AS</a> PARTITION partition_function_name [ <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=ALL&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">ALL</a> ] <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=TO&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">TO</a> ( { file_group_name | [ <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=PRIMARY&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">PRIMARY</a> ] } [ ,...n ] ) [ ; ] |
从原型来看,分区构架仅仅是依赖分区函数.分区构架中负责分配每个区属于哪个文件组,而分区函数是决定如何在逻辑上分区: 基于之前创建的分区函数,创建分区构架: 定义分区表 接下来就该创建分区表了.表在创建的时候就已经决定是否是分区表了。虽然在很多情况下都是你在发现已经表已经足够大的时候才想到要把表分区,但是分区表只能够在创建的时候指定为分区表。 为刚建立的分区表PartitionedTable加入5万条测试数据,其中SalesDate随机生成,从2001年到2010年随机分布.加入数据后,我们通过如下语句来看结果:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
<a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=select&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">select</a> <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=convert&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">convert</a>(<a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=varchar&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">varchar</a>(50), ps.name) <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=as&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">as</a> partition_scheme, p.partition_number, <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=convert&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">convert</a>(<a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=varchar&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">varchar</a>(10), ds2.name) <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=as&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">as</a> filegroup, <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=convert&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">convert</a>(<a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=varchar&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">varchar</a>(19), isnull(v.<a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=value&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">value</a>, ''), 120) <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=as&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">as</a> range_boundary, str(p.<a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=rows&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">rows</a>, 9) <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=as&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">as</a> <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=rows&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">rows</a> <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=from&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">from</a> sys.indexes i <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=join&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">join</a> sys.partition_schemes ps <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=on&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">on</a> i.data_space_id = ps.data_space_id <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=join&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">join</a> sys.destination_data_spaces dds <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=on&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">on</a> ps.data_space_id = dds.partition_scheme_id <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=join&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">join</a> sys.data_spaces ds2 <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=on&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">on</a> dds.data_space_id = ds2.data_space_id <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=join&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">join</a> sys.partitions p <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=on&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">on</a> dds.destination_id = p.partition_number <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=and&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">and</a> p.object_id = i.object_id <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=and&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">and</a> p.index_id = i.index_id <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=join&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">join</a> sys.partition_functions pf <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=on&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">on</a> ps.function_id = pf.function_id <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=LEFT&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">LEFT</a> <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=JOIN&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">JOIN</a> sys.Partition_Range_values v <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=on&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">on</a> pf.function_id = v.function_id <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=and&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">and</a> v.boundary_id = p.partition_number - pf.boundary_value_on_right <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=WHERE&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">WHERE</a> i.object_id = object_id('PartitionedTable') <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=and&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">and</a> i.index_id <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=in&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">in</a> (0, 1) <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=order&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">order</a> <a href="http://search.microsoft.com/default.asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=by&IntlSearch=&boolean=PHRASE&ig=01&i=09&i=99">by</a> p.partition_number |
可以看到我们分区的数据分布: 分区表的分割 分区表的分割。相当于新建一个分区,将原有的分区需要分割的内容插入新的分区,然后删除老的分区的内容,概念如下图: 假设我新加入一个分割点:2009-01-01,则概念如下: 通过上图我们可以看出,如果分割时,被分割的分区3内有内容需要分割到分区4,则这些数据需要被复制到分区4,并删除分区3上对应数据。 这种操作非常非常消耗IO,并且在分割的过程中锁定分区三内的内容,造成分区三的内容不可用。不仅仅如此,这个操作生成的日志内容会是被转移数据的4倍! 所以我们如果不想因为这种操作给客户带来麻烦而被老板爆菊的话…最好还是把分割点建立在未来(也就是预先建立分割点),比如2012-01-01。则分区3内的内容不受任何影响。在以后2012的数据加入时,自动插入到分区4. 分割现有的分区需要两个步骤: 1.首先告诉SQL SERVER新建立的分区放到哪个文件组 2.建立新的分割点 可以通过如下语句来完成: 如果我们的分割构架在定义的时候已经指定了NEXT USED,则直接添加分割点即可。 通过文中前面查看分区的长语句..再来看: 新的分区已经加入! […]
View Details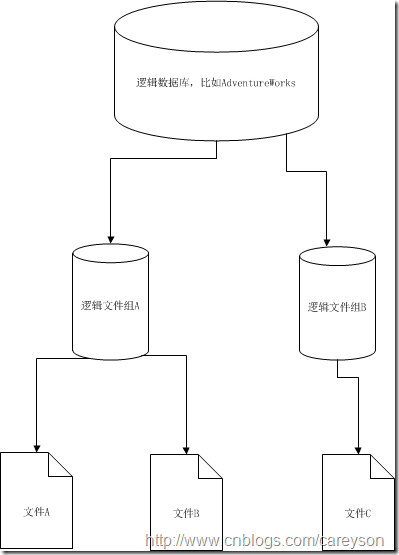
SQL Server中数据库文件的存放方式,文件和文件组
写在前面:上次我关于索引的文章有几个园友发站内信问我如何将索引和表存储在不同的硬盘上。我觉的需要专门写一篇文章来讲述一下文件和文件组应该更容易理解. 简介 在SQL SERVER中,数据库在硬盘上的存储方式和普通文件在Windows中的存储方式没有什么不同,仅仅是几个文件而已.SQL SERVER通过管理逻辑上的文件组的方式来管理文件.理解文件和文件组的概念对于更好的配置数据库来说是最基本的知识。 理解文件和文件组 在SQL SERVER中,通过文件组这个逻辑对象对存放数据的文件进行管理. 先来看一张图: 我们看到的逻辑数据库由一个或者多个文件组构成 而文件组管理着磁盘上的文件.而文件中存放着SQL SERVER的实际数据. 为什么通过文件组来管理文件 对于用户角度来说,需对创建的对象指定存储的文件组只有三种数据对象:表,索引和大对象(LOB) 使用文件组可以隔离用户和文件,使得用户针对文件组来建立表和索引,而不是实际磁盘中的文件。当文件移动或修改时,由于用户建立的表和索引是建立在文件组上的,并不依赖具体文件,这大大加强了可管理性. 还有一点是,使用文件组来管理文件可以使得同一文件组内的不同文件分布在不同的硬盘中,极大的提高了IO性能. SQL SERVER会根据每个文件设置的初始大小和增长量会自动分配新加入的空间,假设在同一文件组中的文件A设置的大小为文件B的两倍,新增一个数据占用三页(Page),则按比例将2页分配到文件A中,1页分配到文件B中. 文件的分类 首要文件:这个文件是必须有的,而且只能有一个。这个文件额外存放了其他文件的位置等信息.扩展名为.mdf 次要文件:可以建任意多个,用于不同目的存放.扩展名为.ndf 日志文件:存放日志,扩展名为.ldf 在SQL SERVER 2008之后,还新增了文件流数据文件和全文索引文件. 上述几种文件名扩展名可以随意修改,但是我推荐使用默认的扩展名。 我们可以通过如下语句查看数据库中的文件情况: 还有一点要注意的是,如果一个表是存在物理上的多个文件中时,则表的数据页的组织为N(N为具体的几个文件)个B树.而不是一个对象为一个B树. 创建和使用文件组 创建文件或是文件组可以通过在SSMS中或者使用T-SQL语句进行。对于一个数据库来说,既可以在创建时增加文件和文件组,也可以向现有的数据库添加文件和文件组.这几种方式大同小异.下面来看一下通过SSMS向现有数据库添加文件和文件组. 首先创建文件组: 文件组创建好后就可以向现有文件组中添加文件了: 下面我们就可以通过语句将创建的表或者索引加入到新的文件组中了: 使用多个文件的优点与缺点 通常情况下,小型的数据库并不需要创建多个文件来分布数据。但是随着数据的增长,使用单个文件的弊端就开始显现。 首先:使用多个文件分布数据到多个硬盘中可以极大的提高IO性能. 其次:多个文件对于数据略多的数据库来说,备份和恢复都会轻松很多.我碰见过遇到一个150G的数据库,手头却没有这么大的存储设备… 但是,在数据库的世界中,每一项好处往往伴随着一个坏处: 显而易见,使用多文件需要占用更多的磁盘空间。这是因为每个文件中都有自己的一套B树组织方式,和自己的增长空间。当然了,还有一套自己的碎片-.-但是在大多数情况下,多占点磁盘空间带来的弊端要远远小于多文件带来的好处. 总结 本文对SQL SERVER中文件和文件组的概念进行了简单阐述,并在文中讲述了文件和文件组的配置方式。按照业务组织好不同的文件组来分布不同的文件,使得性能的提升,对于你半夜少接几个电话的帮助是灰常大滴:-) from:http://www.cnblogs.com/CareySon/archive/2011/12/26/2301597.html
View Details