Category Archives: Programming Language
恕我直言,我怀疑你没怎么用过枚举
我们是否一样? 估计很多小伙伴(也包括我自己)都有这种情况,在自学Java语言看书时,关于枚举enum这一块的知识点可能都有点 “轻敌” ,觉得这块内容非常简单,一带而过,而且在实际写代码过程中也不注意运用。 是的,我也是这样!直到有一天我提的代码审核没过,被技术总监一顿批,我才重新拿起了《Java编程思想》,把枚举这块的知识点重新又审视了一遍。 为什么需要枚举 常量定义它不香吗?为啥非得用枚举? 举个栗子,就以B站上传视频为例,视频一般有三个状态:草稿、审核和发布,我们可以将其定义为静态常量:
|
1 2 3 4 5 6 7 8 |
public class VideoStatus { public static final int Draft = 1; //草稿 public static final int Review = 2; //审核 public static final int Published = 3; //发布 } |
对于这种单值类型的静态常量定义,本身也没错,主要是在使用的地方没有一个明确性的约束而已,比如:
|
1 2 3 4 5 |
void judgeVideoStatus( int status ) { ... } |
比如这里的 judgeVideoStatus 函数的本意是传入 VideoStatus 的三种静态常量之一,但由于没有类型上的约束,因此传入任意一个int值都是可以的,编译器也不会提出任何警告。 但是在枚举类型出现之后,上面这种情况就可以用枚举严谨地去约束,比如用枚举去定义视频状态就非常简洁了:
|
1 2 3 |
public enum VideoStatus { Draft, Review, Published } |
而且主要是在用枚举的地方会有更强的类型约束:
|
1 2 3 4 5 6 |
// 入参就有明确类型约束 void judgeVideoStatus( VideoStatus status ) { ... } |
这样在使用 judgeVideoStatus 函数时,入参类型就会受到明确的类型约束,一旦传入无效值,编译器就会帮我们检查,从而规避潜在问题。 除此之外,枚举在扩展性方面比普常量更方便、也更优雅。 重新系统认识一下枚举 还是拿前文《答应我,别再if/else走天下了可以吗》中的那个例子来说:比如,在后台管理系统中,肯定有用户角色一说,而且角色一般都是固定的,适合定义成一个枚举:
|
1 2 3 4 5 6 7 8 |
public enum UserRole { ROLE_ROOT_ADMIN, // 系统管理员 ROLE_ORDER_ADMIN, // 订单管理员 ROLE_NORMAL // 普通用户 } |
接下来我们就用这个UserRole为例来说明枚举的所有基本用法:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
UserRole role1 = UserRole.ROLE_ROOT_ADMIN; UserRole role2 = UserRole.ROLE_ORDER_ADMIN; UserRole role3 = UserRole.ROLE_NORMAL; // values()方法:返回所有枚举常量的数组集合 for ( UserRole role : UserRole.values() ) { System.out.println(role); } // 打印: // ROLE_ROOT_ADMIN // ROLE_ORDER_ADMIN // ROLE_NORMAL // ordinal()方法:返回枚举常量的序数,注意从0开始 System.out.println( role1.ordinal() ); // 打印0 System.out.println( role2.ordinal() ); // 打印1 System.out.println( role3.ordinal() ); // 打印2 // compareTo()方法:枚举常量间的比较 System.out.println( role1.compareTo(role2) ); //打印-1 System.out.println( role2.compareTo(role3) ); //打印-2 System.out.println( role1.compareTo(role3) ); //打印-2 // name()方法:获得枚举常量的名称 System.out.println( role1.name() ); // 打印ROLE_ROOT_ADMIN System.out.println( role2.name() ); // 打印ROLE_ORDER_ADMIN System.out.println( role3.name() ); // 打印ROLE_NORMAL // valueOf()方法:返回指定名称的枚举常量 System.out.println( UserRole.valueOf( "ROLE_ROOT_ADMIN" ) ); System.out.println( UserRole.valueOf( "ROLE_ORDER_ADMIN" ) ); System.out.println( UserRole.valueOf( "ROLE_NORMAL" ) ); |
除此之外,枚举还可以用于switch语句中,而且意义更加明确:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
UserRole userRole = UserRole.ROLE_ORDER_ADMIN; switch (userRole) { case ROLE_ROOT_ADMIN: // 比如此处的意义就非常清晰了,比1,2,3这种数字好! System.out.println("这是系统管理员角色"); break; case ROLE_ORDER_ADMIN: System.out.println("这是订单管理员角色"); break; case ROLE_NORMAL: System.out.println("这是普通用户角色"); break; } |
自定义扩充枚举 上面展示的枚举例子非常简单,仅仅是单值的情形,而实际项目中用枚举往往是多值用法。 比如,我想扩充一下上面的UserRole枚举,在里面加入 角色名 — 角色编码 的对应关系,这也是实际项目中常用的用法。 这时候我们可以在枚举里自定义各种属性、构造函数、甚至各种方法:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
public enum UserRole { ROLE_ROOT_ADMIN( "系统管理员", 000000 ), ROLE_ORDER_ADMIN( "订单管理员", 100000 ), ROLE_NORMAL( "普通用户", 200000 ), ; // 以下为自定义属性 private final String roleName; //角色名称 private final Integer roleCode; //角色编码 // 以下为自定义构造函数 UserRole( String roleName, Integer roleCode ) { this.roleName = roleName; this.roleCode = roleCode; } // 以下为自定义方法 public String getRoleName() { return this.roleName; } public Integer getRoleCode() { return this.roleCode; } public static Integer getRoleCodeByRoleName( String roleName ) { for( UserRole enums : UserRole.values() ) { if( enums.getRoleName().equals( roleName ) ) { return enums.getRoleCode(); } } return null; } } |
从上述代码可知,在enum枚举类中完全可以像在普通Class里一样声明属性、构造函数以及成员方法。 枚举 + 接口 = ? 比如在我的前文《答应我,别再if/else走天下了可以吗》中讲烦人的if/else消除时,就讲过如何通过让枚举去实现接口来方便的完成。 这地方不妨再回顾一遍: 什么角色能干什么事,这很明显有一个对应关系,所以我们首先定义一个公用的接口RoleOperation,表示不同角色所能做的操作:
|
1 2 3 |
public interface RoleOperation { String op(); // 表示某个角色可以做哪些op操作 } |
接下来我们将不同角色的情况全部交由枚举类来做,定义一个枚举类RoleEnum,并让它去实现RoleOperation接口:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
public enum RoleEnum implements RoleOperation { // 系统管理员(有A操作权限) ROLE_ROOT_ADMIN { @Override public String op() { return "ROLE_ROOT_ADMIN:" + " has AAA permission"; } }, // 订单管理员(有B操作权限) ROLE_ORDER_ADMIN { @Override public String op() { return "ROLE_ORDER_ADMIN:" + " has BBB permission"; } }, // 普通用户(有C操作权限) ROLE_NORMAL { @Override public String op() { return "ROLE_NORMAL:" + " has CCC permission"; } }; } |
这样,在调用处就变得异常简单了,一行代码就行了,根本不需要什么if/else:
|
1 2 3 4 5 6 |
public class JudgeRole { public String judge( String roleName ) { // 一行代码搞定!之前的if/else灰飞烟灭 return RoleEnum.valueOf(roleName).op(); } } |
而且这样一来,以后假如我想扩充条件,只需要去枚举类中加代码即可,而不用改任何老代码,非常符合开闭原则! 枚举与设计模式 什么?枚举还能实现设计模式? 是的!不仅能而且还能实现好几种! 1、单例模式
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
public class Singleton { // 构造函数私有化,避免外部创建实例 private Singleton() { } //定义一个内部枚举 public enum SingletonEnum{ SEED; // 唯一一个枚举对象,我们称它为“种子选手”! private Singleton singleton; SingletonEnum(){ singleton = new Singleton(); //真正的对象创建隐蔽在此! } public Singleton getInstnce(){ return singleton; } } // 故意外露的对象获取方法,也是外面获取实例的唯一入口 public static Singleton getInstance(){ return SingletonEnum.SEED.getInstnce(); // 通过枚举的种子选手来完成 } } |
2、策略模式 这个也比较好举例,比如用枚举就可以写出一个基于策略模式的加减乘除计算器
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
public class Test { public enum Calculator { ADDITION { public Double execute( Double x, Double y ) { return x + y; // 加法 } }, SUBTRACTION { public Double execute( Double x, Double y ) { return x - y; // 减法 } }, MULTIPLICATION { public Double execute( Double x, Double y ) { return x * y; // 乘法 } }, DIVISION { public Double execute( Double x, Double y ) { return x/y; // 除法 } }; public abstract Double execute(Double x, Double y); } public static void main(String[] args) { System.out.println( Calculator.ADDITION.execute( 4.0, 2.0 ) ); // 打印 6.0 System.out.println( Calculator.SUBTRACTION.execute( 4.0, 2.0 ) ); // 打印 2.0 System.out.println( Calculator.MULTIPLICATION.execute( 4.0, 2.0 ) ); // 打印 8.0 System.out.println( Calculator.DIVISION.execute( 4.0, 2.0 ) ); // 打印 2.0 } } |
专门用于枚举的集合类 我们平常一般习惯于使用诸如:HashMap 和 HashSet等集合来盛放元素,而对于枚举,有它专门的集合类:EnumSet和EnumMap 1、EnumSet EnumSet 是专门为盛放枚举类型所设计的 Set 类型。 还是举例来说,就以文中开头定义的角色枚举为例:
|
1 2 3 4 5 6 7 8 |
public enum UserRole { ROLE_ROOT_ADMIN, // 系统管理员 ROLE_ORDER_ADMIN, // 订单管理员 ROLE_NORMAL // 普通用户 } |
比如系统里来了一批人,我们需要查看他是不是某个角色中的一个:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
// 定义一个管理员角色的专属集合 EnumSet<UserRole> userRolesForAdmin = EnumSet.of( UserRole.ROLE_ROOT_ADMIN, UserRole.ROLE_ORDER_ADMIN ); // 判断某个进来的用户是不是管理员 Boolean isAdmin( User user ) { if( userRoles.contains( user.getUserRole() ) ) return true; return false; } |
2、EnumMap 同样,EnumMap 则是用来专门盛放枚举类型为key的 Map 类型。 比如,系统里来了一批人,我们需要统计不同的角色到底有多少人这种的话:
|
1 2 3 4 5 6 7 8 9 10 |
Map<UserRole,Integer> userStatisticMap = new EnumMap<>(UserRole.class); for ( User user : userList ) { Integer num = userStatisticMap.get( user.getUserRole() ); if( null != num ) { userStatisticMap.put( user.getUserRole(), num+1 ); } else { userStatisticMap.put( user.getUserRole(), 1 ); } } |
用EnumMap可以说非常方便了。 总 结 小小的枚举就玩出这么多的花样,不过好在探索和总结的过程还挺有意思的,也复习了很多知识,慢慢来吧。 from:https://my.oschina.net/hansonwang99/blog/3196498
View Details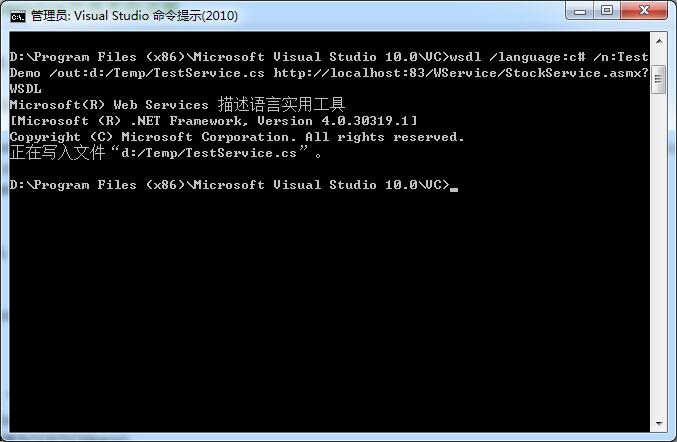
解析利用wsdl.exe生成webservice代理类的详解
利用wsdl.exe生成webservice代理类: 根据提供的wsdl生成webservice代理类 1、开始->程序->Visual Studio 2010 命令提示 2、输入如下红色标记部分 D:/Program Files/Microsoft Visual Studio 8/VC>wsdl /language:c# /n:TestDemo /out:d:/Temp/TestService.cs D:/Temp/TestService.wsdl 在d:/Temp下就会产生一个TestService.cs 文件 注意:D:/Temp/TestService.wsdl 是wsdl路径,可以是url路径:http://localhost/Temp/Test.asmx?wsdl wsdl参数说明: wsdl.exe <选项> <URL 或路径> <URL 或路径> … – 选项 – <URL 或路径> – 指向 WSDL 协定、XSD 架构或 .discomap 文档的 URL 或路径。 /nologo 取消显示版权标志。 /language:<language> 用于生成的代理类的语言。请从“CS”、“VB”、“JS”、“VJS”、 “CPP”中选择,或者为实现 System.CodeDom.Compiler.CodeDomProvider 的类提供一个完全限定的名称。默认语言为“CS”(CSharp)。 缩写形式为“/l:”。 /sharetypes 打开类型共享功能。此功能针对不同服务之间共享 的相同类型(命名空间、名称和网络签名必须相同) 创建一个具有单一类型定义的代码文件。 请使用 http:// URLs 作为命令行参数来引用 服务,或为本地文件创建一个 discomap 文档。 /verbose 指定 /sharetypes 开关时显示额外信息。 缩写形式为“/v”。 /fields 生成字段而非属性。缩写形式为“/f”。 /order 为粒子成员生成显式顺序标识符。 /enableDataBinding 在所有生成的类型上实现 INotifyPropertyChanged 接口, 以启用数据绑定。缩写形式为“/edb”。 /namespace:<namespace> 生成的代理或模板的命名空间。默认命名空间 为全局命名空间。缩写形式为“/n:”。 /out:<fileName|directoryPath> 生成的代理代码的文件名或目录路径。默认文件名是从 […]
View DetailsGDI+中发生一般性错误的解决办法
前言: 今天在做二维码需求的时候,代码运行的时候报的:GDI+中发生一般性错误的解决办法这个错误,这个错误也是第一次遇到,不知道怎么解决,以为是生成二维码的代码错了。最后通过对代码的检查以及查资料进行解决了,原来是少了一个保存二维码图片的文件夹。 这个错误也常在在后台生成图片以及验证码中出现。基本上都是采用下面的几种解决办法 代码中没有物理的文件夹的解决办法: 在调用 Save 方法之前,先判断保存图片的文件夹是否存在,若不存在,则创建,当然也可以手动添加一个
|
1 2 3 4 |
//dirpath:文件路径 if (!Directory.Exists(dirpath)){ Directory.CreateDirectory(dirpath) } |
有保存图片的物理文件夹的解决办法: 给相应的文件夹赋予 NETWORK SERVICE 帐户以写权限 保存的文件已存在并因某种原因被锁定的解决办法: 重启IIS,解除锁定。并在代码中使用 using 语句,确保释放 Image 对象所使用的所有资源 ———————————————— 版权声明:本文为CSDN博主「小灰灰城堡」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/GreyCastle/article/details/88411697
View Detailsmac 重启php-fpm
查看php-fpm端口是否在被php-fpm使用
|
1 |
sudo lsof -i:9000 |
一般修改 php.ini 文件后经常需要重启php-fpm
|
1 |
sudo killall php-fpm // 关闭 |
再输入 sudo lsof -i:9000 就会发现php-fpm没有打印对应端口
|
1 |
sudo php-fpm // 重启 |
from:https://www.cnblogs.com/cap-rq/p/11460282.html
View Details浅谈php中使用websocket
在PHP中,开发者需要考虑的东西比较多,从socket的连接、建立、绑定、监听等都需要开发者自己去操作完成,对于初学者来说,难度方面也挺大的,所以本文的思路如下:
1、socket协议的简介
2、介绍client与server之间的连接原理
3、PHP中建立socket的过程讲解
4、用一个聊天室作为实例详细讲解在PHP中如何使用socket
在asp.net 中应用POST传递和接收XML文件以及参数.(转)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 |
使用POST方式可以向别的页面发送请求,并获取返回结果。 可以从一个页面发送POST到另一个页面,也可以在winform工程中使用HTTPRequest发送POST到一个页面。我们拿ASP.NET的aspx页面做个例子,从一个aspx页面POST.aspx ,发送请求到Receive.aspx页面。 1.首先,建立工程,添加两个页面,Post.aspx和Receive.aspx 在post页面中放一个BUTTON,在它的click方法中我们可以写这样的一段代码: private void Button1_Click(object sender, System.EventArgs e) { //XML文件路径 string xmlFileName = Server.MapPath("File/Frame.xml"); HttpWebRequest req = null; try { //设置要POST到的页面URL,这里中文参数或者有特殊符号的,要进行编码. string url = "http://localhost/Receive.aspx" + "?DwgFileName="+HttpUtility.UrlEncode("NNN+10111452505252706++2.bmp,NNN+10111457375757706++13.bmp")+ "&PltFileName="+HttpUtility.UrlEncode("NNN+10110934363434706++主页.JPG"); //创建一个HttpWebRequest对象 req = (HttpWebRequest) HttpWebRequest.Create(url); //设置它提交数据的方式post req.Method = "POST"; //设置 Content-type HTTP 标头的值 req.ContentType = "text/xml";// "application/x-www-form-urlencoded;charset=gb2312"; using (StreamWriter requestWriter = new StreamWriter(req.GetRequestStream())) { //定义一个StreamReader对象,用于读取xml文件的内容 StreamReader reader = new StreamReader(xmlFileName); string ret = reader.ReadToEnd(); reader.Close(); requestWriter.WriteLine(ret);//将读取的内容写入到RequestStream中。 } Response.Write("发出去了"); } catch(Exception ex) { throw ex; } finally{ } } 2. 再来看一下接收页面Receive.aspx 在Receive.aspx页面的PageLoad方法中进行接收POST过来的请求。 private void Page_Load(object sender, System.EventArgs e) { if(Request.RequestType == "POST") { //Response.ContentType = "text/xml"; string pltFileName = Request.QueryString["PltFileName"];//PLT文件名 string dwgFileName = Request.QueryString["DwgFileName"];//dwg文件名列表 :111.dwg,222.dwg,333.dwg..... //接收并读取POST过来的XML文件流 StreamReader reader = new StreamReader(Request.InputStream); String xmlData = reader.ReadToEnd(); try { //声明一个XMLDoc文档对象,LOAD()xml字符串 XmlDocument doc = new XmlDocument(); doc.LoadXml(xmlData); //得到XML文档根节点 XmlElement root = doc.DocumentElement; .....进行自己对XML的操作。。。 } |
from:https://www.cnblogs.com/shenyixin/p/4630698.html
View Details
C#字符串查找速度优化--StringComparison.Ordinal
本文一些资料参考自https://blog.csdn.net/sinat_27657511/article/details/52275327,感谢这位博主 下面就来谈下StringComparison。 public enum StringComparison { CurrentCulture, CurrentCultureIgnoreCase, InvariantCulture, InvariantCultureIgnoreCase, Ordinal, OrdinalIgnoreCase } CurrentCulture 使用区域敏感排序规则和当前区域比较字符串。 CurrentCultureIgnoreCase 使用区域敏感排序规则、当前区域来比较字符串,同时忽略被比较字符串的大小写。 InvariantCulture 使用区域敏感排序规则和固定区域比较字符串。 InvariantCultureIgnoreCase 使用区域敏感排序规则、固定区域来比较字符串,同时忽略被比较字符串的大小写。 Ordinal 使用序号排序规则比较字符串。 OrdinalIgnoreCase 使用序号排序规则并忽略被比较字符串的大小写,对字符串进行比较。 StringComparison.Ordinal 在进行调用String.Compare(string1,string2,StringComparison.Ordinal)的时候是进行非语言(non-linguistic)上的比较,API运行时将会对两个字符串进行byte级别的比较,因此这种比较是比较严格和准确的,并且在性能上也很好,一般通过StringComparison.Ordinal来进行比较比使用String.Compare(string1,string2)来比较要快10倍左右.(可以写一个简单的小程序验证,这个挺让我惊讶,因为平时使用String.Compare从来就没想过那么多).StringComparison.OrdinalIgnoreCase就是忽略大小写的比较,同样是byte级别的比较.性能稍弱于StringComparison.Ordinal. string类型中的Contains函数默认使用了Ordinal方式,所以速度会很快 其他的方法例如IndexOf,CompareTo等都默认使用了CurrentCulture方式,所以速度会相对比较满,可以调用的时候显示声明StringComparison的方式,速度会快很多,下面是测试: 在约1500个字符中查找一个字符‘q’,位于该序列的结尾处。 使用Ordinal方式的速度: 不使用Ordinal方式: 对比发现速度确实快了很多,在文本约庞大时候,效果会更加的明显。 from:https://blog.csdn.net/w199753/article/details/83421165
View Detailsc# ado.net连接mysql报错“Reading from the stream has failed”
“Authentication to host ‘localhost’ for user ‘root’ using method ‘mysql_native_password’ failed with message: Reading from the stream has failed” 昨天晚上,因为某些原因,几天没打开的C#.net winform项目调试时突然启动失败,冒出来这个提示。 说实话,因为没抓着重点,我昨晚基本上就浪费了,虽然我猜到了是连接超时之类的原因,可一直没明白究竟是我弄错了什么,才会连接不上MySQL数据库 今天再找原因的时候,就Get到重点了:“Reading from the stream has failed”,这个是数据库返回的报错信息 搜索了一下,看到一个文章,说是从MySQL5.7以后,就增加了SSL连接验证功能,这个功能就可能导致上面这个报错,关掉它的话,连接速度能变快 尽管根据了解到的资料,SSL这个校验应该不会影响到使用 Localhost(本地)方式连接的才对,但还是死马当活马医,在ado.net连接字符串里加上了“SslMode=None;” 结果是成功的,确实不再报错,连接上了 再回过头来想想,我这两天也没对MySQL做过什么设置更改啊,仅有的操作,就是配置了一下ODBC数据源,怎么会突然间就出现这毛病呢? 不知道有没有大佬了解的,求科普 ———————————————— 版权声明:本文为CSDN博主「某店长」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/jdjdjdjdjdjd/article/details/89068331
View Detailsweb config 处理跨域请求
<system.webServer> <httpProtocol> <customHeaders> <add name="Access-Control-Allow-Methods" value="OPTIONS,POST,GET"/> <add name="Access-Control-Allow-Headers" value="x-requested-with"/> <add name="Access-Control-Allow-Origin" value="*" /> </customHeaders> </httpProtocol> </system.webServer> from:https://www.cnblogs.com/soonqian/p/6548118.html
View Detailsasp.net允许跨域配置web.config
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
<configuration> <system.webServer> <modules> <add name="CultureAwareHttpModule" type="Web_SJWD.Lang.CultureAwareHttpModule" /> </modules> <validation validateIntegratedModeConfiguration="false" /> <!---加下面这段可以跨域---> <httpProtocol> <customHeaders> <remove name="X-Powered-By" /> <add name="Access-Control-Allow-Origin" value="*" /> <add name="Access-Control-Allow-Headers" value="*" /> <add name="Access-Control-Allow-Methods" value="GET, POST, PUT, DELETE" /> </customHeaders> </httpProtocol> </system.webServer> </configuration> |
from:https://www.cnblogs.com/q149072205/p/11089954.html
View Details