Category Archives: Linux
Linux 远程桌面的两种方式
在绝多数情况下,Linux 不需要使用到GUI的桌面环境,但是有时在一些特殊的场景如安装Oracle的时候,需要有图形界面进行辅助才可以安装。 如果要使用Linux的图形界面,一般有两种方式: 1、Linux系统安装X Windows图形界面,使用vnc远程。 2、Linux系统启用X协议,配置X Clent,本地有桌面环境的机器(如Windows)配置X Server,获取远程的信息,在本地X server上显示图形界面。 方法一: 本机安装图形界面 这里以CentOS6.5的机器为例,安装图形界面比较简单,使用yum即可。
|
1 2 3 |
yum groupinstall "X Window System" yum groupinstall "Desktop" yum groupinstall "Font" |
然后执行:
|
1 2 3 |
startx #或者执行 init 5 |
如果要启动时自动加载图形界面,修改/etc/inittab最后一行的默认配置:
|
1 2 |
vi /etc/inittab id:5:initdefault: # 5 为图形模式,3 为默认字符模式 |
如果是CentOS7 的系统:
|
1 2 |
yum group list #列出可用的GUI软件包 yum group install "GNOME Desktop" "Graphical Administration Tools" |
修改默认运行模式(7和6不一样):
|
1 2 3 |
unlink /etc/systemd/system/default.target ln -sf /lib/systemd/system/runlevel5.target /etc/systemd/system/default.target reboot |
配置VNC 安装vnc:
|
1 |
yum install tigervnc tigervnc-server -y |
修改配置:
|
1 |
vi /etc/sysconfig/vncservers |
|
1 2 |
VNCSERVERS="2:root" VNCSERVERARGS[2]="-geometry 800x600 -nolisten tcp -localhost" |
设置vnc密码:
|
1 |
vncpasswd |
启动vncserver:
|
1 |
vncserver & |
这样,在本地就可以使用vncview远程连接到Linux图形界面。 方法二: 在Linux服务器上安装图形界面不是一种可取的方法,这样会降低服务器的性能,所以在这里重点介绍一下第二种方法。 X server 的运行原理是这样,远程的X client 做为客户端主动将数据发送到 x server服务器,X server服务器默认起始监听本地的6000端口,会根据不同客户端依次分配。X server将X client 传输的数据在本地进行处理,以图像的方式展现出来,数据传输使用的是X11协议。 这里需要先在本地电脑安装X server,可以使用比较流行的xming也可以使用VcXsrv,这两个都是开源的产品,当然如果有xmanager也能实现相同的功能。 这里我安装的是VcXsrv,使用默认的安装方式即可。 下载链接:https://sourceforge.net/projects/vcxsrv/ 配置好本地设置,默认的-1 改为0 ,然后一路点击默认配置,配置完成后启动VcXsrv server。 修改ssh配置/etc/ssh/sshd_config为:
|
1 2 3 |
AllowTcpForwarding yes X11Forwarding yes X11UseLocalhost yes |
重启sshd。 配置ssh,这里以xshell为例,如图: 如果有xmanager可以直接选择使用xmanager,由于是使用的VcXsrv,所以选择第二项,填写的IP为安装x server的主机,也就是本地电脑IP. 使用重新连接,配置环境变量(此处为X server的IP,配置要与Xshell统一 ):
|
1 2 |
export DISPLAY=192.168.20.171:0.0 xhost + |
如果安装的有xhost,执行 xhost + 此步的时候一直卡着没有输出,或者出现“xhost: unable to open display "192.168.20.171:0.0"”,请关闭本地防火墙,并确认本地X server的配置是否正确。 执行测试:
|
1 2 3 |
# yum install xclock # xclock Warning: Missing charsets in String to FontSet conversion |
[…]
View DetailsCentOS目录结构超详细版
最近初学Linux 对linux的目录产生了很多疑问,看到这篇文章,让我顿时对目录有了一个清晰的认识!推荐给大家! ———————————————————————————————————————————— 使用linux也有一年多时间了 最近也是一直在维护网站系统主机 下面是linux目录结构说明 本人使用的是centos系统,很久没有发表博文了 近期会整理自己所用所了解知识点,发表linux相关的文章,记录自己的linux点点滴滴。 linux 目录结构 /: 根目录,一般根目录下只存放目录,不要存放文件,/etc、/bin、/dev、/lib、/sbin应该和根目录放置在一个分区中 /bin:/usr/bin: 可执行二进制文件的目录,如常用的命令ls、tar、mv、cat等。 /boot: 放置linux系统启动时用到的一些文件。/boot/vmlinuz为linux的内核文件,以及/boot/grub。建议单独分区,分区大小100M即可 /dev: 存放linux系统下的设备文件,访问该目录下某个文件,相当于访问某个设备,常用的是挂载光驱mount /dev/cdrom /mnt。 /etc: 系统配置文件存放的目录,不建议在此目录下存放可执行文件,重要的配置文件有/etc/inittab、/etc/fstab、/etc/init.d、/etc/X11、/etc/sysconfig、/etc/xinetd.d修改配置文件之前记得备份。注:/etc/X11存放与x windows有关的设置。 /home: 系统默认的用户家目录,新增用户账号时,用户的家目录都存放在此目录下,~表示当前用户的家目录,~test表示用户test的家目录。建议单独分区,并设置较大的磁盘空间,方便用户存放数据 /lib:/usr/lib:/usr/local/lib: 系统使用的函数库的目录,程序在执行过程中,需要调用一些额外的参数时需要函数库的协助,比较重要的目录为/lib/modules。 /lost+fount: 系统异常产生错误时,会将一些遗失的片段放置于此目录下,通常这个目录会自动出现在装置目录下。如加载硬盘于/disk 中,此目录下就会自动产生目录/disk/lost+found /mnt:/media: 光盘默认挂载点,通常光盘挂载于/mnt/cdrom下,也不一定,可以选择任意位置进行挂载。 /opt: 给主机额外安装软件所摆放的目录。如:FC4使用的Fedora 社群开发软件,如果想要自行安装新的KDE 桌面软件,可以将该软件安装在该目录下。以前的 Linux 系统中,习惯放置在 /usr/local 目录下 /proc: 此目录的数据都在内存中,如系统核心,外部设备,网络状态,由于数据都存放于内存中,所以不占用磁盘空间,比较重要的目录有/proc/cpuinfo、/proc/interrupts、/proc/dma、/proc/ioports、/proc/net/*等 /root: 系统管理员root的家目录,系统第一个启动的分区为/,所以最好将/root和/放置在一个分区下。 /sbin:/usr/sbin:/usr/local/sbin: 放置系统管理员使用的可执行命令,如fdisk、shutdown、mount等。与/bin不同的是,这几个目录是给系统管理员root使用的命令,一般用户只能"查看"而不能设置和使用。 /tmp: 一般用户或正在执行的程序临时存放文件的目录,任何人都可以访问,重要数据不可放置在此目录下 /srv: 服务启动之后需要访问的数据目录,如www服务需要访问的网页数据存放在/srv/www内 /usr: 应用程序存放目录,/usr/bin 存放应用程序, /usr/share 存放共享数据,/usr/lib 存放不能直接运行的,却是许多程序运行所必需的一些函数库文件。/usr/local:存放软件升级包。/usr/share/doc: 系统说明文件存放目录。/usr/share/man: 程序说明文件存放目录,使用 man ls时会查询/usr/share/man/man1/ls.1.gz的内容建议单独分区,设置较大的磁盘空间 /var: 放置系统执行过程中经常变化的文件,如随时更改的日志文件 /var/log,/var/log/message: 所有的登录文件存放目录,/var/spool/mail: 邮件存放的目录,/var/run: 程序或服务启动 后,其PID存放在该目录下。建议单独分区,设置较大的磁盘空间 ------------------------------------------ /dev: 目录 dev是设备(device)的英文缩写。/dev这个目录对所有的用户都十分重要。因为在这个目录中包含了所有Linux系统中使用的外部设备。但是这里并不是放的外部设备的驱动程序,这一点和 windows,dos操作系统不一样。它实际上是一个访问这些外部设备的端口。我们可以非常方便地去访问这些外部设备,和访问一个文件,一个目录没有任何区别。 Linux沿袭Unix的风格,将所有设备认成是一个文件。 设备文件分为两种:块设备文件(b)和字符设备文件(c) 设备文件一般存放在/dev目录下,对常见设备文件作如下说明: /dev/hd[a-t]:IDE设备 /dev/sd[a-z]:SCSI设备 /dev/fd[0-7]:标准软驱 /dev/md[0-31]:软raid设备 /dev/loop[0-7]:本地回环设备 /dev/ram[0-15]:内存 /dev/null:无限数据接收设备,相当于黑洞 /dev/zero:无限零资源 /dev/tty[0-63]:虚拟终端 /dev/ttyS[0-3]:串口 /dev/lp[0-3]:并口 /dev/console:控制台 /dev/fb[0-31]:framebuffer /dev/cdrom => /dev/hdc /dev/modem => /dev/ttyS[0-9] /dev/pilot => /dev/ttyS[0-9] /dev/random:随机数设备 /dev/urandom:随机数设备 (PS:随机数设备,后面我会再写篇博客总结一下) /dev目录下的节点是怎么创建的? devf或者udev会自动帮你创建得。 kobject是sysfs文件系统的基础,udev通过监测、检测sysfs来获取新创建的设备的。 ------------------------------------------ /etc: 目录 包含很多文件.许多网络配置文件也在/etc 中. /etc/rc or /etc/rc.d or /etc/rc*.d 启动、或改变运行级时运行的scripts或scripts的目录. /etc/passwd […]
View Details6个Linux chkconfig命令实例 – 增加,删除,查看和修改services的自动启动选项
翻译自:http://www.thegeekstuff.com/2011/06/chkconfig-examples/ 注意:service的安装目录在/etc/rc.d/init.d下,/etc/init.d 是/etc/rc.d/init.d的链接。 chkconfig命令用来安装,查看或修改 services随系统启动的启动选项的设置。本文章包含了7个实例来解释如何使用chkconfig命令。 1 在shell脚本中检查service的启动选项的设置 当你执行chkconfig加service名字,如果service被配置为自动启动,则它将返回true。下列的代码段显示了如何在脚本中检查一个service是否被配置为自动启动。 # vi check.sh chkconfig network && echo "Network service is configured" chkconfig junk && echo "Junk service is configured" # ./check.sh Network service is configured 你也可以特别地查看它是否配置为在某个run level自动启动。 # vi check1.sh chkconfig network --level 3 && echo "Network service is configured for level 3" chkconfig network --level 1 && echo "Network service is configured for level 1" # ./check1.sh Network service is configured for level 3 2 查看所有的services的启动选项的设置 --list选项显示所有的services的启动选项的配置状态。 # chkconfig --list abrtd 0:off 1:off 2:off 3:on […]
View DetailsLinux中启动Tomcat:Permission denied 问题
错误:-bash: ./startup.sh: Permission denied 解决办法: 用命令chmod 修改一下Tomcat的bin目录下的.sh权限就可以了 如chmod u+x *.sh 在此执行,OK了。 from:https://blog.csdn.net/hzw2312/article/details/50247467
View Details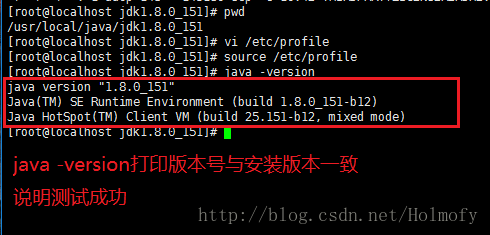
CentOS上搭建Tomcat环境并配置服务自启动
下载安装JDK 卸载原装的OpenJDK(如果有)
|
1 2 3 4 5 6 |
# 查看是否安装Java java -version # 查看Java的安装包信息 rpm -qa | grep java # 卸载原装Java,<java_package>为查找到的安装包信息 rpm -e --nodeps <java_package> |
OpenJDK是JDK的开源版本,Linux使用yum源安装的JDK都是这个版本,建议使用OracleJDK代替OpenJDK。 我这里使用的是最小化安装,所以就没有自带JDK了。 下载OracleJDK,官网下载地址: http://download.oracle.com/otn-pub/java/jdk/8u151-b12/e758a0de34e24606bca991d704f6dcbf/jdk-8u151-linux-i586.tar.gz
|
1 2 3 4 |
# 创建安装目录 mkdir -p /usr/local/java # 解压 tar -xzvf jdk-8u151-linux-i586.tar.gz -C /usr/local/java |
配置JAVA环境变量:
|
1 |
vi /etc/profile |
在/etc/profile文件末尾添加以下几行配置,注意第二行的最前面的“.”指的是当前路径,不是手误。还有JAVA_HOME目录的路径尽量靠过来,避免手残,敲错了找半天。
|
1 2 3 |
export JAVA_HOME=/usr/local/java/jdk1.8.0_151 export CLASSPATH=.:$JAVA_HOME/lib/tool.jar:$JAVA_HOME/lib/dt.jar export PATH=$PATH:$JAVA_HOME/bin |
使用source命令让配置生效
|
1 |
source /etc/profile |
下载并安装Tomcat 从清华大学的镜像站下载会快一点: https://mirrors.tuna.tsinghua.edu.cn/apache/tomcat/tomcat-8/v8.5.23/bin/apache-tomcat-8.5.23.tar.gz 因为Tomcat是Java写的,所以只要有了JRE就可以“一次编译到处运行”。so,Tomcat解压即可使用。 解压
|
1 |
tar -xzvf apache-tomcat-8.5.23.tar.gz -C /usr/local/java |
配置Tomcat的环境变量 在/etc/profile文件后再追加一条TOMCAT的环境变量
|
1 2 |
# 在/etc/profile文件末尾追加TOMCAT的环境变量 export CATALINA_HOME=/usr/local/java/apache-tomcat-8.5.23 |
CATALINA是Tomcat的启动程序,Tomcat的启动脚本都是使用CATALINA_HOME作为变量,所以这里我们要设置CATALINA_HOME 使用source命令完成是配置生效
|
1 |
source /etc/profile |
将Tomcat配置为服务 将Tomcat配置为系统服务后,就方便使用service命令来启动或关闭Tomcat服务 省的每次启动后还要到tomcat的bin目录下找startup脚本
|
1 2 3 4 5 |
# 把tomcat的脚本文件拷一份到/etc/init.d目录 cp /usr/local/java/apache-tomcat-8.5.23/bin/catalina.sh /etc/init.d/tomcat8 # 并把改脚本授权给所有用户执行 chmod 755 /etc/init.d/tomcat8 |
拷贝的脚本并不能直接使用,还需要修改添加一些配置。
|
1 |
vi /etc/init.d/tomcat8 |
添加chkconfig和description两行注释。有这两行注释才能支持chkconfig命令配置服务; 同时加上JAVA_HOME和CATALINA_HOME两个变量的声明。
|
1 2 3 4 5 |
#chkconfig: 2345 10 90 #description: tomcat8 service export JAVA_HOME=/usr/local/java/jdk1.8.0_151 export CATALINA_HOME=/usr/local/java/apache-tomcat-8.5.23 |
这里配置的2345指的是2345这4个运行级别会开机自启动,10是启动优先级,90是关闭优先级,优先级的值为0-99,越小优先级越高。 前面在/etc/profile文件配置中的环境变量只会在shell登录后执行,开机的过程中并不会加载/etc/profile,但是tomcat的启动脚本中需要这两个变量,所以需要在启动脚本中加入这两个变量。 使用chkconfig --add命令添加服务
|
1 |
[root@localhost ~]# chkconfig --add tomcat8 |
配置完成后Tomcat服务即可开机自启动 同时还可以使用service tomcat8 start和service tomcat8 stop命令来启动和停止tomcat服务。 配置防火墙打开8080端口并访问测试
|
1 2 |
# 对内网网段,打开8080端口 iptables -I INPUT -s 192.168.10.0/24 -p tcp --dport 8080 -j ACCEPT |
网络的配置由实际的环境决定 物理机访问测试: from:https://www.cnblogs.com/123hll/p/9640295.html
View Detailscentos7查看JAVA_HOME
windows: set java_home:查看JDK安装路径 java -version:查看JDK版本 linux: whereis java which java (java执行路径) echo $JAVA_HOME echo $PATH from:https://blog.csdn.net/Xin7Xin/article/details/86304542
View DetailsUbuntu修改密码和用户名
Ubuntu是一个Linux操作系统,修改密码和用户名是有危险的动作,请谨慎修改。 Ubuntu更改密码步骤: 1、进入Ubuntu,打开一个终端,输入 sudo su转为root用户。 注意,必须先转为root用户!!! 2、sudo passwd user(user 是对应的用户名) 3、输入新密码,确认密码。 4、修改密码成功,重启,输入新密码进入Ubuntu。 Ubuntu更改用户名步骤: 1、进入Ubuntu,打开一个终端,输入 sudo su转为root用户。 注意,必须先转为root用户!!! 2、gedit /etc/passwd ,找到代表你的那一行,修改用户名为新的用户名。 注意:只修改用户名!后面的全名、目录等不要动! 3、gedit /etc/shadow,找到代表你的那一行,修改用户名为新用户名 4、gedit /etc/group,你应该发现你的用户名在很多个组中,全部修改! 5、修改完,保存,重启。 注意:修改的时候要格外小心,不要打错一个字母。 提示:如果你要修改密码和用户名的话,请先修改密码,重启后,再修改用户名,重启。如果你先修改用户名,再修改密码的话,可能会导致你登录不了Ubuntu。 from:https://blog.csdn.net/qq_28959531/article/details/78989635
View DetailsLinux chkconfig命令
Linux chkconfig命令用于检查,设置系统的各种服务。 这是Red Hat公司遵循GPL规则所开发的程序,它可查询操作系统在每一个执行等级中会执行哪些系统服务,其中包括各类常驻服务。 语法
|
1 |
chkconfig [--add][--del][--list][系统服务] 或 chkconfig [--level <等级代号>][系统服务][on/off/reset] |
参数: --add 增加所指定的系统服务,让chkconfig指令得以管理它,并同时在系统启动的叙述文件内增加相关数据。 --del 删除所指定的系统服务,不再由chkconfig指令管理,并同时在系统启动的叙述文件内删除相关数据。 --level<等级代号> 指定读系统服务要在哪一个执行等级中开启或关毕。 实例 列出chkconfig所知道的所有命令。
|
1 |
# chkconfig -list |
开启服务。
|
1 2 |
# chkconfig telnet on //开启Telnet服务 # chkconfig --list //列出chkconfig所知道的所有的服务的情况 |
关闭服务
|
1 2 |
# chkconfig telnet off //关闭Telnet服务 # chkconfig -list //列出chkconfig所知道的所有的服务的情况 |
from:https://www.runoob.com/linux/linux-comm-chkconfig.html
View DetailsCentOS6.5将shell脚本设置为服务和开机启动的方法
第一种开机执行命令法: 直接修改/etc/rc.d/rc.local文件 编辑文件/etc/rc.d/rc.local vi /etc/rc.d/rc.local 比如要将zookeeper添加为开机自启动就在最后加上“/usr/local/zookeeper-3.4.5/bin/zkServer.sh start” 配置好之后,重启centos,会发现命令被执行了。前提条件是当前机器环境变量中有java命令即$JAVA_HOME/bin的路径,否则zookeeper也启动不了。 Bash
|
1 2 3 4 5 6 7 8 9 10 11 |
[root@zookeeper ~]# vim /etc/rc.d/rc.local #!/bin/sh # # This script will be executed *after* all the other init scripts. # You can put your own initialization stuff in here if you don't # want to do the full Sys V style init stuff. touch /var/lock/subsys/local # /usr/local/zookeeper-3.4.5/bin/zkServer.sh start |
第二种服务自启动法: 这次换个jetty吧 1、进入到/etc/rc.d/init.d目录下,新建一个jetty脚本 Bash
|
1 |
vi /etc/rc.d/init.d/jetty |
将以下脚本写入文件中,可以看出这是一个case语句判断,当我们使用"service jetty start"启动服务的时候"start"参数就会变成$1传入下面的脚本,从而做出对应的操作。 # chkconfig: 345 99 99 (这个比较有意思,345代表在设置在那个level中是on的,如果一个都不想on,那就写一个横线"-",比如:chkconfig: – 99 99。后面两个数字当然代表S和K的默认排序号啦,基本都写99,排后面启动安全保险) Bash
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
#!/bin/bash #chkconfig: 345 99 99 #description:jetty server #processname:jetty JETTY_HOME=/app/jetty9_4_8 case $1 in start) su root $JETTY_HOME/bin/jetty.sh start;; stop) su root $JETTY_HOME/bin/jetty.sh stop;; check) su root $JETTY_HOME/bin/jetty.sh check;; restart) su root $JETTY_HOME/bin/jetty.sh restart;; *) echo "require start|stop|check|restart" ;; esac |
2、最后保存jetty文件后别忘了设置文件的执行权限 Bash
|
1 |
chmod +x jetty |
3、至此服务已经创建好了,可以用"service jetty start"来启动jetty了,但我们要设置自启动还需要添加到chkconfig来管理 Bash
|
1 2 3 |
chkconfig --add jetty chkconfig --list jetty |
看到3是启动状态就说明在文本界面启动方式下该服务已经设置为自启动了,5是图形化界面 如果不是启动状态需要用命令开启自启动 Bash
|
1 2 3 |
chkconfig --level 345 jetty on chkconfig --list jetty |
这样就没问题了。 from:https://blog.csdn.net/e_wsq/article/details/79885180
View Details