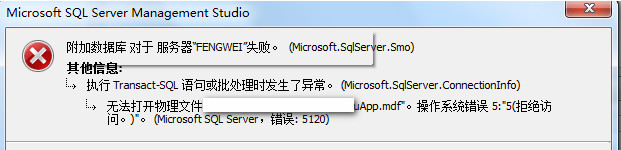
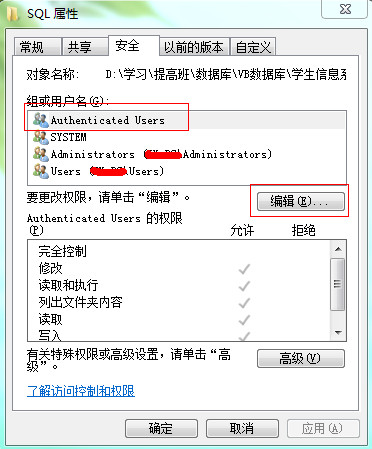
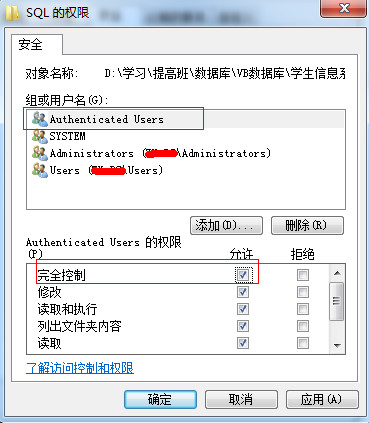
/**
* 某某跟踪报表
**/
--exec spName1 '','','','','','','公司代号'
CREATE Procedure spName1
@MESOrderID nvarchar(320), --工单号,最多30个
@LotName nvarchar(700), --产品序列号,最多50个
@DateCode nvarchar(500), --供应商批次号,最多30个
@BatchID nvarchar(700), --组装件序列号/物料批号,最多50个
@comdef nvarchar(700), --组装件物料编码,最多30个
@SNCust nvarchar(1600), --外部序列号,最多50个
@OnPlant nvarchar(20) --平台
AS
BEGIN
SET NOCOUNT ON;
/**
* 1)定义全局的临时表,先根据六个查询条件的任意一个,得出临时表结果
**/
CREATE TABLE #FinalLotName
(
LotName NVARCHAR(50), --序列号
SourceLotName NVARCHAR(50), --来源序列号
SNCust NVARCHAR(128) --外部序列号
)
--1.1
IF @LotName<>''
BEGIN
SELECT Val INTO #WorkLot FROM fn_String_To_Table(@LotName,',',1)
SELECT LotPK,LotName INTO #WorkLotPK FROM MMLots WITH(NOLOCK) WHERE EXISTS(SELECT 1 FROM #WorkLot b WHERE b.Val=MMLots.LotID)
--求SourceLotPK只能在这里求
SELECT a.LotPK,a.SourceLotPK into #WorkSourcePK FROM MMLotOperations a WITH(NOLOCK) WHERE EXISTS(SELECT 1 FROM #WorkLotPK b WHERE b.LotPK=a.LotPK) AND a.SourceLotPK IS NOT NULL
SELECT a.LotPK,a.SourceLotPK,b.LotName INTO #WorkSourcePK2 FROM #WorkSourcePK a JOIN #WorkLotPK b ON a.LotPK=b.LotPK
INSERT INTO #FinalLotName SELECT a.LotName,b.LotName AS SourceLotName,NULL FROM #WorkSourcePK2 a JOIN (SELECT LotPK,LotName FROM MMLots WITH(NOLOCK) ) b on a.SourceLotPK=b.LotPK --b的里面加不加WHERE RowDeleted=0待确定
SELECT a.LotName,a.SourceLotName,b.SNCust INTO #FinalLotNameX1 FROM #FinalLotName a LEFT JOIN CO_SN_LINK_CUSTOMER b WITH(NOLOCK) ON a.LotName=b.SNMes
DELETE FROM #FinalLotName
INSERT INTO #FinalLotName SELECT LotName,SourceLotName,SNCust FROM #FinalLotNameX1
END
--1.2
IF @BatchID<>''
BEGIN
SELECT Val INTO #WorkSourceLot FROM fn_String_To_Table(@BatchID,',',1)
IF EXISTS(SELECT 1 FROM #FinalLotName)--如果@LotName也不为空
BEGIN
SELECT a.LotName,a.SourceLotName,a.SNCust INTO #FinalLotNameX2 FROM #FinalLotName a WHERE EXISTS(SELECT 1 FROM #WorkSourceLot b WHERE a.SourceLotName=b.Val)
DELETE FROM #FinalLotName
INSERT INTO #FinalLotName SELECT LotName,SourceLotName,SNCust FROM #FinalLotNameX2
END
ELSE --@LotName条件为空
BEGIN
SELECT LotPK AS SourceLotPK,LotName AS SourceLotName INTO #2 FROM MMLots WITH(NOLOCK) WHERE EXISTS(SELECT 1 FROM #WorkSourceLot b WHERE b.Val=MMLots.LotID)
SELECT a.LotPK,a.SourceLotPK into #21 FROM MMLotOperations a WITH(NOLOCK) WHERE EXISTS(SELECT 1 FROM #2 b WHERE b.SourceLotPK=a.SourceLotPK)
SELECT a.LotPK,a.SourceLotPK,b.SourceLotName INTO #22 FROM #21 a JOIN #2 b ON a.SourceLotPK=b.SourceLotPK
INSERT INTO #FinalLotName SELECT b.LotName,a.SourceLotName,NULL FROM #22 a JOIN (SELECT LotPK,LotName FROM MMLots WITH(NOLOCK) ) b on a.LotPK=b.LotPK --b的里面加不加WHERE RowDeleted=0待确定
SELECT a.LotName,a.SourceLotName,b.SNCust INTO #FinalLotNameX21 FROM #FinalLotName a LEFT JOIN CO_SN_LINK_CUSTOMER b WITH(NOLOCK) ON a.LotName=b.SNMes
DELETE FROM #FinalLotName
INSERT INTO #FinalLotName SELECT LotName,SourceLotName,SNCust FROM #FinalLotNameX21
END
END
--1.3
IF @SNCust<>''
BEGIN
SELECT Val INTO #WorkCustomSN FROM fn_String_To_Table(@SNCust,',',1)
IF EXISTS(SELECT 1 FROM #FinalLotName)--前面两个条件至少有一个有值
BEGIN
SELECT a.LotName,a.SourceLotName,a.SNCust INTO #FinalLotNameX3 FROM #FinalLotName a WHERE EXISTS(SELECT 1 FROM #WorkCustomSN b WHERE a.SNCust=b.Val)
DELETE FROM #FinalLotName
INSERT INTO #FinalLotName SELECT LotName,SourceLotName,SNCust FROM #FinalLotNameX3
END
ELSE
BEGIN
SELECT a.SNMes INTO #WorkLotX FROM CO_SN_LINK_CUSTOMER a WITH(NOLOCK) WHERE EXISTS(SELECT 1 FROM #WorkCustomSN b WHERE a.SNCust=b.Val)
-------------------以下逻辑和变量1(@LotName)类似[先根据外部序列号求解序列号,再照搬第一个判断变量的方式]
SELECT LotPK,LotName INTO #WorkLotPKX FROM MMLots WITH(NOLOCK) WHERE EXISTS(SELECT 1 FROM #WorkLotX b WHERE b.SNMes=MMLots.LotID)
--求SourceLotPK只能在这里求
SELECT a.LotPK,a.SourceLotPK into #WorkSourcePKX FROM MMLotOperations a WITH(NOLOCK) WHERE EXISTS(SELECT 1 FROM #WorkLotPKX b WHERE b.LotPK=a.LotPK) AND a.SourceLotPK IS NOT NULL
SELECT a.LotPK,a.SourceLotPK,b.LotName INTO #WorkSourcePK2X FROM #WorkSourcePKX a JOIN #WorkLotPKX b ON a.LotPK=b.LotPK
INSERT INTO #FinalLotName SELECT a.LotName,b.LotName AS SourceLotName,NULL FROM #WorkSourcePK2X a JOIN (SELECT LotPK,LotName FROM MMLots WITH(NOLOCK) ) b on a.SourceLotPK=b.LotPK --b的里面加不加WHERE RowDeleted=0待确定
SELECT a.LotName,a.SourceLotName,b.SNCust INTO #FinalLotNameX31 FROM #FinalLotName a LEFT JOIN CO_SN_LINK_CUSTOMER b WITH(NOLOCK) ON a.LotName=b.SNMes
DELETE FROM #FinalLotName
INSERT INTO #FinalLotName SELECT LotName,SourceLotName,SNCust FROM #FinalLotNameX31
-----------------------
END
END
/**
* 2)定义全局的临时表,用于替换第一个全局临时表。
**/
CREATE TABLE #FinalCO_SN
(
SN NVARCHAR(50),
SourceSN NVARCHAR(50),
SNCust NVARCHAR(128),
matl_def_id NVARCHAR(50),--sn的物料ID
ComMaterials NVARCHAR(50), --SourceSN的物料ID
MESOrderID NVARCHAR(20),
OnPlantID NVARCHAR(20),
VendorID NVARCHAR(20),
DateCode NVARCHAR(20) ,
SNNote NVARCHAR(512)
)
--2.1
IF @MESOrderID<>''
BEGIN
-------------------------------将MESOrderID做特殊处理-----------------------------------
SELECT Val INTO #WorkMESOrderID FROM fn_String_To_Table(@MESOrderID,',',1)
IF @OnPlant='Comba'
BEGIN
UPDATE #WorkMESOrderID SET Val='C000'+Val WHERE LEN(Val)=9
END
ELSE
BEGIN
UPDATE #WorkMESOrderID SET Val='W000'+Val WHERE LEN(Val)=9
END
SELECT SN,MaterialID,MESOrderID,OnPlantID INTO #WorkCO_SN1 FROM CO_SN_GENERATION a WITH(NOLOCK)
WHERE SNType='IntSN' AND SNRuleName = 'ProductSNRule' AND OnPlantID=@OnPlant
AND EXISTS(SELECT 1 FROM #WorkMESOrderID b WHERE a.MESOrderID=b.Val)
------------------------------------------------------------------------------------------
--条件判断(逻辑分析)开始
IF EXISTS(SELECT 1 FROM #FinalLotName)--如果前面判断的查询条件有值
BEGIN
--查出SourceLotName对应的查询字段
SELECT a.SN AS SourceLotName,a.VendorID,a.DateCode,a.SNNote,a.MaterialID AS ComMaterials INTO #SourceLotNameTable FROM CO_SN_GENERATION a WITH(NOLOCK) WHERE EXISTS(SELECT 1 FROM #FinalLotName b WHERE a.SN=b.SourceLotName)
INSERT INTO #FinalCO_SN
SELECT a.LotName,a.SourceLotName,d.SNCust,b.MaterialID,c.ComMaterials,b.MESOrderID,b.OnPlantID,c.VendorID,c.DateCode,c.SNNote FROM #FinalLotName a
LEFT JOIN #WorkCO_SN1 b ON a.LotName=b.SN
LEFT JOIN #SourceLotNameTable c ON a.SourceLotName=c.SourceLotName
LEFT JOIN CO_SN_LINK_CUSTOMER d WITH(NOLOCK) ON a.LotName=d.SNMes
END
ELSE
BEGIN
--已知SN集合求解对应的SourceSN和SNCust集合------------------------------------------
SELECT LotPK,LotName INTO #WorkLotPK410 FROM MMLots WITH(NOLOCK) WHERE EXISTS(SELECT 1 FROM #WorkCO_SN1 b WHERE b.SN=MMLots.LotID)
SELECT a.LotPK,a.SourceLotPK into #WorkSourcePK420 FROM MMLotOperations a WITH(NOLOCK) WHERE EXISTS(SELECT 1 FROM #WorkLotPK410 b WHERE b.LotPK=a.LotPK) AND a.SourceLotPK IS NOT NULL
SELECT a.LotPK,a.SourceLotPK,b.LotName INTO #WorkSourcePK430 FROM #WorkSourcePK420 a JOIN #WorkLotPK410 b ON a.LotPK=b.LotPK
INSERT INTO #FinalLotName SELECT a.LotName,b.LotName AS SourceLotName,NULL FROM #WorkSourcePK430 a JOIN (SELECT LotPK,LotName FROM MMLots WITH(NOLOCK) ) b on a.SourceLotPK=b.LotPK --b的里面加不加WHERE RowDeleted=0待确定
SELECT a.LotName,a.SourceLotName,b.SNCust INTO #FinalLotNameX440 FROM #FinalLotName a LEFT JOIN CO_SN_LINK_CUSTOMER b WITH(NOLOCK) ON a.LotName=b.SNMes
DELETE FROM #FinalLotName
INSERT INTO #FinalLotName SELECT LotName,SourceLotName,SNCust FROM #FinalLotNameX440
-------------------------------------------------------------------------------------
SELECT a.SN AS SourceLotName,a.VendorID,a.DateCode,a.SNNote,a.MaterialID AS ComMaterials INTO #SourceLotNameTable2 FROM CO_SN_GENERATION a WITH(NOLOCK) WHERE EXISTS(SELECT 1 FROM #FinalLotName b WHERE a.SN=b.SourceLotName)
INSERT INTO #FinalCO_SN
SELECT a.LotName,a.SourceLotName,a.SNCust,b.MaterialID,c.ComMaterials,b.MESOrderID,b.OnPlantID,c.VendorID,c.DateCode,c.SNNote FROM #FinalLotName a
LEFT JOIN #WorkCO_SN1 b ON a.LotName=b.SN
LEFT JOIN #SourceLotNameTable2 c ON a.SourceLotName=c.SourceLotName
END
END
--2.2
IF @DateCode<>''
BEGIN
SELECT Val INTO #WorkDateCode FROM fn_String_To_Table(@DateCode,',',1)
--此@DataCode条件求解出来的是SourceSN
SELECT SN AS SourceSN,MaterialID AS ComMaterials,VendorID,DateCode,SNNote INTO #WorkSourceSNT1 FROM CO_SN_GENERATION a WITH(NOLOCK) WHERE EXISTS(SELECT 1 FROM #WorkDateCode b WHERE a.DateCode=b.Val)
----------------------------------------------------------------------------------------------------
--条件判断(逻辑分析)开始
IF EXISTS(SELECT 1 FROM #FinalCO_SN)--如果前面判断的查询条件有值
BEGIN
SELECT a.LotName,a.SourceLotName,a.SNCust,a.MaterialID,a.ComMaterials,a.MESOrderID,a.OnPlantID,a.VendorID,a.DateCode,a.SNNote INTO #TMP51 FROM #FinalCO_SN a WHERE EXISTS (SELECT 1 FROM #WorkDateCode b WHERE a.DateCode=b.Val)
DELETE FROM #FinalCO_SN
INSERT INTO #FinalCO_SN SELECT LotName,SourceLotName,SNCust,MaterialID,ComMaterials,MESOrderID,OnPlantID,VendorID,DateCode,SNNote FROM #TMP51
END
ELSE
BEGIN
IF EXISTS(SELECT 1 FROM #FinalLotName)
BEGIN
--查出SourceLotName对应的查询字段
SELECT a.SourceSN,a.VendorID,a.DateCode,a.SNNote,a.ComMaterials INTO #SourceLTX5 FROM #WorkSourceSNT1 a WHERE EXISTS(SELECT 1 FROM #FinalLotName b WHERE a.SourceSN=b.SourceLotName)
--查出SN对应的查询字段
SELECT SN,MaterialID,MESOrderID,OnPlantID INTO #WorkSNT510 FROM CO_SN_GENERATION a WITH(NOLOCK)
WHERE SNType='IntSN' AND SNRuleName = 'ProductSNRule' AND OnPlantID=@OnPlant
AND EXISTS(SELECT 1 FROM #FinalLotName b WHERE a.SN=b.LotName)
INSERT INTO #FinalCO_SN
SELECT a.LotName,a.SourceLotName,d.SNCust,b.MaterialID,c.ComMaterials,b.MESOrderID,b.OnPlantID,c.VendorID,c.DateCode,c.SNNote FROM #FinalLotName a
LEFT JOIN #WorkSNT510 b ON a.LotName=b.SN
LEFT JOIN #WorkSourceSNT1 c ON a.SourceLotName=c.SourceSN
LEFT JOIN CO_SN_LINK_CUSTOMER d WITH(NOLOCK) ON a.LotName=d.SNMes
END
ELSE
BEGIN
--已知SourceSN集合求解对应的SN和SNCust集合------------------------------------------
SELECT LotPK AS SourceLotPK,LotName AS SrouceLotName INTO #WorkLotX510 FROM MMLots WITH(NOLOCK) WHERE EXISTS(SELECT 1 FROM #WorkSourceSNT1 b WHERE b.SourceSN=MMLots.LotID)
SELECT a.LotPK,a.SourceLotPK into #WorkLotX520 FROM MMLotOperations a WITH(NOLOCK) WHERE EXISTS(SELECT 1 FROM #WorkLotX510 b WHERE b.SourceLotPK=a.SourceLotPK)
SELECT a.LotPK,a.SourceLotPK,b.SrouceLotName INTO #WorkLotX530 FROM #WorkLotX520 a JOIN #WorkLotX510 b ON a.SourceLotPK=b.SourceLotPK
INSERT INTO #FinalLotName SELECT b.LotName,a.SrouceLotName,NULL FROM #WorkLotX530 a JOIN (SELECT LotPK,LotName FROM MMLots WITH(NOLOCK) ) b on a.LotPK=b.LotPK --b的里面加不加WHERE RowDeleted=0待确定
SELECT a.LotName,a.SourceLotName,b.SNCust INTO #WorkLotX540 FROM #FinalLotName a LEFT JOIN CO_SN_LINK_CUSTOMER b WITH(NOLOCK) ON a.LotName=b.SNMes
DELETE FROM #FinalLotName
INSERT INTO #FinalLotName SELECT LotName,SourceLotName,SNCust FROM #WorkLotX540
-------------------------------------------------------------------------------------
SELECT SN,MaterialID,MESOrderID,OnPlantID INTO #WorkLotX550 FROM CO_SN_GENERATION a WITH(NOLOCK)
WHERE SNType='IntSN' AND SNRuleName = 'ProductSNRule' AND OnPlantID=@OnPlant
AND EXISTS(SELECT 1 FROM #FinalLotName b WHERE a.SN=b.LotName)
INSERT INTO #FinalCO_SN
SELECT a.LotName,a.SourceLotName,a.SNCust,b.MaterialID,c.ComMaterials,b.MESOrderID,b.OnPlantID,c.VendorID,c.DateCode,c.SNNote FROM #FinalLotName a
LEFT JOIN #WorkLotX550 b ON a.LotName=b.SN
LEFT JOIN #WorkSourceSNT1 c ON a.SourceLotName=c.SourceSN
END
END
END
--2.3
IF @comdef<>''
BEGIN
SELECT Val INTO #WorkComdef FROM fn_String_To_Table(@comdef,',',1)
--此@comdef条件求解出来的是SourceSN
SELECT SN AS SourceSN,MaterialID AS ComMaterials,VendorID,DateCode,SNNote INTO #WorkSourceSNT16 FROM CO_SN_GENERATION a WITH(NOLOCK) WHERE EXISTS(SELECT 1 FROM #WorkComdef b WHERE a.MaterialID=b.Val)
----------------------------------------------------------------------------------------------------
--条件判断(逻辑分析)开始
IF EXISTS(SELECT 1 FROM #FinalCO_SN)--如果前面判断的查询条件有值
BEGIN
SELECT a.LotName,a.SourceLotName,a.SNCust,a.MaterialID,a.ComMaterials,a.MESOrderID,a.OnPlantID,a.VendorID,a.DateCode,a.SNNote INTO #TMP516 FROM #FinalCO_SN a WHERE EXISTS (SELECT 1 FROM #WorkComdef b WHERE a.matl_def_id=b.Val)
DELETE FROM #FinalCO_SN
INSERT INTO #FinalCO_SN SELECT LotName,SourceLotName,SNCust,MaterialID,ComMaterials,MESOrderID,OnPlantID,VendorID,DateCode,SNNote FROM #TMP516
END
ELSE
BEGIN
IF EXISTS(SELECT 1 FROM #FinalLotName)
BEGIN
--查出SourceLotName对应的查询字段
SELECT a.SourceSN,a.VendorID,a.DateCode,a.SNNote,a.ComMaterials INTO #SourceLTX56 FROM #WorkSourceSNT16 a WHERE EXISTS(SELECT 1 FROM #FinalLotName b WHERE a.SourceSN=b.SourceLotName)
--查出SN对应的查询字段
SELECT SN,MaterialID,MESOrderID,OnPlantID INTO #WorkSNT5106 FROM CO_SN_GENERATION a WITH(NOLOCK)
WHERE SNType='IntSN' AND SNRuleName = 'ProductSNRule' AND OnPlantID=@OnPlant
AND EXISTS(SELECT 1 FROM #FinalLotName b WHERE a.SN=b.LotName)
INSERT INTO #FinalCO_SN
SELECT a.LotName,a.SourceLotName,d.SNCust,b.MaterialID,c.ComMaterials,b.MESOrderID,b.OnPlantID,c.VendorID,c.DateCode,c.SNNote FROM #FinalLotName a
LEFT JOIN #WorkSNT5106 b ON a.LotName=b.SN
LEFT JOIN #WorkSourceSNT16 c ON a.SourceLotName=c.SourceSN
LEFT JOIN CO_SN_LINK_CUSTOMER d WITH(NOLOCK) ON a.LotName=d.SNMes
END
ELSE
BEGIN
--已知SourceSN集合求解对应的SN和SNCust集合------------------------------------------
SELECT LotPK AS SourceLotPK,LotName AS SrouceLotName INTO #WorkLotX5106 FROM MMLots WITH(NOLOCK) WHERE EXISTS(SELECT 1 FROM #WorkSourceSNT16 b WHERE b.SourceSN=MMLots.LotID)
SELECT a.LotPK,a.SourceLotPK into #WorkLotX5206 FROM MMLotOperations a WITH(NOLOCK) WHERE EXISTS(SELECT 1 FROM #WorkLotX5106 b WHERE b.SourceLotPK=a.SourceLotPK)
SELECT a.LotPK,a.SourceLotPK,b.SrouceLotName INTO #WorkLotX5306 FROM #WorkLotX5206 a JOIN #WorkLotX5106 b ON a.SourceLotPK=b.SourceLotPK
INSERT INTO #FinalLotName SELECT b.LotName,a.SrouceLotName,NULL FROM #WorkLotX5306 a JOIN (SELECT LotPK,LotName FROM MMLots WITH(NOLOCK) ) b on a.LotPK=b.LotPK --b的里面加不加WHERE RowDeleted=0待确定
SELECT a.LotName,a.SourceLotName,b.SNCust INTO #WorkLotX5406 FROM #FinalLotName a LEFT JOIN CO_SN_LINK_CUSTOMER b WITH(NOLOCK) ON a.LotName=b.SNMes
DELETE FROM #FinalLotName
INSERT INTO #FinalLotName SELECT LotName,SourceLotName,SNCust FROM #WorkLotX5406
-------------------------------------------------------------------------------------
SELECT SN,MaterialID,MESOrderID,OnPlantID INTO #WorkLotX5506 FROM CO_SN_GENERATION a WITH(NOLOCK)
WHERE SNType='IntSN' AND SNRuleName = 'ProductSNRule' AND OnPlantID=@OnPlant
AND EXISTS(SELECT 1 FROM #FinalLotName b WHERE a.SN=b.LotName)
INSERT INTO #FinalCO_SN
SELECT a.LotName,a.SourceLotName,a.SNCust,b.MaterialID,c.ComMaterials,b.MESOrderID,b.OnPlantID,c.VendorID,c.DateCode,c.SNNote FROM #FinalLotName a
LEFT JOIN #WorkLotX5506 b ON a.LotName=b.SN
LEFT JOIN #WorkSourceSNT16 c ON a.SourceLotName=c.SourceSN
END
END
END
/**
* 3)条件判断结束
**/
IF EXISTS(SELECT 1 FROM #FinalLotName)
BEGIN
IF EXISTS(SELECT 1 FROM #FinalCO_SN)
BEGIN--3.1
SELECT a.matl_def_id,b.Descript,a.MESOrderID AS pom_order_id,a.SN AS LotName,a.SourceSN AS ComLot,
a.ComMaterials,c.Descript AS ComMatDes,a.VendorID,a.DateCode,a.SNNote,
OnPlantID,SNCust FROM #FinalCO_SN a
JOIN MMDefinitions b WITH(NOLOCK) ON a.matl_def_id=b.DefID
JOIN MMDefinitions c WITH(NOLOCK) ON a.ComMaterials=c.DefID
WHERE NOT EXISTS(select distinct SN, SourceSN from #FinalCO_SN x
where x.SN = a.SourceSN and x.SourceSN = a.SN)
END
ELSE
BEGIN--3.2
--3.2.1求解SN的必查字段
SELECT SN,MaterialID,MESOrderID,OnPlantID INTO #FinalSNX1 FROM CO_SN_GENERATION a WITH(NOLOCK)
WHERE SNType='IntSN' AND SNRuleName = 'ProductSNRule' AND OnPlantID=@OnPlant
AND EXISTS(SELECT 1 FROM #FinalLotName b WHERE a.SN=b.LotName)
--3.2.2求解SourceSN的必查字段
SELECT a.SN AS SourceLotName,a.VendorID,a.DateCode,a.SNNote,a.MaterialID AS ComMaterials INTO #FinalSNX2 FROM CO_SN_GENERATION a WITH(NOLOCK) WHERE EXISTS(SELECT 1 FROM #FinalLotName b WHERE a.SN=b.SourceLotName)
SELECT b.MaterialID AS matl_def_id,x.Descript,b.MESOrderID AS pom_order_id,b.SN AS LotName,c.SourceLotName AS ComLot,c.ComMaterials,y.Descript AS ComMatDes,c.VendorID,c.DateCode,c.SNNote,b.OnPlantID,a.SNCust
FROM #FinalLotName a
LEFT JOIN #FinalSNX1 b ON a.LotName=b.SN
LEFT JOIN #FinalSNX2 c ON a.SourceLotName=c.SourceLotName
JOIN MMDefinitions x WITH(NOLOCK) ON b.MaterialID=x.DefID
JOIN MMDefinitions y WITH(NOLOCK) ON c.ComMaterials=y.DefID
WHERE NOT EXISTS(
SELECT DISTINCT * FROM #FinalLotName z
WHERE z.LotName=a.SourceLotName and z.SourceLotName=a.LotName
)
END
END
ELSE
BEGIN
IF EXISTS(SELECT 1 FROM #FinalCO_SN)
BEGIN--3.3
SELECT a.matl_def_id,b.Descript,a.MESOrderID AS pom_order_id,a.SN AS LotName,a.SourceSN AS ComLot,
a.ComMaterials,c.Descript AS ComMatDes,a.VendorID,a.DateCode,a.SNNote,
OnPlantID,SNCust FROM #FinalCO_SN a
JOIN MMDefinitions b WITH(NOLOCK) ON a.matl_def_id=b.DefID
JOIN MMDefinitions c WITH(NOLOCK) ON a.ComMaterials=c.DefID
WHERE NOT EXISTS(select distinct SN, SourceSN from #FinalCO_SN x
where x.SN = a.SourceSN and x.SourceSN = a.SN)
END
ELSE
BEGIN--3.4
PRINT 'There is no queryable condition,please enter at less a query conditon.'
END
END
END
GO