Category Archives: Database
MISCONF Redis is configured to save RDB snapshots, but it is currently not a
开发环境最近遇到了"MISCONF Redis is configured to save RDB snapshots, but is currently not able to persist on disk"的问题,服务出现了问题,一看日志是Redis在报这个错误。 查了查网上的资料,解决方案基本都是修改Redis的配置文件,将 stop-writes-on-bgsave-error yes修改为 stop-writes-on-bgsave-error no 这是一个暂时性的解决方法。看了看stackoverflow上的回答,最高赞回答是这样的,如下图: 大概意思是:这是一个快速应急方法,如果你担心你的数据,那就首先检查下bgsave方法为什么会失败。bgsave方法是干什么的呢?咱来看下面这张图: bgsave方法为什么会失败呢?咱们看看大佬的回答 大概意思是(翻译不到位的地方,还请见谅,英文比较菜):在BGSAVE时,Redis会fork一个子进程,把数据保存到硬盘上。你可以通过查看日志来获取BGSAVE失败的原因(Linux系统里Redis日志文件通常是在/var/log/redis/redis-server.log),大多数时候BGSAVE失败的原因是fork进程分配不到内存。更多时候,fork进程分配不到内存是因为跟操作系统的优化相冲突,即使操作系统有足够的内存。(下面一大段就不翻译了,意思是可以Redis官网找到相应的解释,文末会把相关文章链接都缀上)。当然大神也给出了解决方案 Linux系统中,修改/etc/sysctl.conf文件,添加配置: vm.overcommit_memory=1 执行命令,使其生效 sudo sysctl -p /etc/sysctl.conf 参考文章链接: stackoverflow的回答链接 BGSAVE命令解释 redis官网的faq from:https://blog.csdn.net/u014071875/article/details/103715183
View Details笔记:解决redis连接错误:MISCONF Redis is configured to save RDB snapshots, but it is currently not able to…
今天重启游戏服务器在连接redis数据库时突然报错:MISCONF Redis is configured to save RDB snapshots, but it is currently not able to persist on disk. Commands that may modify the data set are disabled, because this instance is configured to report errors during writes if RDB snapshotting fails (stop-writes-on-bgsave-error option). Please check the Redis logs for details about the RDB error. 究其原因是因为强制把redis快照关闭了导致不能持久化的问题,在网上查了一些相关解决方案,通过stop-writes-on-bgsave-error值设置为no即可避免这种问题。 有两种修改方法,一种是通过redis命令行修改,另一种是直接修改redis.conf配置文件 命令行修改方式示例: 127.0.0.1:6379> config set stop-writes-on-bgsave-error no 修改redis.conf文件:vi打开redis-server配置的redis.conf文件,然后使用快捷匹配模式:/stop-writes-on-bgsave-error定位到stop-writes-on-bgsave-error字符串所在位置,接着把后面的yes设置为no即可。 from:https://blog.csdn.net/qq_31766907/article/details/78715935
View DetailsMySQL 错误1418 的原因分析及解决方法
具体错误: 使用mysql创建、调用存储过程,函数以及触发器的时候会有错误符号为1418错误。 [Err] 1418 – This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary logging is enabled (you *might* want to use the less safe log_bin_trust_function_creators variable) 查阅相关资料,意思是说binlog启用时,创建的函数没有声明类型,因为binlog在主从复制需要知道这个函数创建语句是什么类型,否则同步数据会有不一致现象。 mysql开启了bin-log, 我们就必须指定我们的函数是否是哪种类型: 1 DETERMINISTIC 不确定的 2 NO SQL 没有SQl语句,当然也不会修改数据 3 READS SQL DATA 只是读取数据,当然也不会修改数据 4 MODIFIES SQL DATA 要修改数据 5 CONTAINS SQL 包含了SQL语句 为了解决这个问题,MySQL强制要求: 在主服务器上,除非子程序被声明为确定性的或者不更改数据,否则创建或者替换子程序将被拒绝。这意味着当创建一个子程序的时候,必须要么声明它是确定性的,要么它不改变数据。 声明方式有两种: 第一种:声明是否是确定性的 DETERMINISTIC和NOT DETERMINISTIC指出一个子程序是否对给定的输入总是产生同样的结果。 如果没有给定任一特征,默认是NOT DETERMINISTIC,所以必须明确指定DETERMINISTIC来声明一个子程序是确定性的。 这里要说明的是:使用NOW() 函数(或它的同义)或者RAND() 函数不会使一个子程序变成非确定性的。对NOW()而言,二进制日志包括时间戳并会被正确的执行。RAND()只要在一个子程序内被调用一次也可以被正确的复制。所以,可以认为时间戳和随机数种子是子程序的确定性输入,它们在主服务器和从服务器上是一样的。 第二种:声明是否会改变数据 CONTAINS SQL, NO SQL, READS SQL DATA, MODIFIES SQL用来指出子程序是读还是写数据的。 无论NO SQL还是READS SQL DATA都指出,子程序没有改变数据,但是必须明确地指定其中一个,因为如果任何指定,默认的指定是CONTAINS SQL。 默认情况下,如果允许CREATE PROCEDURE 或CREATE […]
View DetailsMySQL表名转大写
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
DELIMITER // CREATE DEFINER=`root`@`localhost` PROCEDURE `p_Uppercase`(IN `dbname` varchar(200)) BEGIN DECLARE done INT DEFAULT 0; DECLARE oldname VARCHAR(200); DECLARE cur CURSOR FOR SELECT table_name FROM information_schema.TABLES WHERE table_schema = dbname; DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = 1; OPEN cur; REPEAT FETCH cur INTO oldname; SET @newname = UPPER(oldname); SET @isNotSame = @newname <> BINARY oldname; IF NOT done && @isNotSame THEN SET @SQL = CONCAT('rename table `',oldname,'` to `', LOWER(@newname), '_tmp` '); PREPARE tmpstmt FROM @SQL; EXECUTE tmpstmt; SET @SQL = CONCAT('rename table `',LOWER(@newname),'_tmp` to `',@newname, '`'); PREPARE tmpstmt FROM @SQL; EXECUTE tmpstmt; DEALLOCATE PREPARE tmpstmt; END IF; UNTIL done END REPEAT; CLOSE cur; END// DELIMITER ; |
View Details
DQL、DML、DDL、DCL的概念与区别
SQL(Structure Query Language)语言是数据库的核心语言。 SQL的发展是从1974年开始的,其发展过程如下: 1974年—--由Boyce和Chamberlin提出,当时称SEQUEL。 1976年—--IBM公司的Sanjase研究所在研制RDBMS SYSTEM R 时改为SQL。 1979年—--ORACLE公司发表第一个基于SQL的商业化RDBMS产品。 1982年—--IBM公司出版第一个RDBMS语言SQL/DS。 1985年—--IBM公司出版第一个RDBMS语言DB2。 1986年—--美国国家标准化组织ANSI宣布SQL作为数据库工业标准。 SQL是一个标准的数据库语言,是面向集合的描述性非过程化语言。 它功能强,效率高,简单易学易维护(迄今为止,我还没见过比它还好 学的语言)。然而SQL语言由于以上优点,同时也出现了这样一个问题: 它是非过程性语言,即大多数语句都是独立执行的,与上下文无关,而 绝大部分应用都是一个完整的过程,显然用SQL完全实现这些功能是很困 难的。所以大多数数据库公司为了解决此问题,作了如下两方面的工作: (1)扩充SQL,在SQL中引入过程性结构;(2)把SQL嵌入到高级语言中, 以便一起完成一个完整的应用。 二. SQL语言的分类 SQL语言共分为四大类:数据查询语言DQL,数据操纵语言DML,数据定义语言DDL,数据控制语言DCL。 1. 数据查询语言DQL 数据查询语言DQL基本结构是由SELECT子句,FROM子句,WHERE 子句组成的查询块: SELECT <字段名表> FROM <表或视图名> WHERE <查询条件> 2 .数据操纵语言DML 数据操纵语言DML主要有三种形式: 1) 插入:INSERT 2) 更新:UPDATE 3) 删除:DELETE 3. 数据定义语言DDL 数据定义语言DDL用来创建数据库中的各种对象—--表、视图、 索引、同义词、聚簇等如: CREATE TABLE/VIEW/INDEX/SYN/CLUSTER | | | | | 表 视图 索引 同义词 簇 DDL操作是隐性提交的!不能rollback 4. 数据控制语言DCL 数据控制语言DCL用来授予或回收访问数据库的某种特权,并控制 数据库操纵事务发生的时间及效果,对数据库实行监视等。如: 1) GRANT:授权。 2) ROLLBACK [WORK] TO [SAVEPOINT]:回退到某一点。 回滚—ROLLBACK 回滚命令使数据库状态回到上次最后提交的状态。其格式为: SQL>ROLLBACK; 3) COMMIT [WORK]:提交。 在数据库的插入、删除和修改操作时,只有当事务在提交到数据 库时才算完成。在事务提交前,只有操作数据库的这个人才能有权看 […]
View DetailsERROR 1227 (42000): Access denied; you need (at least one of) the SUPER privilege(s) for this operation
开启super权限: 1. update user set Super_priv=‘Y’ where User=‘root’ 2. flush privileges from:https://www.cnblogs.com/xiaoit/p/4415754.html
View Details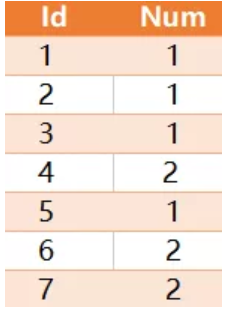
【每日一题】SQL 知识大测验 | 持续更新
每天更新一题 让大家在休息时间可以轻松学习! 下面是关于SQL的题目,每日更新~ (PS:大家要看清题号回答哦~需要答案的同学可以在下方留言题号,第一时间回复答案) 33.(2020年1月10日) 有如下一张表Orders 查询出每个发货单号(shipid),最早付款时间(paydate)和最小付款单号(payno) 结果如下: 考点:聚合函数和关联的灵活使用 32.(2020年1月9日) 表 point 保存了一些点在 X 轴上的坐标,这些坐标都是整数。 写一个查询语句,找到这些点中最近两个点之间的距离。 最近距离显然是 '1' ,是点 '-1' 和 '0' 之间的距离。所以输出应该如下: 注意:每个点都与其他点坐标不同,表 table 不会有重复坐标出现。 考点:题目看似简单,谨防陷阱 32.(2020年1月8日) 怎么把下面的表(tab) 查成这样1个结果 考点:行列转换 31.(2020年1月7日) 有如下一组数据 求出NAME中每组累加/每组总数的比例大于0.6的ID和NAME 预期的结果应该为 解释:从题目意思可以看出A组的总数为16,从ID为1到5分别累加后的结果分别为1,3,9,13,16,只有13和16除以总数16才大于0.6,所以返回的结果ID为4和5,同样B组为7和8 30.(2020年1月6日) 有如下一张 Activity 表: 其中games_played是玩家登陆玩的游戏数量, 查询每个玩家每天累计玩的游戏数量有多少?结果如下: 解释:玩家1第一次玩了5个,所以是5,第二次是6个,所以累计就是5+6=11, 第三次是1个,累计就是5+6+1=12 玩家2类似 29.(2020年1月3日) 写一条 SQL 查询语句,从 Customer 表中查询购买了 Product 表中所有产品的客户的 id。示例:Customer 表: Product 表: Result 表: 购买了所有产品(5 和 6)的客户的 id 是 1 和 3 。 28.(12月31日) 有如下几张表: Student Course SC 查询"01 "课程比" 02 "课程成绩高的学生的信息及课程分数? P.S. 题目较简单,希望大家能动手练习一下,锻炼自己逻辑思维能力。 27.(12月30日) 有一张成绩表SC,表结构为SC(StuID,CID,Course),分部对应是学生ID,课程ID和学生成绩,有如下测试数据 查询出既学过’001’课程,也学过’003’号课程的学生ID 预期结果为 26.(12月27日) 表 orders 定义如下:order_id(订单编号),customer_id(客户编号),order_date(下单日期) 有如下几条记录: […]
View Detailslinux系统下MySQL表名区分大小写问题
问题如下: 比如上图中的PERSON表,查询SQL语句中如果表名是小写,就会报错说person表不存在。 因为Linux环境下的MySQL数据库的表名默认是区分大小写的,可以查看Linux上的MySQL的配置文件/etc/my.cnf:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
[root@VM_219_131_centos tomcat7]# cat /etc/my.cnf [mysqld] datadir=/var/lib/mysql socket=/var/lib/mysql/mysql.sock user=mysql # Disabling symbolic-links is recommended to prevent assorted security risks symbolic-links=0 [mysqld_safe] log-error=/var/log/mysqld.log pid-file=/var/run/mysqld/mysqld.pid [root@VM_219_131_centos tomcat7]# |
如果要使用数据库表名不区分大小写的话,就需要在[mysqld]下面添加一行配置,即 lower_case_table_names=1:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
[root@VM_219_131_centos tomcat7]# vi /etc/my.cnf [mysqld] lower_case_table_names=1 datadir=/var/lib/mysql socket=/var/lib/mysql/mysql.sock user=mysql # Disabling symbolic-links is recommended to prevent assorted security risks symbolic-links=0 [mysqld_safe] log-error=/var/log/mysqld.log pid-file=/var/run/mysqld/mysqld.pid |
网上对该项配置的说明:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
lower_case_table_names参数详解: 其中 0:区分大小写,1:不区分大小写 MySQL在Linux下数据库名、表名、列名、别名大小写规则是这样的: 1、数据库名与表名是严格区分大小写的; 2、表的别名是严格区分大小写的; 3、列名与列的别名在所有的情况下均是忽略大小写的; 4、变量名也是严格区分大小写的; MySQL在Windows下都不区分大小写。 3、如果想在查询时区分字段值的大小写,则:字段值需要设置BINARY属性,设置的方法有多种: A、创建时设置: CREATE TABLE T( A VARCHAR(10) BINARY ); B、使用alter修改: ALTER TABLE`tablename` MODIFY COLUMN `cloname` VARCHAR(45) BINARY; C、mysql tableeditor中直接勾选BINARY项。 |
修改完配置之后,一定要重启数据库:
|
1 2 3 |
[root@VM_219_131_centos tomcat7]# service mysqld restart Stopping mysqld: [ OK ] Starting mysqld: [ OK ] |
然后使用Navicat工具重新连接MySQL数据库,再次查询perosn表,这时发现不管查询SQL语句中的表名是大写还是小写都提示找不到person表了。 原因是修改配置之后,会导致原来的大写的表名PERSON无法识别,所以这一点要特别注意。 解决办法是: (1)在修改配置之前一定先将所有表的表结构和表数据导出做备份; (2)删除原来的表; (3)修改配置; (4)将表结构和表数据导入。 按照上面的步骤操作之后,再次查询person表,表名就不区分大小写了。 from:https://www.cnblogs.com/jun1019/p/7073227.html
View DetailsCentos7安装 mariadb 最新版
为什么要写这个呢,需要单独 mariadb 客户端时,发现 默认 mariadb 5.x 没有客户端,又不想安装全部的 mariadb server,所以写了么这个一个 通过官网查看 https://mariadb.org/ 或 https://yum.mariadb.org/ 最新版为 10.4.x fox.风 设置数据源 这里使用的是国内源 http://mirrors.aliyun.com/mariadb/yum/10.4/centos7-amd64/
|
1 2 3 4 5 6 7 8 |
cat <<EOF > /etc/yum.repos.d/mariadb.repo [mariadb] name = MariaDB baseurl = http://mirrors.aliyun.com/mariadb/yum/10.4/centos7-amd64/ gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB enabled=1 gpgcheck=1 EOF |
复制到 终端直接执行 更新缓存
|
1 2 3 |
yum clean all yum makecache yum repolist |
显示可安装的版本
|
1 2 3 4 |
#这个可以看版本号 yum search mariadb --showduplicates 或 yum search mariadb |
安装 现在安装的就是 最新的版本了
|
1 |
yum -y install MariaDB-server MariaDB-client |
命令 设置开机启动
|
1 |
systemctl enable mariadb |
启动 mariadb
|
1 |
systemctl start mariadb |
from:https://blog.csdn.net/fenglailea/article/details/92265661
View Details