Category Archives: PHP
array_slice() 函数
定义和用法 array_slice() 函数在数组中根据条件取出一段值,并返回。 注释:如果数组有字符串键,所返回的数组将保留键名。(参见例子 4) 语法
|
1 |
array_slice(<i>array</i>,<i>offset</i>,<i>length</i>,<i>preserve</i>) |
参数 描述 array 必需。规定输入的数组。 offset 必需。数值。规定取出元素的开始位置。 如果是正数,则从前往后开始取,如果是负值,从后向前取 offset 绝对值。 length 可选。数值。规定被返回数组的长度。 如果 length 为正,则返回该数量的元素。 如果 length 为负,则序列将终止在距离数组末端这么远的地方。 如果省略,则序列将从 offset 开始直到 array 的末端。 preserve 可选。可能的值: true – 保留键 false – 默认 – 重置键 例子 1
|
1 2 3 4 |
<?php $a=array(0=>"Dog",1=>"Cat",2=>"Horse",3=>"Bird"); print_r(array_slice($a,1,2)); ?> |
输出:
|
1 |
Array ( [0] => Cat [1] => Horse ) |
例子 2 带有负的 offset 参数:
|
1 2 3 4 |
<?php $a=array(0=>"Dog",1=>"Cat",2=>"Horse",3=>"Bird"); print_r(array_slice($a,-2,1)); ?> |
输出:
|
1 |
Array ( [0] => Horse ) |
例子 3 preserve 参数设置为 true:
|
1 2 3 4 |
<?php $a=array(0=>"Dog",1=>"Cat",2=>"Horse",3=>"Bird"); print_r(array_slice($a,1,2,true)); ?> |
输出:
|
1 |
Array ( [1] => Cat [2] => Horse ) |
例子 4 带有字符串键:
|
1 2 3 4 |
<?php $a=array("a"=>"Dog","b"=>"Cat","c"=>"Horse","d"=>"Bird"); print_r(array_slice($a,1,2)); ?> |
输出:
|
1 |
Array ( [b] => Cat [c] => Horse ) |
安装Ecshop首页出现报错:Only variables should be passed by referen
出现下面这就话:
|
1 2 3 |
<span style="color: #ed1c24;">Strict Standards: Only variables should be passed by reference in D:\wamp\ecshop\includes\cls_template.php on line 406</span> <wbr /> 第406行:<span style="color: #fd1856;">$tag_sel = array_shift(explode(' ', $tag));</span> |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
<span style="color: #0a07ff;">解决办法 1 </span> 5.3以上版本的问题,应该也和配置有关 只要406行把这一句拆成两句就没有问题了 $tag_sel = array_shift(explode(' ', $tag)); 改成: $tag_arr = explode(' ', $tag); $tag_sel = array_shift($tag_arr); <wbr /> <span style="color: #ed1c24;">(实验过,绝对可行) </span>因为array_shift的参数是引用传递的,5.3以上默认只能传递具体的变量,而不能通过函数返回值 <span style="color: #0a07ff;">解决办法 2 :</span> 或则如果这样配置的话: error_reporting = E_ALL | E_STRICT from:<a href="http://blog.sina.com.cn/s/blog_7dc986fc01013acp.html">http://blog.sina.com.cn/s/blog_7dc986fc01013acp.html</a> |
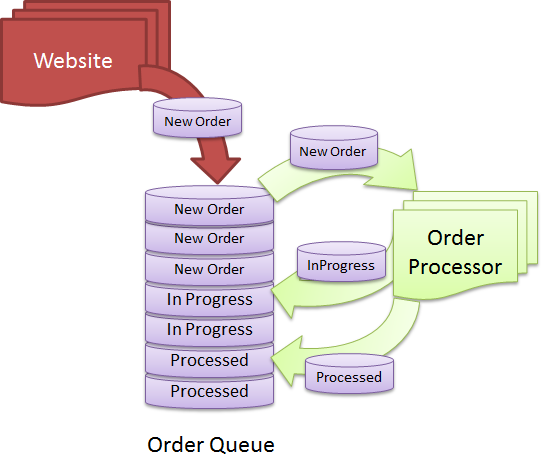
使用数据库构建高性能队列用于存储订单、通知和任务
引言 几乎在每个地方都能用到队列。在许多web站点里,比如其中的email和SMS都是使用队列来异步发送通知。电子商务网站都是使用队列来存储订单,处理订单以及实现订单的分发。工厂生产线的自动化系统也是使用队列来按某种顺序运行并发工作任务的。队列是使用很广泛的一种数据结构,它有时可以创建在数据库里,而不是使用类似于MSMQ那样的特定的队列技术创建。使用数据库技术来运行一个高性能且高可扩展性的队列对我们来说是一个巨大的挑战。当每天进入队列和从队列中提取的信息达到数百万行的时候,这个队列就很难维护了。我将向你展示在设计类似队列表时常犯的设计错误以及如何使用简单的数据库功能实现队列的最大性能和强大的可扩展性。 几点人 翻译于 5天前 0人顶 顶 翻译的不错哦! 首先让我们明确在队列表中遇到的挑战: 表的读写。在大负载下,入队列和出队列是相互影响而引起锁的竞争、事务死锁、IO超时等等。 当多个接收者试图从同一队列读数据时,它们随机地获取重复项,从而导致重复的处理过程。你需要在队列上实现一些高性能的行锁以至于并发接受器不会接收相同的数据项。 队列表需要以特定的顺序去存储行、以特定的顺序读取行数据,这是一个索引设计的挑战。尽管并不总是先进先出。间或顺序有较高的优先级,无论何时入栈都需要进行处理。 队列表需要以序列化的XML对象或者二进制形式存储, 这带来了存储和索引重建的挑战。由于数据表包含文本和/或二进制,所以你不能在队列表上重建索引。因此队列表每天变的越来越慢,最终查询开始时间超时,最后你不得不关闭服务并重建索引。 出队列的过程中,一批行数据被选中、更新,然后重新处理。你需要一个"State"列定义数据项的状体。出队列时,你只选择特定状态的数据项。现在State只是一个包含PENDING、PROCESSING、PROCESSED、ARCHIVED等元素的集合。结果是你不能在"State"列上创建索引,原因是安全性差。队列中可以有成千上万行具有相同的状态。因此 任何由扫面索引的出队列操作都会导致CPU和IO资源紧张以及锁竞争。 在出队列过程中,你不只是从表中移出行,原因是容易引起存储残片。进而,你需要重新订单/任务/通知N次以防止他们在第一次尝试中失败。这意味着行数据需要更长的存储周期、索引持续增长和出队列越来越慢。 你不得不归档以队列表中处理过的数据项到不同的表或者数据库,以保持主队列表的精简。这意味着需要移动大量的具有特殊状态的行到另一个数据库。大量的数据移动产生了的存储碎片,而表的高频度碎片整理降低入栈和出栈的性能。 你需要24X7的工作。你不可能关闭服务而归档大量行数据。这意味者在不影响入栈和出栈,你不得不持续的归档行数据。 如果您已实现这样的队列表,你可能已经遇到了以上挑战中的一个或者更多。本文将给你一个关于如何克服这些挑战的一些技巧,以及如何设计和维护一个高性能的队列表。 漠天 翻译于 4天前 0人顶 顶 翻译的不错哦! SQL Server典型队列 下面以常见的队列类型为例,看看在并发负载时的情况. 01 CREATE TABLE [dbo].[QueueSlow]( 02 [QueueID] [int] IDENTITY(1,1) NOT NULL, 03 [QueueDateTime] [datetime] NOT NULL, 04 [Title] [nvarchar](255) NOT NULL, 05 [Status] [int] NOT NULL, 06 [TextData] [nvarchar](max) NOT NULL 07 ) ON [PRIMARY] 08 GO 09 CREATE UNIQUE CLUSTERED INDEX [PK_QueueSlow] ON [dbo].[QueueSlow] 10 ( 11 [QueueID] ASC 12 ) 13 GO 14 CREATE NONCLUSTERED INDEX [IX_QuerySlow] ON [dbo].[QueueSlow] 15 ( 16 [QueueDateTime] ASC, 17 [Status] ASC 18 ) 19 INCLUDE ( [Title]) 20 GO 该队列中使用QueueDateTime排序来模拟先进先出的队列结构 . QueueDateTime不一定非得是对象加入队列的时间,而是其将要被处理的开始时间 于是保证了先进先出的次序关系. TextData字段是为了保存进行负载测试的大字段设计的. 表中使用QueueDateTime 的非聚簇索引以加速队列操作速度 首先,插入大约4万行大约500兆数据量的记录,其中每行的负载数大小各不相同. 01 set nocount on 02 declare @counter int 03 set @counter = 1 04 while @counter < @BatchSize 05 begin 06 insert into [QueueSlow] (QueueDateTime, Title, Status, TextData) 07 select GETDATE(), 'Item no: ' + CONVERT(varchar(10), @counter), 0, […]
View DetailsMagicZoom bug-Strict Standards: Only variables should be assigned by
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 |
问题: zencart Strict standards: Only variables should be assigned by reference in jscript_zen_magiczoomplus.php 将符号&去掉就可以了 http://stackoverflow.com/questions/11777908/strict-standards-only-variables-should-be-assigned-by-reference-php-5-4 看手册第15章: 引用是什么 在 PHP 中引用意味着用不同的名字访问同一个变量内容。这并不像 C 的指针,它们是符号表别名。注意在 PHP 中,变量名和变量内容是不一样的,因此同样的内容可以有不同的名字。最接近的比喻是 Unix 的文件名和文件本身 - 变量名是目录条目,而变量内容则是文件本身。引用可以被看作是 Unix 文件系统中的紧密连接。 引用做什么 PHP 的引用允许你用两个变量来指向同一个内容。意思是,当你这样做时: <?php $a =& $b ?> 这意味着 $a 和 $b 指向了同一个变量。 注: $a 和 $b 在这里是完全相同的,这并不是 $a 指向了 $b 或者相反,而是 $a 和 $b 指向了同一个地方。 同样的语法可以用在函数中,它返回引用,以及用在 new 运算符中(PHP 4.0.4 以及以后版本): <?php $bar =& new fooclass(); $foo =& find_var ($bar); ?> 注: 不用 & 运算符导致对象生成了一个拷贝。如果你在类中用 $this,它将作用于该类当前的实例。没有用 & 的赋值将拷贝这个实例(例如对象)并且 $this 将作用于这个拷贝上,这并不总是想要的结果。由于性能和内存消耗的问题,通常你只想工作在一个实例上面。 尽管你可以用 @ 运算符来关闭构造函数中的任何错误信息,例如用 @new,但用 &new 语句时这不起效果。这是 Zend 引擎的一个限制并且会导致一个解析错误。 引用做的第二件事是用引用传递变量。这是通过在函数内建立一个本地变量并且该变量在呼叫范围内引用了同一个内容来实现的。例如: <?php function foo (&$var) { $var++; } $a=5; foo ($a); ?> 将使 $a 变成 6。这是因为在 foo 函数中变量 $var 指向了和 $a 指向的同一个内容。更多详细解释见引用传递。 引用做的第三件事是引用返回。 引用不是什么 如前所述,引用不是指针。这意味着下面的结构不会产生你预期的效果: <?php function foo (&$var) { $var =& $GLOBALS["baz"]; } foo($bar); ?> 这将使 foo 函数中的 $var 变量在函数调用时和 $bar 绑定在一起,但接着又被重新绑定到了 $GLOBALS["baz"] 上面。不可能通过引用机制将 $bar 在函数调用范围内绑定到别的变量上面,因为在函数 foo 中并没有变量 $bar(它被表示为 $var,但是 $var 只有变量内容而没有调用符号表中的名字到值的绑定)。 引用传递 你可以将一个变量通过引用传递给函数,这样该函数就可以修改其参数的值。语法如下: <?php function foo (&$var) { $var++; } $a=5; foo ($a); // $a is 6 here ?> 注意在函数调用时没有引用符号 - 只有函数定义中有。光是函数定义就足够使参数通过引用来正确传递了。 以下内容可以通过引用传递: 变量,例如 foo($a) New 语句,例如 foo(new foobar()) 从函数中返回的引用,例如: <?php function &bar() { $a = 5; return $a; } foo(bar()); ?> 详细解释见引用返回。 任何其它表达式都不能通过引用传递,结果未定义。例如下面引用传递的例子是无效的: <?php function bar() // Note the missing & { $a = 5; return $a; } foo(bar()); foo($a = 5) // 表达式,不是变量 foo(5) // 常量,不是变量 ?> 这些条件是 PHP 4.0.4 以及以后版本有的。 引用返回 引用返回用在当你想用函数找到引用应该被绑定在哪一个变量上面时。当返回引用时,使用此语法: <?php function &find_var ($param) { /* ...code... */ return $found_var; } $foo =& find_var ($bar); $foo->x = 2; ?> 本例中 find_var 函数所返回的对象的属性将被设定(译者:指的是 $foo->x = 2; 语句),而不是拷贝,就和没有用引用语法一样。 注: 和参数传递不同,这里必须在两个地方都用 & 符号 - 来指出返回的是一个引用,而不是通常的一个拷贝,同样也指出 $foo 是作为引用的绑定,而不是通常的赋值。 取消引用 当你 unset 一个引用,只是断开了变量名和变量内容之间的绑定。这并不意味着变量内容被销毁了。例如: <?php $a = 1; $b =& $a; unset ($a); ?> 不会 unset $b,只是 $a。 再拿这个和 Unix 的 unlink 调用来类比一下可能有助于理解。 引用定位 许多 PHP 的语法结构是通过引用机制实现的,所以上述有关引用绑定的一切也都适用于这些结构。一些结构,例如引用传递和返回,已经在上面提到了。其它使用引用的结构有: global 引用 当用 global $var 声明一个变量时实际上建立了一个到全局变量的引用。也就是说和这样做是相同的: <?php $var =& $GLOBALS["var"]; ?> 这意味着,例如,unset $var 不会 unset 全局变量。 $this 在一个对象的方法中,$this 永远是调用它的对象的引用。 <?php /** * (C) CopyRight 2008 MagicToolBox - www.magictoolbox.com - support@magictoolbox.com **/ require_once(DIR_FS_CATALOG . DIR_WS_MODULES . 'magictoolbox/magictoolbox_addons.php'); $mod = magictoolboxLoadModule('MagicZoomPlus'); $enabled = false; $main_page = isset($_REQUEST['main_page']) ? $_REQUEST['main_page'] : $_GET['main_page']; $cPath = isset($_REQUEST['cPath']) ? $_REQUEST['cPath'] : $_GET['cPath']; $products_id = isset($_REQUEST['products_id']) ? $_REQUEST['products_id'] : $_GET['products_id']; $scroll = false; if($mod->type == 'standard' && !$mod->params->checkValue('template', 'original') && $mod->params->checkValue('magicscroll', 'yes')) { $scroll = magictoolboxLoadModule('magicscroll'); $scroll->params->appendArray($mod->params->getArray()); $scroll->params->set('direction', $mod->params->checkValue('template', array('left', 'right')) ? 'bottom' : 'right'); } if(ZEN_MAGICZOOMPLUS_STATUS == 'true') { $enable_on_block = !$mod->params->checkValue('use-effect-on-whats-new-block', 'No') || !$mod->params->checkValue('use-effect-on-specials-block', 'No') || !$mod->params->checkValue('use-effect-on-featured-block', 'No'); if($mod->type == 'standard') { if( (intval($cPath) > 0 && (!$mod->params->checkValue('use-effect-on-category-page', 'No') || $enable_on_block)) || // category page (intval($products_id) > 0 && (!$mod->params->checkValue('use-effect-on-product-page', 'No') || $enable_on_block)) || // product page ($main_page == 'products_new' && (!$mod->params->checkValue('use-effect-on-products-new-page', 'No') || $enable_on_block)) || ($main_page == 'products_all' && (!$mod->params->checkValue('use-effect-on-products-all-page', 'No') || $enable_on_block)) || ($main_page == 'advanced_search_result' && (!$mod->params->checkValue('use-effect-on-products-search-page', 'No') || $enable_on_block)) ) { $enabled = true; } } elseif($mod->type == 'category' || $mod->type == 'circle') { if( (intval($products_id) > 0 && (!$mod->params->checkValue('use-effect-on-product-page', 'No') || $enable_on_block)) || // product page (intval($cPath) > 0 && $enable_on_block) || // category page ($main_page == 'products_new' && $enable_on_block) || ($main_page == 'products_all' && $enable_on_block) || ($main_page == 'advanced_search_result' && $enable_on_block) ) { $enabled = true; } } } if (!$GLOBALS["MAGICZOOMPLUS_HEADERS_LOADED"] && $enabled) { echo $mod->headers(DIR_WS_CATALOG . DIR_WS_TEMPLATE . 'jscript', DIR_WS_CATALOG . DIR_WS_TEMPLATE . 'css'); if($scroll) { echo $scroll->headers(DIR_WS_CATALOG . DIR_WS_TEMPLATE . 'jscript', DIR_WS_CATALOG . DIR_WS_TEMPLATE . 'css'); } $GLOBALS["MAGICZOOMPLUS_HEADERS_LOADED"] = true; } from:<a href="http://www.cnblogs.com/awinlei/archive/2013/03/13/2957058.html">http://www.cnblogs.com/awinlei/archive/2013/03/13/2957058.html</a> |
PHP配置文件详解php.ini
[PHP] ; PHP还是一个不断发展的工具,其功能还在不断地删减 ; 而php.ini的设置更改可以反映出相当的变化, ; 在使用新的PHP版本前,研究一下php.ini会有好处的 ;;;;;;;;;;;;;;;;;;; ; 关于这个文件 ; ;;;;;;;;;;;;;;;;;;; ; 这个文件控制了PHP许多方面的观点。为了让PHP读取这个文件,它必须被命名为 ; 'php.ini’。PHP 将在这些地方依次查找该文件:当前工作目录;环境变量PHPRC ; 指明的路径;编译时指定的路径。 ; 在windows下,编译时的路径是Windows安装目录。 ; 在命令行模式下,php.ini的查找路径可以用 -c 参数替代。 ; 该文件的语法非常简单。空白字符和用分号';’开始的行被简单地忽略(就象你可能 ; 猜到的一样)。 章节标题(例如 : [Foo])也被简单地忽略,即使将来它们可能 ; 有某种的意义。 ; ; 指示被指定使用如下语法: ; 指示标识符 = 值 ; directive = value ; 指示标识符 是 *大小写敏感的* – foo=bar 不同于 FOO = bar。 ; ; 值可以是一个字符串,一个数字,一个 PHP 常量 (如: E_ALL or M_PI), INI 常量中的 ; 一个 (On, Off, True, False, Yes, No and None) ,或是一个表达式 ; (如: E_ALL & ~E_NOTICE), 或是用引号括起来的字符串(" foo" ). ; ; INI […]
View DetailsPHP输出中文乱码的问题
用echo输出的中文显示成乱码, 其实应该是各种服务器脚本都会遇到这个问题, 根本还是编码问题, 一般来说出于编码兼容考虑大多的页面都将页面字符集定义为utf-8 <meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /> 这时候要正常显示中文需要转化一下编码方式,比如 echo iconv("GB2312","UTF-8",’中文');就不会乱码了 还有其他方法,比如 在php的echo前面加入header("Content-Type:text/html;charset=gb2312"); 当然简体中文页面也可以干脆地, 把<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />中的UTF-8改成gb2312 实际中遇见奇怪的现象, 在本机服务器上正常显示的页面,传上服务器就echo出来乱码, 没仔细琢磨过这个缘由,因为通过iconv函数GB2312、UTF-8换换位置重新编码下就正常了, 不过估计肯定是APACHE,更确切说是PHP服务端的设置不同造成的, 看看PHP.INI应该就能解决。 from:http://www.cnblogs.com/leandro/archive/2008/04/21/1368517.html
View Detailsimport_request_variables
|
1 2 3 4 5 6 7 8 9 10 11 12 |
(PHP 4 >= 4.1.0, PHP 5 < 5.4.0) // 确保你的php版本在这个范围 import_request_variables — 将 GET/POST/Cookie 变量导入到全局<a href="http://zhidao.baidu.com/search?word=%E4%BD%9C%E7%94%A8%E5%9F%9F&fr=qb_search_exp&ie=utf8" target="_blank" rel="nofollow" data-word="0">作用域</a>中 ---------------------------------------------------------------------------------- 替换方法: For example: import_request_variables('pg', 'import_'); Can be replaced with: extract($_REQUEST, EXTR_PREFIX_ALL|EXTR_REFS, 'import'); from:<a href="http://zhidao.baidu.com/link?url=kWGxuMZBz9vRV5UbTPeCawaGMFVy52ihNhyUFgN3MDkRpgReRTESLggk2PqJeUFOZhWFebQi0ofiwc_qYeOKJq">http://zhidao.baidu.com/link?url=kWGxuMZBz9vRV5UbTPeCawaGMFVy52ihNhyUFgN3MDkRpgReRTESLggk2PqJeUFOZhWFebQi0ofiwc_qYeOKJq</a> |
禁止浏览器缓存
html: <meta http-equiv="pragma" content="no-cache"> <meta http-equiv="cache-control" content="no-store, must-revalidate"> <meta http-equiv="expires" content="wed, 26 feb 1997 08:21:57 gmt"> <meta http-equiv="expires" content="0"> asp response.expires=0 response.addheader("pragma","no-cache") response.addheader("cache-control","no-store, must-revalidate") php header("expires: mon, 26 jul 1997 05:00:00 gmt"); header("cache-control: no-store, must-revalidate"); header("pragma: no-cache"); jsp: response.addheader("cache-control", "no-store, must-revalidate"); response.addheader("expires", "thu, 01 jan 1970 00:00:01 gmt"); 转自:http://www.oschina.net/code/snippet_81226_7660
View Details
2014 年 15 款新评定的最佳 PHP 框架
通常,框架都会被认为是帮助开发者快速设计和开发动态网站的软件应用。每个月都有极大数量的新发布的 PHP 框架,使网站开发更简单更高效。 如果你是位 PHP 开发者,正在寻找当前最好的一些 PHP 框架来帮助开发你的项目,那么这里正是你要找的地方。在这篇文章我们会介绍 15 款最好的 PHP 框架,这些框架都是最新评定的,可以大大的简化你的开发任务。这些 PHP 框架可以帮助开发者快速设计和开发各种跨浏览器的动态网站和 web 应用,最后,希望你能在这些列表中找到你想要的 PHP 框架,Enjoy !! 1. Yaf : Yet Another Framework Yaf 是第一个 PHP MVC 框架,用 C 语言编写,作为 PHP 的扩展来创建的。它被认为是最快和最低资源消耗的 PHP 框架,经过了良好的测试,并且现在已经很成功的应用在很多 web 项目上。 2. Nette Framework Nette Framework 是个现代化风格的 PHP 框架,对安全进行了革命性的改进,使用面向对象的设计理念,非一般的性能表现和超级简单的学习曲线。除了这些之外,它还有个非常活跃的社区,给予用户足够的灵活性。 3. Guzzle Guzzle 是个 PHP 框架,又是个 PHP HTTP 客户端,用来创建 RESTful web 服务客户端。它的主要特性是通过服务描述快速创建客户端;尽可能高效的批量发送大量的请求;持久性连接和并行请求;其他更多的功能。 4. Behat Behat 是个行为驱动的开发(BDD)框架,允许用户编写便于人们阅读的故事驱动代码,描述该应用应该怎样工作。任何人都能快速简单的掌握它的使用方法。 5. Phalcon Phalcon 实现了 C 的扩展,是个高性能,低能耗 PHP框架。它包括一个模版引擎,加密,分页,assets 管理和其他更多的工具。 6. Flight Flight 是个快速,简单,可扩展的 PHP 框架,允许用户快速简单的创建 RESTful web 应用。 7. Webasyst Webasyst 是个开源的 PHP 框架,用来开发时尚的多用户 web 应用和高级的网站。相对比其他框架,比如Zend 和 Symfony,它更注重于构建商业和给团队使用的 web 应用,更快更高效。 8. Medoo Medoo 是个轻量级的 PHP 数据库框架,帮助用户快速开发 web […]
View Details