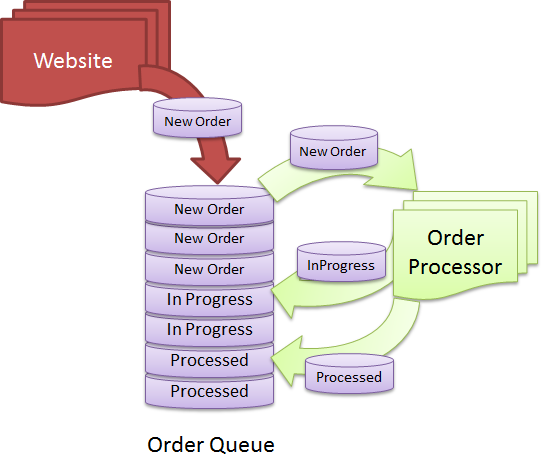
使用数据库构建高性能队列用于存储订单、通知和任务
|
|
几点人
|
|
首先让我们明确在队列表中遇到的挑战:
如果您已实现这样的队列表,你可能已经遇到了以上挑战中的一个或者更多。本文将给你一个关于如何克服这些挑战的一些技巧,以及如何设计和维护一个高性能的队列表。 |
漠天
|
SQL Server典型队列下面以常见的队列类型为例,看看在并发负载时的情况.
该队列中使用QueueDateTime排序来模拟先进先出的队列结构 . QueueDateTime不一定非得是对象加入队列的时间,而是其将要被处理的开始时间 于是保证了先进先出的次序关系. TextData字段是为了保存进行负载测试的大字段设计的. 表中使用QueueDateTime 的非聚簇索引以加速队列操作速度 首先,插入大约4万行大约500兆数据量的记录,其中每行的负载数大小各不相同.
|
petert
|
|
接下来我们将一次性出队10个元素。在出队的时候,它会根据QueueDateTime 和Status = 0进行判断,它将会Status更新为1表示该元素正在被处理。当出队的时候我们并不会从缓存表中删除这行数据,因为我们想保证这些元素在处理失败的时候永远不会丢失。
上面的查询将会从QueueSlow 表中取出10行数据,然后存储在临时表中。紧接着改变选中的记录的状态以保证其他的会话不会再次提取数据。如果能够更新10行记录并且没有被其他的会话占有,那么久可以提交该事务,意味着将会将他们的状态标记为已完成,没有子过程进行调用。反之,其他的会话可以更新,事务将会拒绝被提交以保证事务的一致性 |
beyondme
|
|
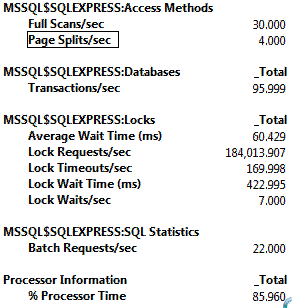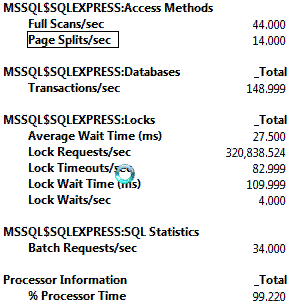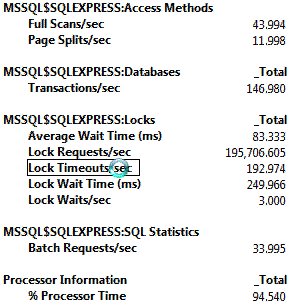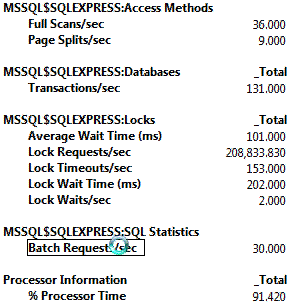
让我测量下IO性能:
输出如下:
概括如下:
我们将用最快的方式进行标记看性能到底提升了多少。这里我们需要注意的是 LOB Logical Read和 LOB Logical Read 的访问次数得到改善。读三次数据是非常有必要的,因为我们需要重新载入数据。这很清楚的表明SQL Server没有必要读取大对象以满足查询。 经常产生出队和入队,使得许多的行被移除表进行归档,数据表逐渐变成碎片,你不能在线够重建聚族索引来消除碎片引文它有varchar(max)字段。因此,你不得不选择停止服务器重建索引,停止服务器是非常耗资源的 |
beyondme
|
创建一个更快速的队列第一,你必须降低比较过的逻辑读取。所以你只能将QueueSlow进行拆分为两张表-QueueMeta ,QueueData。QueueData只包含参与where子句的字段。他是一张很小的表只用于保存查询。使得SQL Server必须修正几行数据占据8K的页然后再运行, 这样的表会比表QueueSlow运行的更快。 第二,你能够在线重建QueueMeta 的索引,当其事务还在进行的时候。这样的话,QueueMeta表的性能将被不会降低,你再也不用担心停止服务器进行索引重建了。
|
beyondme
|
|
这个表保留了出现在搜索查询中的所有的字段。其他所有和有效负载相关的字段被移到了QueueData表。
在这个表中没有聚类索引项。“Dequeue”过程先被简单的修改后去执行QueueMeta表上的查询操作,然后从QueueData表中选择有效负载。
当把在QueueSlow提取的相同数据填充到QueueMeta和QueueData表中,然后重建两个表的索引并作对比,分析发现有明显的提高:
你会看到逻辑读的次数低于149;LOB读取低于295;LOB读取计数为1,以上数据正式我们期待的。 |
漠天
|
负载下的性能比较当我模拟并发队列和出队列,并且测量性能计数器,结果如下所示:
让我们来分析这些重要的计数器,看看有哪些改进:
这不仅仅是有更好的性能,最大的好处是你可以在QueueMeta表在线运行INDEX DEFRAG,从而阻止Queue逐渐放缓。 |
FGQ
|

在SQL Server 2005,2008里实现的最快队列SQL Server 2005给 下面从队列获取信息的过程是修改过的:
一行
与较快队列的解决方案相比,在IO统计方面,这种方案至少要快3倍。 |
几点人
|
队列表的归档策略当你向队列表中插入记录时,队列表的大小会一直在增长。你需要做的是要确保队列表保持合理的大小,这样就永远不会对此队列表进行备份和重建索引了。有两种方法可以进行队列消息的数据行归档-昼夜不停地进行小批量归档或者在非工作高峰时进行大批量归档。如果你运行的是24×7服务的系统,而且也没有非工作高峰时段,那么你就需要接连不断地运行小批量归档,这样的小批量归档之间稍有时延。不过,在从队列提取消息的时候,你不能删除队列表中的消息数据,因为删除操作是费时费力的操作。如果你删除队列中的数据,那么从队列提取消息的过程将会慢很多。不过,你可以通过另一个后台任务来删除队列里已经处理过的消息数据,这么做就不会降低从队列提取消息的性能。 此外,如果要求实现的是一个可靠性很高的队列,那么你就不能在从队列中提取消息的时候删除消息数据。如果处理队列消息数据的进程由于某种原因而失效,而且重新运行消息数据插入后仍然不能把这些消息数据插入到队列表里,那么这些消息数据就会永远丢失了。有时候,你需要密切关注消息队列,确保已经被提取的消息在某个时间段内得到处理。如果没有得到处理的话,那么就需要把这些消息放在队列的最前端,这样才能保证处理进程能提取到这些消息。正是由于以上这些原因,最好在从队列提取消息的时候保持这些消息数据不变,只是更改这些消息数据行的状态。 |
几点人
|
结论你的订单处理系统、任务执行系统或通知系统的性能和可靠性,取决于你如何设计你的队列。由于这些直接影响客户满意度并最终直戳你的底线,所以当你要建立你的队列时,花足够的时间做出正确的设计决策是很重要的。否则,随着时间的推移,它会成为一个债务,在你付出了失去业务和很高的资源消耗的代价之后最终仍然不得不重新设计队列。 |
from:http://www.oschina.net/translate/building-high-performance-queue-in-database-for-storing-orders