轻量级高性能ORM框架:Dapper高级玩法
Dapper高级玩法1:
数据库中带下划线的表字段自动匹配无下划线的Model字段。
备注:
这个对使用Mysql数据库的朋友最有帮助,因为Mysql默认都是小写,一般字段都带下划线,比如:user_name之类。
具体效果如下演示
1,首先创建一张表并插入数据

2,创建Model模型
|
1 2 3 4 5 6 7 8 |
public class User { public int UserID { get; set; } public string UserName { get; set; } public int RoleID { get; set; } } |
3,扩写抽取数据逻辑代码.
select * from [user]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
static Program() { var config = new ConfigurationBuilder() .SetBasePath(Directory.GetCurrentDirectory()) .AddJsonFile("appsettings.json", optional: true, reloadOnChange: true); var data = config.Build(); DapperExtension.DBConnectionString = data.GetConnectionString("DefaultConnection"); } static void Main(string[] args) { IDbConnection dbconnection = null; using (dbconnection = dbconnection.OpenConnection()) { var users = dbconnection.List("select * from [user]", null); foreach (var user in users) { Console.WriteLine($"{user.UserID}-{user.UserName}-{user.RoleID}"); } } Console.ReadKey(); } |
4,无MatchNamesWithUnderscores设置时的数据抽取
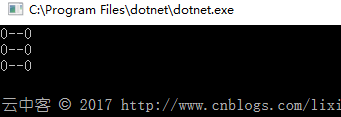
没有绑定成功??
这是因为用了Select * from的缘故,取出来的字段是带下划线的与Model的字段不匹配。
5,设置MatchNamesWithUnderscores再次数据抽取
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
static void Main(string[] args) { Dapper.DefaultTypeMap.MatchNamesWithUnderscores = true; IDbConnection dbconnection = null; using (dbconnection = dbconnection.OpenConnection()) { var users = dbconnection.List("select * from [user]", null); foreach (var user in users) { Console.WriteLine($"{user.UserID}-{user.UserName}-{user.RoleID}"); } } Console.ReadKey(); } |
数据绑定成功。
就一句Dapper.DefaultTypeMap.MatchNamesWithUnderscores = true,让我们少写了不少AS语句。
Dapper高级玩法2:
法力无边的Query,由于带有Function功能,可以自由设置模型绑定逻辑。
1,创建两张有关联的表,并填入数据。
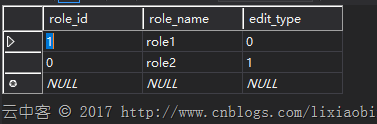
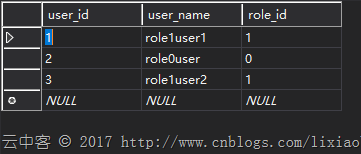
2,抽取user和它关联的role数据。
select 1 as table1,T1.*,1 as table2,T2.* from [user] T1 inner join [role] T2 on T1.role_id = T2.role_id
扩展方法:
|
1 2 3 4 |
public static IEnumerable QueryT(this IDbConnection dbconnection, string sql, Func map, object param = null, IDbTransaction transaction = null, string splitOn = "Id") { return dbconnection.Query(sql, map, param, transaction, splitOn: splitOn); } |
使用:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
static void QueryTest() { Dapper.DefaultTypeMap.MatchNamesWithUnderscores = true; IDbConnection dbconnection = null; using (dbconnection = dbconnection.OpenConnection()) { var result = dbconnection.QueryT( @"select 1 as table1,T1.*,1 as table2,T2.* from [user] T1 inner join [role] T2 on T1.role_id = T2.role_id", (user, role) => { user.Role = role; return user; }, null, splitOn: "table1,table2"); foreach (var user in result) { Console.WriteLine($"{user.UserID}-{user.UserName}-{user.Role.RoleID}-{user.Role.RoleName}"); } } Console.ReadKey(); } |
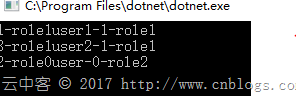
成功取到数据。
splitOn解释:模型绑定时的字段分割标志。table1到table2之间的表字段绑定到User,table2之后的表字段绑定到Role。
3,特殊Function逻辑。比如抽取role_id对应的user一览。
select 1 as table1,T1.*,1 as table2,T2.* from [role] T1 left join [user] T2 on T1.role_id = T2.role_id
外部定义了一个字典类型,Query内部模型绑定的时候每次调用Function函数,Function函数中将数据添加到外部字典中,这在复杂数据处理时很有用。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
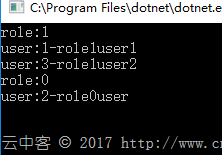
static void QueryTest2() { Dapper.DefaultTypeMap.MatchNamesWithUnderscores = true; IDbConnection dbconnection = null; using (dbconnection = dbconnection.OpenConnection()) { Dictionary> dic = new Dictionary>(); dbconnection.QueryT( @"select 1 as table1,T1.*,1 as table2,T2.* from [role] T1 left join [user] T2 on T1.role_id = T2.role_id", (role, user) => { if (dic.ContainsKey(role.RoleID)) { dic[role.RoleID].Add(user); } else { dic.Add(role.RoleID, new List { user }); } return true; }, null, splitOn: "table1,table2"); foreach (var data in dic) { Console.WriteLine($"role:{data.Key}"); foreach (var user in data.Value) { Console.WriteLine($"user:{user.UserID}-{user.UserName}"); } } } Console.ReadKey(); } |
输出结果:
今天就介绍到这,后续有时间再添加其他的玩法,个人比较喜好Dapper这种自由的写法。