Java面试准备
-
基础
-
Java相关
-
Java创建对象有几种方式?
有6种方式:使用new创建、使用反射机制、使用clone方法、使用反序列化、使用方法句柄、使用Unsafe分配内存。
-
使用new创建
1User user = new User(); -
使用反射机制
运用反射手段,调用java.lang.Class或者java.lang.reflect.Constructor类的newInstance()实例方法。
(1)使用Class类的newInstance方法可以使用Class类的newInstance方法创建对象。这个newInstance方法调用无参的构造函数创建对象。
12User user = (User)class.forName("xxx.xxx.User").newInstance();User user = User.class.newInstance();(2)使用Constructor类的newInstance方法 和Class类的newInstance方法很像,java.lang.reflect.Constructor类里也有一个newInstance方法可以创建对象。我们可以通过这个newInstance方法调用有参数的和私有的构造函数。
12Constructor constructor = User.class.getConstructor();User user = constructor.newInstance();这两种newInstance方法就是大家所说的反射。实际上Class的newInstance方法内部调用Constructor的newInstance方法。
-
使用clone方法
无论何时我们调用一个对象的clone方法,jvm就会创建一个新的对象,将签名的对象的内容全部拷贝进去。用clone方法创建对象并不会调用任何构造函数。
要使用clone方法,我们需要先实现Cloneable接口并实现其定义的clone方法。如果只实现了Cloneable接口,并没有重写clone方法的话,会默认使用Object类中的clone方法,这是一个native的方法。
1234567891011121314151617181920212223242526272829303132333435public class CloneTest implements Cloneable{private String name;private int age;public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}public CloneTest(String name, int age){super();this.name = name;this.age = age;}public static void main(String[] args) {try {CloneTest cloneTest = new CloneTest("clay", 30);CloneTest copyClone = (CloneTest) cloneTest.clone();} catch (Exception e) {e.printStackTrace();}}} -
使用反序列化
当我们序列化和反序列化一个对象,jvm会给我们创建一个单独的对象。其实反序列化也是基于反射实现的。
12345678910111213141516171819202122232425262728293031323334353637383940public class SerializeDemo {public static void main(String[] args) {// Initializes the ObjectUser1 user = new User1();user.setName("clay");user.setAge(23);System.out.println(user);// Write Obj to FileObjectOutputStream oos = null;try {oos = new ObjectOutputStream(new FileOutputStream("tempFile"));oos.writeObject(user);} catch (IOException e) {e.printStackTrace();} finally {IOUtils.closeQuietly(oos);}// Read Obj from FileFile file = new File("tempFile");ObjectInputStream ois = null;try {ois = new ObjectInputStream(new FileInputStream(file));User1 newUser = (User1) ois.readObject();System.out.println(newUser);} catch (IOException e) {e.printStackTrace();} catch (ClassNotFoundException e) {e.printStackTrace();} finally {IOUtils.closeQuietly(ois);try {FileUtils.forceDelete(file);} catch (IOException e) {e.printStackTrace();}}}} -
使用方法句柄
通过使用方法句柄,可以间接地调用构造函数来创建对象
1234567891011public static void main(String[] args) throws Throwable {// 定义构造函数的方法句柄类型为void类型,无参数MethodType constructorType = MethodType.methodType(void.class);// 获取构造函数的方法句柄MethodHandles.Lookup lookup = MethodHandles.lookup();MethodHandle constructorHandle = lookup.findConstructor(User.class, constructorType);// 使用方法句柄调用构造函数创建对象User obj = (User) constructorHandle.invoke();}使用了MethodHandles.lookup().findConstructor()方法获取构造函数的方法句柄,然后通过invoke()方法调用构造函数来创建对象。
-
使用Unsafe分配内存
在Java中,可以使用sun.misc.Unsafe类来进行直接的内存操作,包括内存分配和对象实例化。然而,需要注意的是,sun.misc.Unsafe类是Java的内部API,它并不是Java标准库的一部分,也不建议在生产环境中使用。
12345678910111213141516public static void main(String[] args) throws Exception {Field field = Unsafe.class.getDeclaredField("theUnsafe");field.setAccessible(true);Unsafe unsafe = (Unsafe) field.get(null);// 获取User类的字段偏移量long nameOffset = unsafe.objectFieldOffset(User.class.getDeclaredField("name"));long ageOffset = unsafe.objectFieldOffset(User.class.getDeclaredField("age"));// 使用allocateInstance方法创建对象,不会调用构造函数User user = (User) unsafe.allocateInstance(User.class);// 使用putObject方法设置字段的值unsafe.putObject(user, nameOffset, "clay");unsafe.putInt(user, ageOffset, 30);}这种方式有以下几个缺点:
- 不可移植性:Unsafe类的行为在不同的Java版本和不同的JVM实现中可能会有差异,因此代码在不同的环境下可能会出现不可移植的问题。
- 安全性问题:Unsafe类的功能是非常强大和危险的,可以绕过Java的安全机制,可能会导致内存泄漏、非法访问、数据损坏等安全问题。
- 不符合面向对象的原则:Java是一门面向对象的语言,鼓励使用构造函数和工厂方法来创建对象,以确保对象的正确初始化和维护对象的不变性。
-
-
-
Spring MVC相关
-
什么是SpringMVC?
Spring MVC是一个基于Java的实现了MVC设计模式的请求驱动类型的轻量级Web框架,通过把Model,View,Controller分离,将web层进行职责解耦,把复杂的web应用分成逻辑清晰的几部分,简化开发,减少出错,方便组内开发人员之间的配合。
-
Spring MVC 的优点
1.它是基于组件技术的.全部的应用对象,无论控制器和视图,还是业务对象之类的都是 java 组件.并且和Spring提供的其他基础结构紧密集成
2.不依赖于Servlet API(目标虽是如此,但是在实现的时候确实是依赖于Servlet的
3.可以任意使用各种视图技术,而不仅仅局限于JSP
4.支持各种请求资源的映射策略
5.它应是易于扩展的,支持 RESTful 风格
-
SpringMVC 工作原理?
1.用户发送请求给到前端控制器 DispatchServlet
2.DispatchServlet 收到请求后,调用HandlerMapping处理器映射器查找对应负责处理请求的 Handler
3.HandlerMapping 将找到的具体的处理器 Handler 生成处理器对象以及处理器拦截器(如果有则生成),一起返回给 DispatchServlet
4.DispatchServlet调用HandlerAdapter 处理器适配器,请求执行具体的 Handler
5.HandlerAdapter 将具体 Handler 执行返回的模型和视图返回给到 DispatchServlet
6.此时 DispatchServlet 已经得到具体的 视图名称了,然后向 ViewResolver 发起请求,请求解析视图,返回已经解析好的视图对象
7.DispatchServlet 对视图进行渲染,将 model 与view 进行渲染
8.DispatchServlet 返回响应给到用户浏览器Spring MVC的主要组件:
前端控制器 DispatcherServlet:接收请求、响应结果,相当于转发器,有了DispatcherServlet能够减少了其它组件之间的耦合度。
处理器映射器 HandlerMapping:根据请求的URL来查找Handler
处理器适配器 HandlerAdapter:负责执行Handler
处理器 Handler:处理器,需要程序员开发
视图解析器 ViewResolver:进行视图的解析,根据视图逻辑名将ModelAndView解析成真正的视图(view)
视图View:View是一个接口, 它的实现类支持不同的视图类型,如jsp,freemarker,pdf等等 -
MVC是什么?MVC设计模式的好处有哪些?
mvc是一种设计模式(设计模式就是日常开发中编写代码的一种好的方法和经验的总结)。模型(model)-视图(view)-控制器(controller),三层架构的设计模式。用于实现前端页面的展现与后端业务数据处理的分离。mvc设计模式的好处:
1.分层设计,实现了业务系统各个组件之间的解耦,有利于业务系统的可扩展性,可维护性。
2.有利于系统的并行开发,提升开发效率。
-
SpringMvc 的控制器是不是单例模式,如果是,有什么问题,怎么解决?
是单例模式,在多线程访问的时候有线程安全问题,解决方案是在控制器里面不能写可变状态量,如果需要使用这些可变状态,可以使用ThreadLocal机制解决,为每个线程单独生成一份变量副本,独立操作,互不影响。
-
如何解决 POST 请求和 GET 请求中文乱码问题?
解决 POST 请求乱码问题:在 web.xml 中配置一个 CharacterEncodingFilter 过滤器,设置成 utf-8 ;
12345678910111213<filter><filter-name>CharacterEncodingFilter</filter-name><filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class><init-param><param-name>encoding</param-name><param-value>utf-8</param-value></init-param></filter><filter-mapping><filter-name>CharacterEncodingFilter</filter-name><url-pattern>/*</url-pattern></filter-mapping>解决 GET请求乱码问题:
1.修改tomcat配置文件添加编码与工程编码一致,如下:
1<ConnectorURIEncoding="utf-8" connectionTimeout="20000" port="8080" protocol="HTTP/1.1" redirectPort="8443"/>2.另外一种方法对参数进行重新编码:
String userName = new String(request.getParamter(“userName”).getBytes(“ISO8859-1”),“utf-8”)
ISO8859-1是tomcat默认编码,需要将tomcat编码后的内容按utf-8编码。
-
SpingMvc 中的控制器的注解一般用那个,有没有别的注解可以替代?
在SpringMVC中,控制器通常使用@Controller注解,还可以使用@RestController作为替代。
@Controller注解用于标记一个类作为控制器,它主要用于处理HTTP请求。而@RestController注解相当于@ResponseBody + @Controller,表示控制器返回的数据直接作为HTTP响应体,通常用于构建RESTful API。使用@RestController可以简化代码,因为它自动将控制器方法的返回值作为响应体,而不需要在每个方法上添加@ResponseBody注解。
这两种注解的主要区别在于:
@Controller:主要用于处理HTTP请求,返回视图名称,适用于需要返回视图的情况。
@RestController:主要用于构建RESTful API,返回数据直接作为HTTP响应体,适用于不需要返回视图的情况。
选择使用哪种注解取决于你的具体需求:如果需要返回视图,使用@Controller;如果需要构建RESTful API,返回JSON、XML等格式的数据,使用@RestController。 -
@RequestMapping 注解用在类上面有什么作用?
是一个用来处理请求地址映射的注解,可用于类或方法上。用于类上,表示类中的所 有响应请求的方法都是以该地址作为父路径。
-
怎么样把某个请求映射到特定的方法上面?
直接在方法上面加上注解@RequestMapping,并且在这个注解里面写上要拦截的路径。
-
Spring MVC的异步请求处理是如何实现的?
Spring MVC的异步请求处理允许控制器方法异步处理请求,不阻塞Servlet容器的线程。实现方式包括:
1.@Async注解: 在控制器方法上使用@Async实现异步处理。
2.返回Callable或DeferredResult: 控制器方法可以返回Callable或DeferredResult,Spring MVC将在另一个线程中执行Callable或在DeferredResult完成时发送响应。
3.事件监听和回调: 异步处理完成后,可以通过事件或回调来通知。
-
Spring MVC中的数据验证是如何工作的?
在Spring MVC中,数据验证通常是通过以下步骤实现的:
1.使用JSR 303/JSR 349注解: 在模型类上使用如@NotNull, @Size, @Pattern等注解来声明验证规则。
2.在控制器中启用验证: 在控制器方法中,将验证的模型对象前添加@Valid注解,这会触发验证逻辑。
3.处理验证结果: 使用BindingResult参数来获取验证的结果,包括任何验证错误信息。
4.展示错误信息: 在视图层(如JSP或Thymeleaf模板)中使用特定标签展示错误信息。
-
Spring MVC中的WebApplicationContext是什么?
WebApplicationContext是Spring MVC中的一个特殊类型的ApplicationContext,它是为Web应用程序定制的。它扩展了标准的ApplicationContext,添加了对Web应用程序特有的功能,如:
1.解析主题: 支持Web应用程序的主题解析。
2.存储Web相关的Bean: 如控制器、视图解析器和处理器映射。
3.Web环境的集成: 与Servlet API的集成,如获取ServletContext。
WebApplicationContext使得Spring MVC能够提供完整的MVC支持,并且与Spring的核心功能紧密集成,提供了一个功能丰富、高度集成的Web开发框架。
-
如果前台有很多个参数传入,并且这些参数都是一个对象的,那么怎么样快速得到这个 象?
直接在方法中声明这个对象,SpringMvc就自动会把属性赋值到这个对象里面。
-
SpringMVC 中函数的返回值是什么?
返回值可以有很多类型,有String, ModelAndView,当一般用String比较好。
-
SpringMVC 怎么样设定重定向和转发的?
在返回值前面加"forward:"就可以让结果转发,譬如"forward:user.do?name=method4" 在 返回值前面加"redirect:"就可以让返回值重定向,譬如"redirect:http://www.baidu.com"。
-
SpringMVC 用什么对象从后台向前台传递数据的?
通过ModelMap对象,可以在这个对象里面用put方法,把对象加到里面,前台就可以通 过el表达式拿到。
-
Spring MVC如何处理静态资源(如JavaScript、CSS、图片等)?
在Spring MVC中,处理静态资源的常用方法是配置资源处理器(Resource Handler)。这个过程包括以下步骤:
1.资源处理器配置: 在Spring MVC的配置中,定义一个或多个资源处理器,指定静态资源的位置和公开路径。
2.资源请求映射: 通过配置的路径模式,Spring将对应的HTTP请求映射到静态资源。
3.缓存控制: 可以配置资源处理器以实现静态资源的缓存控制,减少重复加载。
4.资源优化: Spring MVC还支持资源的压缩、最小化处理。
通过这种方式,Spring MVC应用可以高效地管理和服务静态资源,同时保持应用的清晰结构和管理。
-
怎么样把ModelMap里面的数据放入Session里面?
可以在类上面加上@SessionAttributes注解,里面包含的字符串就是要放入session里面 的key
这是第一种根据key放入值的方式。
123456789101112131415@SessionAttributes(value = { "key" })@Controllerpublic class HelloWorld {private static final String JSP = "success";@RequestMapping("/helloworld")public String hello(Map<String, Object> map) {map.put("key", "adsadasdads");return JSP;}}第二种,根据类型放入session域的方法
1234567891011121314151617@SessionAttributes(types = { String.class })@Controllerpublic class HelloWorld {private static final String JSP = "success";@RequestMapping("/helloworld")public String hello(Map<String, Object> map) {map.put("key", "adsadasdads");map.put("key1", "frgrgt");map.put("key2", "ddddd");return JSP;}} -
Spring MVC中,如何实现表单验证?
在Spring MVC中实现表单验证通常包括以下步骤:
1.使用Java Bean定义表单数据: 通过Java Bean来封装表单提交的数据。
2.添加验证注解: 在Java Bean的属性上使用注解(如@NotNull, @Size, @Pattern)来定义验证规则。
3.开启验证: 在Controller的方法参数中加入@Valid注解,告诉Spring需要对该对象进行验证。
4.错误处理: 在Controller方法参数中使用BindingResult对象来接收验证过程中产生的错误。
5.显示验证结果: 在视图中使用相应的方式来展示验证错误信息。
-
当一个方法向AJAX返回特殊对象,譬如Object,List等,需要做什么处理?
要加上@ResponseBody注解。
-
SpringMvc 里面拦截器是怎么写的?
有两种写法,一种是实现接口,另外一种是继承适配器类,然后在SpringMvc的配置文件中 配置拦截器即可。
配置拦截器即可:
1<!-- 配置 SpringMvc 的拦截器 --><mvc:interceptors> <!-- 配置一个拦截器的 Bean 就可以了 默认是对所有请求都拦截 --> <bean id="myInterceptor" class="com.et.action.MyHandlerInterceptor"></bean> <!-- 只针对部分请求拦截 --> <mvc:interceptor> <mvc:mapping path="/modelMap.do" /> <bean class="com.et.action.MyHandlerInterceptorAdapter" /> </mvc:interceptor></mvc:interceptors> -
Spring MVC中的Controller是如何处理请求的?
在Spring MVC中,Controller负责处理通过DispatcherServlet转发的请求。处理请求的过程通常如下:
1、注解定义: 使用@Controller注解标记类作为Controller。
2、请求映射: 使用@RequestMapping(或其衍生注解,如@GetMapping、@PostMapping等)定义URL到方法的映射。
3、请求处理: 方法中编写逻辑来处理请求。可以通过注解获取请求参数(如@RequestParam、@PathVariable)、请求体(@RequestBody)等。
4、返回处理结果: Controller方法可以返回ModelAndView、视图名、数据模型、ResponseEntity等,以表明处理结果。
5、异常处理: 可以使用@ExceptionHandler处理方法中发生的异常。
-
举几个Spring MVC中常见注解及其作用?
@RequestMapping
作用:该注解的作用就是用来处理请求地址映射的,也就是说将其中的处理器方法映射到url路径上。
属性:
- method:是让你指定请求的method的类型,比如常用的有get和post。
- value:是指请求的实际地址,如果是多个地址就用{}来指定就可以啦。
- produces:指定返回的内容类型,当request请求头中的Accept类型中包含指定的类型才可以返回的。
- consumes:指定处理请求的提交内容类型,比如一些json、html、text等的类型。
- headers:指定request中必须包含那些的headed值时,它才会用该方法处理请求的
- params:指定request中一定要有的参数值,它才会使用该方法处理请求。
@RequestParam
作用:是将请求参数绑定到你的控制器的方法参数上,是Spring MVC中的接收普通参数的注解。
属性:
- value是请求参数中的名称。
- required是请求参数是否必须提供参数,它的默认是true,意思是表示必须提供。
@RequestBody:
作用:如果作用在方法上,就表示该方法的返回结果是直接按写入的Http responsebody中(一般在异步获取数据时使用的注解)。
属性:required,是否必须有请求体。它的默认值是true,在使用该注解时,值得注意的当为true时get的请求方式是报错的,如果你取值为false的话,get的请求是null。
@PathVaribale:
作用:该注解是用于绑定url中的占位符,但是注意,spring3.0以后,url才开始支持占位符的,它是Spring MVC支持的rest风格url的一个重要的标志。
-
Spring MVC和Spring Boot之间的区别是什么?
Spring MVC和Spring Boot是Spring生态系统中的两个重要部分,它们之间的主要区别如下:
1.定位不同:
- Spring MVC是一个Web框架,用于构建Web应用程序。
- Spring Boot是一个基于Spring的开发框架,旨在简化Spring应用的创建和开发过程。
2.配置方式:
- Spring MVC需要配置大量的XML或Java配置,如DispatcherServlet、视图解析器等。
- Spring Boot提供自动配置,大大简化了配置过程,无需进行繁琐的配置。
3.嵌入式服务器:
- Spring MVC通常需要部署在外部的Servlet容器中。
- Spring Boot内嵌了Servlet容器(如Tomcat),使得应用可以独立运行。
4.用途:
- Spring MVC主要用于Web应用的视图和控制层。
- Spring Boot可以用于各种类型的Spring应用,包括Web应用。
-
-
Spring Boot相关
-
Spring, Spring MVC, SpringBoot是什么关系?
Spring 包含了多个功能模块,Spring MVC是其中一个模块,专门处理Web请求。Spring Boot 只是简化了配置,如果需要构建 MVC 架构的 Web 程序,还是需要使用 Spring MVC 作为 MVC 框架,只是说 Spring Boot 简化了 Spring MVC 的很多配置,真正做到开箱即用。
-
谈一谈对Spring IoC的理解
IoC(Inversion of Control:控制反转) 将原本在程序中手动创建对象的控制权,交由 Spring 框架来管理。为什么叫控制反转?
控制:指的是对象创建(实例化、管理)的权力
反转:控制权交给外部环境(Spring 框架、IoC 容器) -
@Component 和 @Bean 的区别?
@Component 注解作用于类,而@Bean注解作用于方法。
当我们引用第三方库中的类需要装配到 Spring容器时,则只能通过 @Bean来实现。 -
@Autowired 和 @Resource 的区别?
@Autowired 属于 Spring 内置的注解,默认的注入方式为byType(根据类型进行匹配),也就是说会优先根据接口类型去匹配并注入 Bean (接口的实现类)。 当一个接口存在多个实现类的话,byType这种方式就无法正确注入对象了,因为这个时候 Spring 会同时找到多个满足条件的选择,默认情况下它自己不知道选择哪一个。这种情况下,注入方式会变为 byName(根据名称进行匹配),这个名称通常就是类名(首字母小写)。
通过 @Qualifier 注解可以来显式指定名称而不是依赖变量的名称。@Resource属于 JDK 提供的注解,默认注入方式为 byName。如果无法通过名称匹配到对应的 Bean 的话,注入方式会变为byType。
@Resource 有两个比较常用的属性:name(名称)、type(类型)。如果仅指定 name 属性则注入方式为byName,如果仅指定type属性则注入方式为byType,如果同时指定name 和type属性(不建议这么做)则注入方式为byType+byName。 -
注入Bean的方法有哪些?
构造函数注入:通过类的构造函数来注入依赖项。
Setter 注入:通过类的 Setter 方法来注入依赖项。
Field(字段) 注入:直接在类的字段上使用注解(如 @Autowired 或 @Resource)来注入依赖项。 -
为什么Spring 官方推荐构造函数注入?
依赖完整性:确保所有必需依赖在对象创建时就被注入,避免了空指针异常的风险。
不可变性:有助于创建不可变对象,提高了线程安全性。
初始化保证:组件在使用前已完全初始化,减少了潜在的错误。
测试便利性:在单元测试中,可以直接通过构造函数传入模拟的依赖项,而不必依赖 Spring 容器进行注入。 -
Bean 的作用域有哪些?
singleton : IoC 容器中只有唯一的 bean 实例。Spring 中的 bean 默认都是单例的,是对单例设计模式的应用。
prototype : 每次获取都会创建一个新的 bean 实例。也就是说,连续 getBean() 两次,得到的是不同的 Bean 实例。
request : 每一次 HTTP 请求都会产生一个新的 bean,该 bean 仅在当前 HTTP request 内有效。
session : 每一个 HTTP Session 会产生一个新的 bean,该 bean 仅在当前 HTTP session 内有效。 -
Bean 是线程安全的吗?
Spring 框架中的 Bean 是否线程安全,取决于其作用域和状态。几乎所有场景的 Bean 作用域都是使用默认的singleton ,重点关注 singleton 作用域即可。prototype 作用域下,每次获取都会创建一个新的 bean 实例,不存在资源竞争问题,所以不存在线程安全问题。singleton 作用域下,IoC 容器中只有唯一的 bean 实例,可能会存在资源竞争问题(取决于 Bean 是否有状态)。如果这个 bean 是有状态的话,那就存在线程安全问题(有状态 Bean 是指包含可变的成员变量的对象)。
-
Bean 的生命周期了解吗?
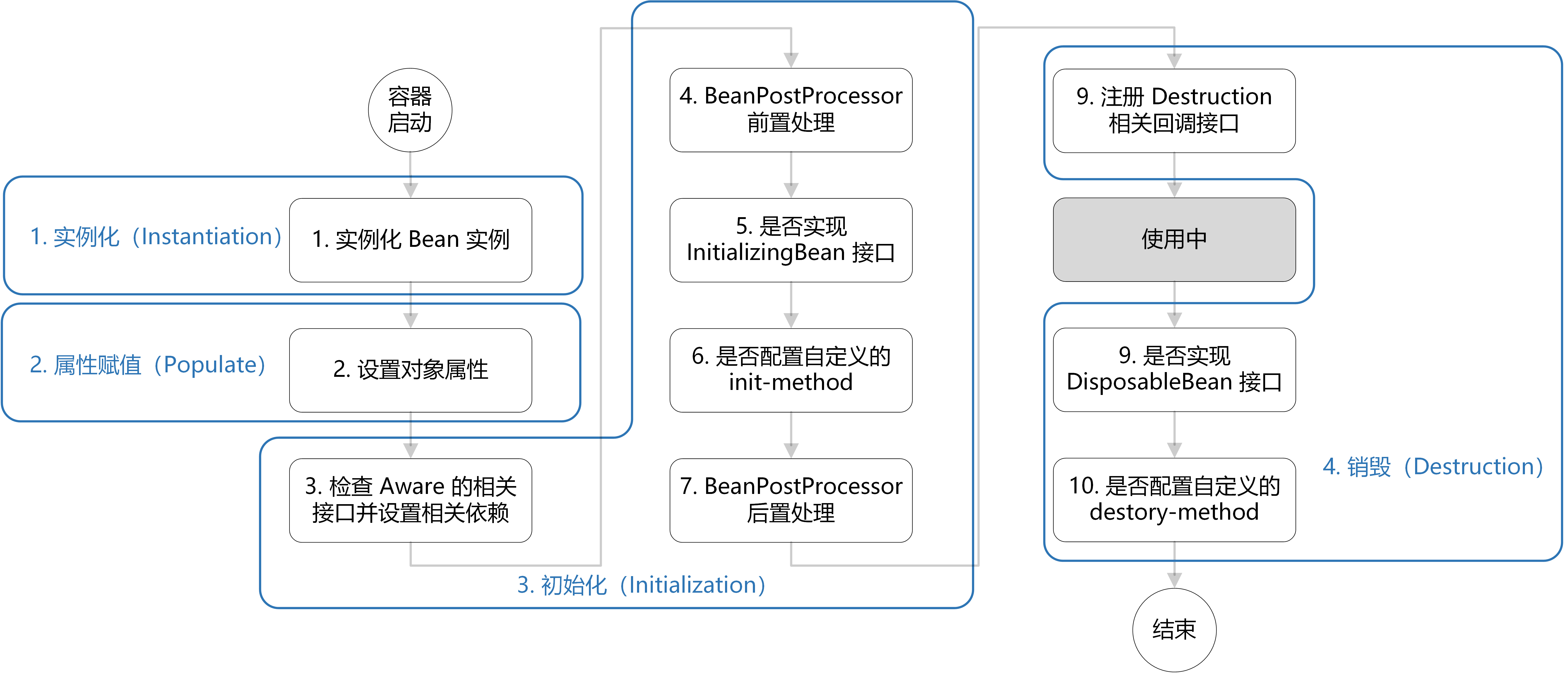
Bean的生命周期从Spring容器启动开始,首先根据配置或注解扫描获取Bean的定义信息,随后通过反射实例化对象并填充属性,完成依赖注入。如果Bean实现了诸如BeanNameAware等Aware接口,容器会在此阶段回调相关方法使其感知自身信息。接下来,BeanPostProcessor的postProcessBeforeInitialization方法被调用,执行初始化前的自定义逻辑,例如处理@PostConstruct注解的方法。随后容器触发初始化回调,包括InitializingBean接口的afterPropertiesSet方法或通过XML、注解定义的初始化方法。BeanPostProcessor的postProcessAfterInitialization在此之后执行,常见于生成AOP代理对象等增强处理。此时Bean已就绪,可被应用程序使用。当容器关闭时,销毁流程启动,依次执行@PreDestroy注解的方法、DisposableBean接口的destroy方法或配置的销毁方法,最终完成Bean的资源释放与生命周期终结。 -
如何解决 Spring 中的循环依赖问题?
Spring通过三个缓存层级解决单例Bean的循环依赖问题:
缓存名称 描述 singletonObjects 一级缓存:存放完全初始化好的Bean(成品对象)。 earlySingletonObjects 二级缓存:存放早期暴露的Bean(已实例化但未填充属性,未初始化)。 singletonFactories 三级缓存:存放Bean的工厂对象(ObjectFactory),用于生成早期引用。 以A依赖B,B依赖A为例:
- 创建Bean A
- 实例化A:调用A的构造函数创建对象(此时对象未填充属性,未初始化)。
- 将A的工厂对象放入三级缓存(singletonFactories),用于后续生成早期引用。
- 填充A的属性:发现需要注入B。
- 创建Bean B
- 实例化B:调用B的构造函数创建对象。
- 将B的工厂对象放入三级缓存。
- 填充B的属性:发现需要注入A。
- 解决B对A的依赖
- 从三级缓存中获取A的工厂对象(singletonFactories),生成A的早期引用(通过getEarlyBeanReference方法)。
这一步是整合了第一步那个实例化但是没在任何缓存里的A对象,给他变成了半成品代理对象(如果A有被代理的话) - 将A的早期引用存入二级缓存(earlySingletonObjects),并从三级缓存中删除A的工厂。
- 将A的早期引用注入到B中,完成B的属性填充和初始化。
- 将初始化后的B存入一级缓存(singletonObjects)。
- 从三级缓存中获取A的工厂对象(singletonFactories),生成A的早期引用(通过getEarlyBeanReference方法)。
- 完成A的创建
- 从一级缓存中获取已初始化的B,注入到A中。
- 完成A的属性填充和初始化。
- 将A存入一级缓存,并从二级缓存中删除A的早期引用。
我直接在实例化的时候判断A有没有代理,如果有的话,我直接把代理对象放到二级缓存里不行吗?这样就不用三级缓存了代理对象应该在bean
实例化→属性填充→初始化做完之后才去生成的(bean的生命周期),假设没有出现循环依赖,bean能通过正常的生命周期生成代理,我们直接在bean没完成初始化前就生成代理对象了,就打乱了bean的生命周期了。通过三级缓存,可以推迟bean的早期引用暴露,也就是说,要不要提前生成代理对象这个事情,推迟到循环依赖真正发生的时候。如果真发生了循环依赖,B才会调用
getEarlyBeanReference方法生成A的代理,如果没循环依赖的话,在二级缓存正常放填充好属性的A对象的,就不用提前把A的代理放二级缓存了。注意点:- 仅支持单例Bean的循环依赖
原型(Prototype)作用域的Bean无法通过缓存解决循环依赖,Spring会直接抛出异常。 - 构造器注入无法解决循环依赖
如果循环依赖通过构造函数参数注入(而非Setter方法或字段注入),Spring无法提前暴露对象,会抛出BeanCurrentlyInCreationException。
解释:如果两个Bean都是原型模式的话,那么创建A1需要创建一个B1,创建B1的时候要创建一个A2,创建A2又要创建一个B2,创建B2又要创建一个A3,创建A3又要创建一个B3,循环依赖就没办法解决了。
如果A和B的依赖都是通过构造器注入,那连一个半成品对象都创建不出来,也没办法解决循环依赖。
- 创建Bean A
-
@Lazy能解决循环依赖问题吗?
在一定程度上是能解决的
- Spring 创建 A 时,发现它依赖 B,但 B 被标记为 @Lazy。
- 不立即初始化 B,而是注入一个 B 的代理对象(由 Spring 动态生成)。
- 当 A 的方法首次调用 b.xxx() 时,代理对象才会触发 B 的实际初始化。
- 此时 B 初始化时再去注入 A,由于 A 已经存在,循环依赖被解开。
-
Spring 动态代理默认用哪一种?
Spring Boot 2.x 及以上版本默认启用了 proxyTargetClass=true,因此无论目标类是否实现接口,统一使用 CGLIB 生成代理。
动态代理的使用 -
Spring中拦截器和过滤器的区别?
过滤器(Filter)是Servlet规范的一部分,其作用范围覆盖整个Web应用,能够处理所有进入Servlet容器的请求,例如修改请求参数、设置字符编码或实现全局安全控制。它的执行时机在请求到达DispatcherServlet之前,因此可以作用于静态资源等非Spring管理的请求。拦截器(Interceptor)是Spring MVC框架提供的组件,其实现依赖于HandlerInterceptor接口,通过Spring的配置类注册到拦截器链中。它的核心作用范围集中在Spring管理的控制器(Controller)层,能够在请求进入具体Controller方法前(preHandle)、方法执行后视图渲染前(postHandle)以及整个请求完成后(afterCompletion)这三个关键节点插入逻辑。所以拦截器更适合处理与业务紧密相关的操作,例如基于会话的权限校验、日志记录或接口性能监控。从执行顺序上看,整体上过滤器的处理会先于拦截器完成。过滤器更偏向底层请求的通用处理,而拦截器则聚焦于Spring MVC流程中的业务逻辑增强。1234567HTTP Request →Servlet Filter (过滤请求) →DispatcherServlet →Interceptor.preHandle() →Controller →Interceptor.postHandle() →Interceptor.afterCompletion() -
Spring Boot的配置优先级
从高到低:
- 命令行参数(–key=value)
- java系统属性(-Dkey=value)
- application.properties
- application.yml
-
Spring Boot 自动配置如何实现的?
https://blog.csdn.net/fim77/article/details/146459033
-
@PathVariable 和 @RequestParam 的区别?
@PathVariable用于获取路径参数
/users/{id} → /users/123@RequestParam用于获取查询参数。
/users?id=123 -
Spring MVC的工作流程?
图片来自面试鸭用户:
https://www.mianshiya.com/user/1815995005551374337

-
Spring Boot 支持哪些嵌入式 web 容器?
SpringBoot提供了三种内嵌Web容器,分别为Tomcat、Jetty和Undertow。
当你在项目中引入spring-boot-starter-web这个起步依赖时,Spring Boot默
认会包含并启用Tomcat作为内嵌Servlet容器。如果你想使用Jetty或Undertow,需要在构建文件(如Maven的pom.xml或
Gradle 的build.gradle)中,从spring-boot-starter-web 中排除默认的
Tomcat 依赖(spring-boot-starter-tomcat),添加你想使用的容器对应的
Starter 依赖(例如spring-boot-starter-jetty 或spring-boot-starter-un
dertow) -
介绍一下@SpringBootApplication注解
@SpringBootApplication是SpringBoot项目的核心注解,通常用于标记应用程
序的主类(即包含main方法的类)。它的主要作用是一站式地启用SpringBoot的
关键特性,简化项目的初始配置。@SpringBootConfiguration
继承自 @Configuration,标记当前类为配置类,允许通过 @Bean 注解定义和注册 Bean。-
@EnableAutoConfiguration
启用 Spring Boot 的自动配置机制。根据项目依赖中META-INF/下后缀为.imports 文件加载预定义的配置类,结合条件注解(如 @ConditionalOnClass)自动配置 Spring 应用所需的 Bean。 @ComponentScan
默认扫描当前类所在包及其子包下的组件,并将它们注册为 Spring Bean。
-
Spring Boot 常用的两种配置文件是什么?
application.properties
采用标准的JavaProperties文件格式,即键值对(key=value)的形式,每一行定义一个配置项。
12server.port=8080spring.datasource.url=jdbc:mysql://localhost:3306/mydb
application.yml(或yaml)
采用YAML(YAMLAin’tMarkupLanguage)格式,这是一种层级化、以缩进表示结构的数据序列化语言。相比.properties文件,YAML 格式通常更易于阅读,尤其是在配置项较多或具有嵌套结构时,结构更清晰。并且,对于具有共同前缀的配置项,YAML可以通过层级嵌套避免重复书写前缀,使配置更简洁。
12345server:port: 8080spring:datasource:url: jdbc:mysql://localhost:3306/mydb
-
如何使用Spring Boot实现全局异常处理?
在 Spring Boot 中,可以通过
@ControllerAdvice 和 @ExceptionHandler注解实现全局异常处理。1234567891011121314151617@RestControllerAdvicepublic class GlobalExceptionHandler {// 处理自定义异常@ExceptionHandler(BusinessException.class)public ResponseEntity<ErrorResponse> handleBusinessException(BusinessException ex) {ErrorResponse error = new ErrorResponse(ex.getCode(), ex.getMessage());return ResponseEntity.status(ex.getHttpStatus()).body(error);}// 处理所有未捕获的异常@ExceptionHandler(Exception.class)public ResponseEntity<ErrorResponse> handleGenericException(Exception ex) {ErrorResponse error = new ErrorResponse("ERROR_500", "系统内部错误");return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR).body(error);}} -
Spring 中如何实现定时任务?多节点重复执行如何避免?
在 Spring Boot 主类或配置类上添加
@EnableScheduling1234567@SpringBootApplication@EnableSchedulingpublic class Application {public static void main(String[] args) {SpringApplication.run(Application.class, args);}}使用
@Scheduled注解标记方法,支持 cron、fixedRate、fixedDelay 等参数123456789@Componentpublic class MyScheduledTasks {// 每 5 秒执行一次@Scheduled(fixedRate = 5000)public void doTask() {System.out.println("执行定时任务: " + new Date());}}Spring Task 在多节点部署时,如果不采取措施,每个节点都会执行相同的定时任务,导致重复执行。这主要是因为每个节点上都运行着独立的 Spring 容器,每个容器都拥有自己的定时任务调度器,并独立地根据配置的时间触发任务,互不干扰。如果多个节点的配置相同,就会导致同一任务在多个节点上并发执行。
这种情况不仅浪费资源,还可能导致数据不一致、资源竞争等问题,最终导致业务逻辑错误,例如重复处理相同的数据、发送重复的通知。解决方法:
- 分布式锁
- 分布式任务调度工具,如XXL-JOB
-
你的项目是如何统一返回结果的?
code: 状态码,遵循HTTP状态码规范并扩展业务状态码message: 对状态的描述信息data: 实际返回的业务数据timestamp: 响应时间戳- 手动显式封装
12345@GetMapping("/{id}")public Result<User> getUser(@PathVariable Long id) {User user = userService.getUserById(id);return Result.success(user);} - 自动封装
1234567891011121314@RestControllerAdvicepublic class ResponseAdvice implements ResponseBodyAdvice<Object> {@Overridepublic boolean supports(MethodParameter returnType, Class<? extends HttpMessageConverter<?>> converterType) {// 判断是否需要包装return !returnType.getParameterType().equals(Result.class);}@Overridepublic Object beforeBodyWrite(Object body, MethodParameter returnType, MediaType selectedContentType,Class<? extends HttpMessageConverter<?>> selectedConverterType, ServerHttpRequest request, ServerHttpResponse response) {return Result.success(body);}}
- 手动显式封装
-
什么是Spring Boot Starters?
Spring Boot Starters 是一组便捷的依赖描述符,它们预先打包了常用的库和配置。当我们开发 Spring 应用时,只需添加一个 Starter 依赖项,即可自动引入所有必要的库和配置,而无需手动逐一添加和配置相关依赖。
这种机制显著简化了开发过程,特别是在处理复杂项目时尤为高效。通过添加一个简单的Starter 依赖,开发者可以快速集成所需的功能,避免了手动管理多个依赖的繁琐和潜在错误。这不仅节省了时间,还减少了配置错误的风险,从而提升了开发效率。
-
Spring Boot 的主要优点?
显著提升开发效率:Spring Boot 通过自动配置、起步依赖(Starters)和其他开箱即用的功能,极大地减少了项目初始化、配置编写和样板代码的工作量,使开发者能更快地构建和交付应用。与 spring 生态系统的无缝集成:作为 Spring 家族的一员,Spring Boot 能够方便地整合 Spring 框架下的其他成熟模块(如 Spring Data、Spring Security、Spring Batch 等),充分利用 Spring 强大的生态系统,简化整合工作。强大的自动配置能力:遵循“约定优于配置”的原则,Spring Boot 能够根据项目依赖自动配置大量
的常见组件(如数据源、Web 容器、消息队列等),提供合理的默认设置。同时也允许开发者根据需要轻松覆盖或定制配置,极大减少了繁琐的手动配置工作。内嵌 Web 服务器支持:Spring Boot 自带内嵌的 HTTP服务器(如 Tomcat、Jetty),开发者可以像运行普通 Java 程序一样运行 Spring Boot 应用程序,极大地简化了开发和测试过程。适合微服务架构:Spring Boot 使得每个微服务都可以独立运行和部署,简化了微服务的开发、测试和运维工作,成为构建微服务架构的理想选择。提供强大的构建工具支持:Spring Boot为常用的构建工具(如 Maven和 Gradle)提供了专门的插件,简化了项目的打包(如创建可执行JAR)、运行、测试以及依赖管理等常见构建任务丰富的监控和管理功能:通过 Spring Boot Actuator 模块,可以轻松地为应用添加生产级的监控和管理端点,方便了解应用运行状况、收集指标、进行健康检查等。
-
Spring Boot 是如何通过 main 方法启动 web 项目的?
https://www.mianshiya.com/bank/1797452903309508610/question/1846441429268488194#heading-14 -
如何在 Spring Boot 中读取配置信息?
- 使用
@Value注解123// 直接注入配置项,支持默认值(如未配置则使用默认值)@Value("${book.author:defaultAuthor}")private String author; - 使用
@ConfigurationProperties注解12345678# 配置文件 application.ymlbook:name: 三国演义author: 罗贯中price: 30chapters:- 第一章- 第二章12345678@Component@ConfigurationProperties(prefix = "book")public class BookProperties {private String name;private String author;private int price;private List<String> chapters;} - 使用
Environment接口1234567@Autowiredprivate Environment env;public String getAppInfo() {String appName = env.getProperty("app.name");String maxRetry = env.getProperty("app.max-retry", "defaultRetry");}
- 使用
-
Spring 事务中哪几种事务传播行为?
总共有7种,常用的就前两种
PROPAGATION_REQUIRED(默认)
如果当前存在事务,则加入该事务;否则新建一个事务。
所有嵌套方法共享同一个事务,任一方法抛出异常会导致整个事务回滚。PROPAGATION_REQUIRES_NEW
无论当前是否存在事务,都新建一个独立事务。
内层事务与外层事务完全隔离,外层事务回滚不影响内层事务。PROPAGATION_NESTED
如果当前存在事务,则在当前事务内嵌套一个子事务;否则创建新事务。
子事务是父事务的一部分,但可以独立回滚。
子事务回滚不影响父事务(需捕获异常),父事务回滚则子事务也会回滚。PROPAGATION_MANDATORY
必须在一个已存在的事务中运行,否则抛出异常。PROPAGATION_SUPPORTS
如果当前存在事务,则加入该事务;否则以非事务方式运行。PROPAGATION_NOT_SUPPORTED
以非事务方式运行,如果当前存在事务则挂起。PROPAGATION_NEVER
以非事务方式运行,如果当前存在事务则抛出异常。
-
Spring 中BeanFactory 和 FactoryBean是什么?
BeanFactory是Spring框架的核心接口,作为IoC容器的基础,负责管理Bean的生命周期,包括创建、配置和装配对象。FactoryBean是一个特殊的Bean,可以在运行时根据特定条件或需求,通过getObject()方法动态控制Bean的实例化过程,在容器中通过名称前加&符号区分获取FactoryBean本身与其生产的对象。 -
ApplicationContext是什么?
ApplicationContext是Spring框架的核心容器接口,它作为高级容器不仅继承了BeanFactory的基础功能来管理和配置Bean,还扩展了众多企业级特性。它整合了资源加载、国际化支持、事件发布与监听机制,同时支持AOP、事务管理等高级功能。
-
Spring Boot 如何做请求参数校验?
验证请求体
在 DTO 类上使用校验注解1234public class UserDTO {@Size(min = 2, max = 20, message = "用户名长度必须在2-20之间")private String username;}在 Controller 中使用 @Valid 注解触发校验(@Validated也行)
12345@PostMapping("/users")public ResponseEntity<?> createUser(@RequestBody @Valid UserDTO userDTO) {// 业务逻辑return ResponseEntity.ok("用户创建成功");}- 验证请求参数
直接在方法参数上使用校验注解:12345@GetMapping("/users/{id}")public ResponseEntity<?> getUserById(@PathVariable @Min(1) Long id) {// 业务逻辑return ResponseEntity.ok(...);}需要在 Controller 类上添加 @Validated 注解,只能在类上添加这个才有用12345@RestController@Validatedpublic class UserController {// ...}补充:分组校验
123456789101112public class UserDTO {@NotBlank(message = "用户名不能为空", groups = {CreateGroup.class, UpdateGroup.class})private String username;@Email(message = "邮箱格式不正确", groups = CreateGroup.class) // 仅创建时需要校验邮箱private String email;@NotNull(message = "ID不能为空", groups = UpdateGroup.class) // 仅更新时需要校验IDprivate Long id;// Getter 和 Setter}1234@PostMapping("/users")public ResponseEntity<?> createUser(@RequestBody @Validated(CreateGroup.class) UserDTO userDTO) {return ResponseEntity.ok("创建用户校验通过");}
-
Spring Boot 如何处理跨域请求?
-
Spring Boot 如何实现异步处理?
主要有四种方式来实现异步处理:
- 使用 @Async注解
- 使用 CompletableFuture
- 使用@Scheduled注解
- 使用线程池
-
说说对 Spring 中事件机制的理解?
Spring 的事件机制是一种基于观察者模式设计的解耦通信方式,允许组件在特定动作发生时通过事件传递信息,而不必直接依赖彼此。开发者可以自定义继承 ApplicationEvent 的事件类,由事件发布者通过 ApplicationEventPublisher 触发事件,而监听者通过实现 ApplicationListener 接口或使用 @EventListener 注解来捕获并处理事件。这种机制默认以同步方式运行,但结合 @Async 或自定义线程池可支持异步处理,提升系统响应能力。例如,用户注册成功后发布事件,由监听器异步发送邮件或初始化数据,避免主流程阻塞。
-
Spring 中如何配置多数据源?
-
Spring 中有哪些设计模式?
工厂模式(Factory Pattern)
作用:隐藏对象创建细节,由容器统一管理 Bean 的生命周期。单例模式(Singleton Pattern)
Spring 默认的 Bean 作用域为单例(singleton),确保每个容器中一个 Bean 仅有一个实例。
作用:节省资源,保证全局一致性。原型模式(Prototype Pattern)
Bean 的作用域设为 prototype 时,每次请求都会创建新实例(如 @Scope(“prototype”))。代理模式(Proxy Pattern)
Spring AOP(面向切面编程)通过动态代理实现横切关注点(如事务、日志)。模板方法模式(Template Method Pattern)
JdbcTemplate、RestTemplate 等模板类封装通用流程,消除重复代码观察者模式(Observer Pattern)
核心应用:Spring 事件驱动模型(ApplicationEvent 和 ApplicationListener)。适配器模式(Adapter Pattern)
统一接口,兼容不同实现。装饰者模式(Decorator Pattern)
HttpServletRequestWrapper 包装 HTTP 请求,增强其行为(如缓存请求体)。策略模式(Strategy Pattern)
Spring MVC 的 HandlerMapping 根据请求匹配不同策略的处理器。委派模式(Delegate Pattern)
DispatcherServlet 将请求分发给不同的处理器(如 Controller、Handler)。建造者模式(Builder Pattern)
分步构建复杂对象。责任链模式(Chain of Responsibility)
Spring Security 的过滤器链(FilterChainProxy),每个过滤器依次处理请求。
-
Spring AOP 如何使用?
-
@Primary 和 @Qualifier注解的作用是什么?
@Primary标记某个Bean为“默认首选”的候选对象。当存在多个相同类型的Bean时,Spring会优先选择带有@Primary注解的Bean进行注入。@Qualifier通过显式指定 Bean 的名称或标识符来解决多个同类型 Bean 的冲突。 -
@RequestBody和@ResponseBody注解的作用是什么?
@RequestBody注解用于将HTTP请求体中的内容绑定到方法的参数上,它主要作用在方法的参数上。@ResponseBody注解用于将方法的返回值直接写入HTTP响应体中,它可以标注在方法或类上。在Spring 4.0之后,可以使用@RestController注解替代@Controller+@ResponseBody的组合。
-
-
-
MyBatis
-
什么是MyBatis
MyBatis是一款优秀的半自动化的持久层框架。支持自定义 SQL、存储过程以及高级映射。
-
MyBatis的特点?
简单、灵活、解耦、丰富的标签
-
MyBatis 框架的应用场景?
- 复杂 SQL 查询:需要灵活编写复杂 SQL,避免 ORM 生成低效查询。
- 现有数据库集成:对已有数据库结构进行操作,不适合全面使用 ORM 的场景。
- 高性能需求:需要手动优化 SQL 查询性能时。
- 灵活控制:需要精确控制 SQL 语句和数据库操作的应用。
它特别适合那些对 SQL 有较高控制要求的项目。
-
MyBatis 有哪些优点?
- 原生 SQL 灵活:可以手写 SQL,处理复杂查询。
- 轻量易用:配置简单,学习成本低。
- 动态 SQL 支持:根据条件动态生成 SQL。
- 高性能:手动优化 SQL,性能可控。
- 现有数据库友好:适合已有复杂数据库的项目。
-
MyBatis 有哪些缺点?
- SQL 手动编写:需要开发者手写 SQL,增加工作量。
- 维护成本高:复杂项目中,管理大量 SQL 语句和映射关系可能变得困难。
- 缺少自动化:不像 ORM 框架,无法自动生成 SQL,手动处理对象与数据库的映射。
- SQL 与代码耦合:SQL 与 Java 代码耦合紧密,不利于数据库迁移或改动。
-
MyBatis 中 Mapper 接口的实现原理是?
MyBatis 中 Mapper 接口的实现原理是通过动态代理生成接口的实现类。MyBatis 根据 Mapper 接口的方法签名自动生成 SQL 语句,并在运行时由
SqlSession提供执行,返回对应的查询结果。这样开发者只需定义接口和 SQL 映射,不需要手动编写实现类。 -
MyBatis用注解绑定和用XML文件绑定有什么区别?
MyBatis 中注解绑定和 XML 文件绑定的区别如下:
- 注解绑定:
- SQL 语句直接写在 Mapper 接口的方法上,通过注解(如
@Select,@Insert,@Update,@Delete)定义。 - 适合简单的 SQL 语句,代码集中在一个地方,维护方便。
- 适合轻量级项目,不需要单独的 XML 文件。
- SQL 语句直接写在 Mapper 接口的方法上,通过注解(如
- XML 文件绑定:
- SQL 语句保存在独立的 XML 文件中,通过
<select>,<insert>,<update>,<delete>等标签定义。 - 适合复杂 SQL,尤其是动态 SQL,XML 提供更灵活的控制。
- 便于与业务逻辑分离,SQL 语句与代码解耦,易于维护和扩展。
- SQL 语句保存在独立的 XML 文件中,通过
简而言之,注解适合简单 SQL,XML 更适合复杂 SQL 和动态 SQL。
- 注解绑定:
-
MyBatis通常一个 Xml 映射文件,都会写一个 Dao 接口与之对应, Dao 的工作原理,是否可以重载?
在 MyBatis 中,每个 XML 映射文件通常对应一个 DAO(Data Access Object)接口。DAO 接口的工作原理是通过 MyBatis 的动态代理机制:MyBatis 自动生成 DAO 接口的实现类,通过
SqlSession执行映射文件中的 SQL 语句,并将结果返回给调用者。DAO 接口中的方法可以重载,即在同一个接口中,可以定义多个方法名相同但参数类型或数量不同的方法。然而,需要注意的是:
- MyBatis 会根据方法签名(包括方法名和参数类型)确定调用哪个 SQL 语句。
- 在 XML 映射文件中,每个重载的方法需要对应唯一的
<select>,<insert>,<update>,<delete>标签,这些标签需要通过id唯一标识,每个id应与重载方法匹配。
因此,DAO 接口方法可以重载,但需要确保 XML 映射文件中的
id能唯一标识每个方法。 -
MyBatis 中 Mapper 中的 SQL 语句可以重载吗?
MyBatis 中 SQL 语句不能直接重载,因为 SQL 是通过
Mapper方法的名字和参数唯一映射的。如果方法重载,MyBatis 无法区分不同方法的 SQL。解决方式:
- 使用不同的方法名。
- 使用动态 SQL 实现条件判断。
- 使用
@Param区分参数。
重载本质上需要避免方法和 SQL 映射冲突。
-
MyBatis 用到了哪些设计模式?
MyBatis 采用了多种设计模式,帮助其实现灵活性和可扩展性,主要包括以下几种:
- 代理模式:MyBatis 使用代理模式(动态代理)来为 Mapper 接口生成实现类,处理 SQL 语句的执行,避免手动编写实现代码。
- 工厂模式:MyBatis 使用工厂模式创建 SQLSession 对象,通过
SqlSessionFactory来管理和提供 SQLSession - 单例模式:
SqlSessionFactory使用单例模式确保工厂实例在应用中只有一个,方便统一管理数据库会话 - 模板方法模式:MyBatis 中的
Executor类使用模板方法模式,提供执行 SQL 操作的通用流程,子类可以自定义具体实现。 - 建造者模式:在配置解析中,MyBatis 使用建造者模式生成复杂的对象,比如解析 XML 或注解并构建相应的映射配置。
-
MyBatis常用注解有哪些?
这些注解用于简化 SQL 操作,替代 XML 配置。
MyBatis 常用注解有:- @Select:执行查询操作。
- @Insert:执行插入操作。
- @Update:执行更新操作。
- @Delete:执行删除操作。
- @Results:自定义结果集的映射。
- @Result:定义单个字段的映射关系。
- @Param:为 SQL 语句传递参数。
-
MyBatis 有哪些核心组件?
- SqlSessionFactory:创建和管理
SqlSession对象的工厂。 - SqlSession:执行 SQL 语句的接口,管理数据库会话。
- Executor:负责执行 SQL 语句,管理缓存和事务。
- Mapper 接口:映射 SQL 语句与 Java 对象的方法接口。
- Configuration:全局配置类,包含 MyBatis 的所有配置信息。
- SqlSessionFactory:创建和管理
-
MyBatis编程步骤是什么样的?
MyBatis 的编程步骤如下:
- 引入 MyBatis 依赖:在项目中配置 MyBatis 所需的依赖(如 Maven 中添加依赖项)
- 配置 MyBatis 环境:编写
mybatis-config.xml,配置数据库连接信息、别名、映射文件等。 - 编写 Mapper 文件:
- 使用 XML 文件编写 SQL 映射(或用注解方式)。
- 定义接口(Mapper),与 SQL 映射文件中的 SQL 语句进行绑定。
- 创建 SqlSessionFactory:通过
SqlSessionFactoryBuilder读取配置文件,生成SqlSessionFactory。 - 使用 SqlSession 操作数据库:
- 通过
SqlSessionFactory获取SqlSession。 - 调用 Mapper 接口执行增删改查操作。
- 最后关闭
SqlSession以释放资源。
- 通过
- 处理结果:接收数据库操作返回的结果并处理。
-
MyBatis 接口绑定有哪几种方式?
MyBatis 接口绑定有两种方式:
- XML 文件方式:在 Mapper 接口中定义方法,并通过对应的 XML 文件绑定 SQL 语句。
- 注解方式:直接在 Mapper 接口的方法上使用注解(如
@Select、@Insert、@Update、@Delete等)编写 SQL,实现绑定。
这两种方式都可以将 SQL 语句与接口方法关联起来。
-
MyBatis 有哪几种 SQL 编写形式?
MyBatis 支持以下两种 SQL 编写形式:
- XML 文件形式:在 XML 文件中编写 SQL 语句,通过 Mapper 接口方法绑定。
- 注解形式:直接在 Mapper 接口的方法上使用注解(如
@Select、@Insert、@Update、@Delete)编写 SQL。
这两种方式都可以用于实现 SQL 操作,选择哪种形式取决于项目需求。
-
MyBatis 映射时 A 引用了 B,如果 B 在 A 后面会怎样?
在 MyBatis 映射文件中,如果映射
A引用了映射B,而B的定义在A之后,通常会导致 MyBatis 报错。因为 MyBatis 解析映射文件时是顺序进行的,当解析到A时,它会试图找到B,但此时B还未被解析,因此会抛出Invalid Reference等类似的错误。为避免这种问题,可以通过以下方式解决:
- 调整顺序:确保
B在A之前定义。 - 使用命名空间引用:将
B放在其他映射文件中并通过命名空间引用,确保引用的映射在加载时已经存在。
顺序错误会直接影响 MyBatis 的解析,因此需要特别注意映射文件中引用的顺序。
- 调整顺序:确保
-
MyBatis 映射文件中有哪些顶级元素?
MyBatis 映射文件中的顶级元素主要包括:
<cache>:配置缓存策略。<cache-ref>:引用其他命名空间的缓存。<resultMap>:定义结果集映射规则。<sql>:定义可复用的 SQL 片段。<insert>、<update>、<delete>、<select>:定义 SQL 操作语句。
这些元素是 MyBatis 映射文件的核心组成部分。
-
JDBC 编程有哪些不足之处,MyBatis 是如何解决的?

- 数据连接创建、释放频繁造成系统资源浪费从而影响系统性能,在 mybatis-config.xml 中配置数据链接池,使用连接池统一管理数据库连接。
- sql 语句写在代码中造成代码不易维护,将 sql 语句配置在 XXXXmapper.xml 文件中与 java 代码分离。
- 向 sql 语句传参数麻烦,因为 sql 语句的 where 条件不一定,可能多也可能少,占位符需要和参数一一对应。Mybatis 自动将 java 对象映射至 sql 语句。
- 对结果集解析麻烦,sql 变化导致解析代码变化,且解析前需要遍历,如果能将数据库记录封装成 pojo 对象解析比较方便。Mybatis 自动将 sql 执行结果映射至 java 对象。
-
MyBatis 使用过程?生命周期?
MyBatis 基本使用的过程大概可以分为这么几步:

Mybatis基本使用步骤 - 1)创建 SqlSessionFactory
可以从配置或者直接编码来创建 SqlSessionFactory
123String resource = "org/mybatis/example/mybatis-config.xml";InputStream inputStream = Resources.getResourceAsStream(resource);SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);- 2)通过 SqlSessionFactory 创建 SqlSession
SqlSession(会话)可以理解为程序和数据库之间的桥梁
1SqlSession session = sqlSessionFactory.openSession();- 3)通过 sqlsession 执行数据库操作
可以通过 SqlSession 实例来直接执行已映射的 SQL 语句:
1Blog blog = (Blog)session.selectOne("org.mybatis.example.BlogMapper.selectBlog", 101);更常用的方式是先获取 Mapper(映射),然后再执行 SQL 语句:
12BlogMapper mapper = session.getMapper(BlogMapper.class);Blog blog = mapper.selectBlog(101);- 4)调用 session.commit()提交事务
如果是更新、删除语句,我们还需要提交一下事务。
- 5)调用 session.close()关闭会话
最后一定要记得关闭会话。
-
说说 MyBatis 生命周期?
上面提到了几个 MyBatis 的组件,一般说的 MyBatis 生命周期就是这些组件的生命周期。
- SqlSessionFactoryBuilder
一旦创建了 SqlSessionFactory,就不再需要它了。 因此 SqlSessionFactoryBuilder 实例的生命周期只存在于方法的内部。
- SqlSessionFactory
SqlSessionFactory 是用来创建 SqlSession 的,相当于一个数据库连接池,每次创建 SqlSessionFactory 都会使用数据库资源,多次创建和销毁是对资源的浪费。所以 SqlSessionFactory 是应用级的生命周期,而且应该是单例的。
- SqlSession
SqlSession 相当于 JDBC 中的 Connection,SqlSession 的实例不是线程安全的,因此是不能被共享的,所以它的最佳的生命周期是一次请求或一个方法。
- Mapper
映射器是一些绑定映射语句的接口。映射器接口的实例是从 SqlSession 中获得的,它的生命周期在 sqlsession 事务方法之内,一般会控制在方法级。

MyBatis主要组件生命周期 当然,万物皆可集成 Spring,MyBatis 通常也是和 Spring 集成使用,Spring 可以帮助我们创建线程安全的、基于事务的 SqlSession 和映射器,并将它们直接注入到我们的 bean 中,我们不需要关心它们的创建过程和生命周期,那就是另外的故事了。
-
MyBatis 支持哪些传参数的方法?
MyBatis 支持以下几种传参方法:
- 单个参数:传递简单类型或对象,SQL 中用
#{param}访问。 - 多个参数:使用
@Param注解,例如:
1List<User> findUser(@Param("id") int id, @Param("name") String name); - 传递对象:传递实体对象,SQL 中用
#{user.id}访问属性。 - 使用
Map传参:通过Map传递参数,SQL 中用#{key}访问值。
这些方法提供了灵活的参数传递方式。
- 单个参数:传递简单类型或对象,SQL 中用
-
在 mapper 中如何传递多个参数?

mapper传递多个参数方法 方法 1:顺序传参法
123456public User selectUser(String name, int deptId);<select id="selectUser" resultMap="UserResultMap">select * from userwhere user_name = #{0} and dept_id = #{1}</select>方法 2:@Param 注解传参法
123456public User selectUser(@Param("userName") String name, int @Param("deptId") deptId);<select id="selectUser" resultMap="UserResultMap">select * from userwhere user_name = #{userName} and dept_id = #{deptId}</select>\#{}里面的名称对应的是注解@Param 括号里面修饰的名称。- 这种方法在参数不多的情况还是比较直观的,(推荐使用)。
方法 3:Map 传参法
123456public User selectUser(Map<String, Object> params);<select id="selectUser" parameterType="java.util.Map" resultMap="UserResultMap">select * from userwhere user_name = #{userName} and dept_id = #{deptId}</select>\#{}里面的名称对应的是 Map 里面的 key 名称。- 这种方法适合传递多个参数,且参数易变能灵活传递的情况。
方法 4:Java Bean 传参法
123456public User selectUser(User user);<select id="selectUser" parameterType="com.jourwon.pojo.User" resultMap="UserResultMap">select * from userwhere user_name = #{userName} and dept_id = #{deptId}</select>\#{}里面的名称对应的是 User 类里面的成员属性。- 这种方法直观,需要建一个实体类,扩展不容易,需要加属性,但代码可读性强,业务逻辑处理方便,推荐使用。(推荐使用)。
-
MyBatis实体类中的属性名和表中的字段名不一样 ,怎么办?
在 MyBatis 中,如果实体类的属性名与数据库表中的字段名不一致,可以通过以下两种方式进行映射:
- 使用
@Results注解:
在 Mapper 接口的方法上通过@Results注解手动指定实体类属性与数据库字段的对应关系。
12345@Select("SELECT id, user_name FROM users")@Results({@Result(property = "userName", column = "user_name")})List<User> selectUsers();
- 在 XML 映射文件中使用
<resultMap>:
通过 XML 配置文件的<resultMap>元素将表字段与实体类属性进行映射。
1234567<resultMap id="userMap" type="User"><result property="userName" column="user_name"/></resultMap><select id="selectUsers" resultMap="userMap">SELECT id, user_name FROM users</select>
这两种方式都可以解决实体类属性名和表字段名不一致的问题。
- 使用
-
模糊查询 like 语句该怎么写?

concat拼接like 1234<select id="listUserLikeUsername" resultType="com.jourwon.pojo.User">  <bind name="pattern" value="'%' + username + '%'" />  select id,sex,age,username,password from person where username LIKE #{pattern}</select>- 1 ’
%${question}%’ 可能引起 SQL 注入,不推荐 - 2
"%"#{question}"%"注意:因为#{…}解析成 sql 语句时候,会在变量外侧自动加单引号’ ',所以这里 % 需要使用双引号" ",不能使用单引号 ’ ',不然会查不到任何结果。 - 3
CONCAT('%',#{question},'%')使用 CONCAT()函数,(推荐 ✨) - 4 使用 bind 标签(不推荐)
- 1 ’
-
MyBatis 模糊查询 like 语该怎么写?
在 MyBatis 中,进行模糊查询可以使用
LIKE关键字,通常结合 SQL 的通配符%来实现。- XML 映射文件中的模糊查询
1234<select id="findUsersByName" resultType="User">SELECT * FROM usersWHERE name LIKE CONCAT('%', #{name}, '%')</select> - 使用注解的方式
12@Select("SELECT * FROM users WHERE name LIKE CONCAT('%', #{name}, '%')")List<User> findUsersByName(@Param("name") String name); - 传递参数
在调用时,将需要模糊匹配的字符串传入查询方法中:
1List<User> users = userMapper.findUsersByName("张三");
总结:使用
LIKE结合%通配符,可以在 MyBatis 中实现模糊查询。通过 XML 或注解都可以轻松实现。 - XML 映射文件中的模糊查询
-
MyBatis 如何防止 SQL 注入?
MyBatis 防止 SQL 注入主要通过以下方式:
- 使用预编译语句:通过参数化查询(
#{})来绑定参数,避免直接拼接 SQL 字符串。
123<select id="findUser" resultType="User">SELECT * FROM users WHERE username = #{username}</select>
- 避免直接拼接 SQL:不使用字符串拼接构建 SQL 语句,确保输入参数经过处理。
- 使用 MyBatis 的内置功能:使用内置的
@Param注解来安全地传递参数。 - 输入验证:在应用层进行输入验证,确保参数合法。
- 使用预编译语句:通过参数化查询(
-
MyBatis 如何获取自动生成的主键id?
在 MyBatis 中获取自动生成的主键 ID 的方法如下:
- 使用 XML 映射
123<insert id="insertUser" parameterType="User" useGeneratedKeys="true" keyProperty="id">INSERT INTO users (username, password) VALUES (#{username}, #{password})</insert>
- 使用注解
123@Insert("INSERT INTO users (username, password) VALUES (#{username}, #{password})")@Options(useGeneratedKeys = true, keyProperty = "id")void insertUser(User user);
- 获取 ID插入后,自动生成的主键会赋值给对象的
id属性:
12345User user = new User();user.setUsername("张三");user.setPassword("password");userMapper.insertUser(user);Long generatedId = user.getId(); // 获取主键 ID
- 使用 XML 映射
-
MyBatis 中
jdbcType和javaType的区别?jdbcType- 定义:表示数据库中列的数据类型。
- 用途:用于确定如何处理数据库中的数据,影响 SQL 语句的生成和执行。
- 示例:如
VARCHAR、INTEGER、DATE等。
javaType- 定义:表示 Java 中对应的数据类型。
- 用途:用于将数据库中的数据映射到 Java 对象的属性。
- 示例:如
String、Integer、Date等。
总的来说,
javaType和jdbcType都是用来处理数据类型的,javaType主要用来处理Java对象到数据库的映射,而jdbcType主要用来处理数据库类型和JDBC之间的关系。 -
什么时候必须指定
jdbcType和javaType?在 MyBatis 中,必须指定
jdbcType和javaType的情况主要有以下几种:jdbcType- NULL 值处理:当字段可以为
NULL时,必须显式指定jdbcType,以便正确处理空值。 - 特定类型映射:对于一些特殊或不常用的数据类型,如
BLOB、CLOB等,建议指定jdbcType以确保正确处理。
- NULL 值处理:当字段可以为
javaType- 复杂类型:当字段类型是复杂类型(如自定义对象或集合)时,必须指定
javaType,以确保正确映射到 Java 类型。 - 不匹配类型:当数据库字段类型与 Java 类型不一致时,需要明确指定
javaType以避免类型转换错误。
- 复杂类型:当字段类型是复杂类型(如自定义对象或集合)时,必须指定
示例
12345<resultMap id="UserMap" type="User"><result property="id" column="id" jdbcType="INTEGER" javaType="java.lang.Integer"/><result property="username" column="username" jdbcType="VARCHAR" javaType="java.lang.String"/><result property="createdDate" column="created_date" jdbcType="TIMESTAMP" javaType="java.util.Date"/></resultMap>总结:必须在处理
NULL值、复杂类型或类型不匹配时显式指定jdbcType和javaType。 -
MyBatis 支持预编译吗? 怎么做?
MyBatis 支持预编译,主要通过参数化查询来实现。具体做法如下:
- 使用参数化查询
使用#{}语法指定参数,MyBatis 会自动进行预编译。
示例
XML 映射文件123<select id="findUserById" resultType="User">SELECT * FROM users WHERE id = #{id}</select>Mapper 接口
1User findUserById(@Param("id") int id);总结:MyBatis 通过参数化查询(
#{})实现预编译,确保 SQL 安全性和性能优化。 - 使用参数化查询
-
MyBatis 中的事务管理方式?
- 编程式事务管理通过
SqlSession控制事务:- 手动控制事务的开始、提交和回滚。
- 适合需要细粒度控制的场景。
12345678910SqlSession sqlSession = sqlSessionFactory.openSession();try {// 开始事务// 执行操作sqlSession.commit(); // 提交事务} catch (Exception e) {sqlSession.rollback(); // 回滚事务} finally {sqlSession.close();}
- 声明式事务管理
结合 Spring 框架使用:- 通过
@Transactional注解自动管理事务。 - 适合简单配置和一致性需求的场景。
1234567@Servicepublic class UserService {@Transactionalpublic void addUser(User user) {// 执行数据库操作}}总结:MyBatis 提供编程式和声明式两种事务管理方式,编程式适合细粒度控制,声明式适合与 Spring 结合使用。
- 通过
- 编程式事务管理通过
-
怎么开启事务?
- 编程式事务管理
123456789SqlSession sqlSession = sqlSessionFactory.openSession(); // 开启事务try {// 执行数据库操作sqlSession.commit(); // 提交事务} catch (Exception e) {sqlSession.rollback(); // 回滚事务} finally {sqlSession.close(); // 关闭会话}
- 声明式事务管理(与 Spring 结合使用)
1234567@Servicepublic class UserService {@Transactional // 开启事务public void addUser(User user) {// 执行数据库操作}}
总结
- 编程式:使用
SqlSession手动管理事务。 - 声明式:使用
@Transactional注解自动处理事务。
- 编程式:使用
- 编程式事务管理
-
MyBatis 事务和 Spring 事务有什么区别?
- 事务管理方式
- MyBatis 事务:
- 主要通过
SqlSession手动管理,支持编程式事务控制。 - 事务的开始、提交和回滚需要显式调用。
- 主要通过
- Spring 事务:
- 提供了声明式事务管理,可以通过
@Transactional注解自动处理事务。 - 可以与多种数据访问技术(如 JPA、Hibernate)结合使用。
- 提供了声明式事务管理,可以通过
- MyBatis 事务:
- 事务范围
- MyBatis 事务:
- 主要针对 MyBatis 的操作,事务的控制相对简单。
- Spring 事务:
- 可以跨多个持久化层和服务层操作,支持更复杂的事务管理。
- MyBatis 事务:
- 事务传播行为
- MyBatis 事务:
- 没有内置的事务传播机制,需要手动实现。
- Spring 事务:
- 提供多种事务传播行为(如
REQUIRED、REQUIRES_NEW),可以灵活管理事务的传播和隔离级别。
- 提供多种事务传播行为(如
- MyBatis 事务:
- 集成支持
- MyBatis 事务:
- 主要与 MyBatis 自身的会话管理结合。
- Spring 事务:
- 支持多种持久化框架和不同的事务管理器,易于集成。
- MyBatis 事务:
总结:
- MyBatis 事务:手动控制,适合简单场景。
- Spring 事务:声明式管理,支持复杂事务和多种持久化框架。
- 事务管理方式
-
MyBatis 中
StatementHandler和MappedStatement区别?在 MyBatis 中,
StatementHandler和MappedStatement的区别如下:- MappedStatement
- 定义:表示 SQL 映射语句的元数据,包括 SQL 语句、参数类型、返回类型等信息。
- 作用:用于配置和描述特定的 SQL 语句及其相关信息,通常在 XML 映射文件或注解中定义。
- StatementHandler
- 定义:用于执行 SQL 语句的接口,负责创建和管理
PreparedStatement。 - 作用:处理 SQL 执行的具体逻辑,包括参数设置、执行查询和处理结果集。
总结:
- MappedStatement:用于描述 SQL 映射及其元数据。
- StatementHandler:负责执行 SQL 语句的具体实现。
-
MyBatis 常用的
TypeHandler有哪些?MyBatis 常用的
TypeHandler包括以下几种:- BasicTypeHandler:
- 默认的类型处理器,处理基本类型(如
int、String等)与数据库类型之间的映射。
- 默认的类型处理器,处理基本类型(如
- EnumTypeHandler:
- 用于处理 Java 枚举类型与数据库值之间的映射。
- DateTypeHandler:
- 用于处理
java.util.Date、java.sql.Date和java.sql.Timestamp等日期类型。
- 用于处理
- JsonTypeHandler:
- 用于处理 JSON 字符串与 Java 对象之间的映射,通常与 JSON 库(如 Jackson 或 Gson)结合使用。
- BlobTypeHandler:
- 用于处理 BLOB(二进制大对象)数据类型的映射,适合存储二进制数据。
- BlobTypeHandler:
- 用于处理 CLOB(字符大对象)数据类型的映射,适合存储大文本数据。
- BasicTypeHandler:
-
MyBatis 执行流程是怎样的?
MyBatis 的执行流程如下:
- 创建 SqlSessionFactory:
- 从 MyBatis 配置文件中读取配置信息,创建
SqlSessionFactory实例。
- 从 MyBatis 配置文件中读取配置信息,创建
- 打开 SqlSession:
- 通过
SqlSessionFactory打开一个SqlSession,开始数据库操作。
- 通过
- 映射语句的调用:
- 调用 Mapper 接口中的方法,传入参数,MyBatis 根据方法名查找对应的
MappedStatement。
- 调用 Mapper 接口中的方法,传入参数,MyBatis 根据方法名查找对应的
- 执行 SQL 语句:
StatementHandler根据MappedStatement创建 SQL 语句,并执行数据库操作(如查询、插入、更新等)。
- 处理结果:
- 将数据库返回的结果集映射为 Java 对象(实体),并返回给调用者。
- 提交或回滚事务:
- 如果是手动管理事务,根据操作结果选择提交或回滚事务。
- 关闭 SqlSession:
- 关闭
SqlSession,释放资源。
- 关闭
总结:MyBatis 的执行流程从创建
SqlSessionFactory到关闭SqlSession,包括 SQL 映射、执行和结果处理等步骤。 - 创建 SqlSessionFactory:
-
MyBatis 中的
SglSession是线程安全的吗?MyBatis 中的
SqlSession不是线程安全的。每个SqlSession实例应当在一个线程内独立使用,不能被多个线程共享。为了确保线程安全,通常的做法是每个线程都创建自己的SqlSession实例,使用完成后及时关闭。 -
MyBatis 中的
SglSession有哪些实现类?在 MyBatis 中,
SqlSession的主要实现类包括:- DefaultSqlSession:
- MyBatis 默认的
SqlSession实现,提供了基本的数据库操作功能。
- MyBatis 默认的
- SqlSessionManager:
- 用于管理多个
SqlSession的生命周期,支持事务控制。
- 用于管理多个
- SqlSessionTemplate(Spring 集成):
- 提供线程安全的
SqlSession实现,适用于 Spring 环境,支持 Spring 的事务管理。
- 提供线程安全的
- DefaultSqlSession:
-
MyBatis 中的
DefaultSqlSession为什么不是线程安全的?DefaultSqlSession在 MyBatis 中不是线程安全的,主要原因包括:- 状态管理:
DefaultSqlSession维护了内部状态,如连接、事务和缓存等,这些状态在多个线程中共享可能导致数据不一致。
- 资源共享:
- 它包含对数据库连接的引用和其他资源,多个线程同时访问可能导致并发问题。
- 设计目的:
SqlSession设计为短暂的、一次性的会话,旨在处理单一数据库操作,适合在一个线程中使用。
- 状态管理:
-
MyBatis 中
SqlSessionTemplate与SqlSessionManager的区别?SqlSessionTemplate和SqlSessionManager在 MyBatis 中的区别如下:- 用途
- SqlSessionTemplate:用于在 Spring 环境中提供线程安全的
SqlSession,支持 Spring 的事务管理。适合在 Spring Bean 中使用。 - SqlSessionManager:用于管理多个
SqlSession的生命周期,提供事务控制和批量处理功能。适合在需要手动管理SqlSession的场景中使用。
- SqlSessionTemplate:用于在 Spring 环境中提供线程安全的
- 线程安全
- SqlSessionTemplate:线程安全,可以被多个线程共享,适合在多线程环境中使用。
- SqlSessionManager:本身并不保证线程安全,通常在每个线程中创建独立的
SqlSession。
- 事务管理
- SqlSessionTemplate:自动与 Spring 的事务管理集成,简化事务处理。
- SqlSessionManager:提供手动的事务控制,适合复杂的事务管理场景。
总结:
- SqlSessionTemplate:线程安全,适合 Spring 环境,自动集成事务管理。
- SqlSessionManager:管理多个
SqlSession,不保证线程安全,适合手动事务控制。
- 用途
-
MyBatis 配置文件中的 SQL id 是否能重复?
在 MyBatis 配置文件中,SQL
id不能重复。id是每个 SQL 语句的唯一标识,用于在Mapper接口中引用特定的 SQL 语句。如果同一个id重复,MyBatis 会抛出异常,导致系统无法正常工作。因此,确保每个
id在同一Mapper文件中都是唯一的,以避免冲突。 -
Mybatis 能执行一对一、一对多的关联查询吗?
当然可以,不止支持一对一、一对多的关联查询,还支持多对多、多对一的关联查询。

MyBatis级联 - 一对一<association>
比如订单和支付是一对一的关系,这种关联的实现:
实体类:
12345678910public class Order {private Integer orderId;private String orderDesc;/*** 支付对象*/private Pay pay;//……}结果映射
12345678910<!-- 订单resultMap --><resultMap id="peopleResultMap" type="cn.fighter3.entity.Order"><id property="orderId" column="order_id" /><result property="orderDesc" column="order_desc"/><!--一对一结果映射--><association property="pay" javaType="cn.fighter3.entity.Pay"><id column="payId" property="pay_id"/><result column="account" property="account"/></association></resultMap>查询就是普通的关联查
12345<select id="getTeacher" resultMap="getTeacherMap" parameterType="int">select * from order oleft join pay p on o.order_id=p.order_idwhere o.order_id=#{orderId}</select>- 一对多
<collection>
比如商品分类和商品,是一对多的关系。
实体类
12345678910public class Category {private int categoryId;private String categoryName;/*** 商品列表**/List<Product> products;//……}结果映射
123456789101112<resultMap type="Category" id="categoryBean"><id column="categoryId" property="category_id" /><result column="categoryName" property="category_name" /><!-- 一对多的关系 --><!-- property: 指的是集合属性的值, ofType:指的是集合中元素的类型 --><collection property="products" ofType="Product"><id column="product_id" property="productId" /><result column="productName" property="productName" /><result column="price" property="price" /></collection></resultMap>查询就是一个普通的关联查询
1234<!-- 关联查询分类和产品表 --><select id="listCategory" resultMap="categoryBean">select c.*, p.* from category_ c left join product_ p on c.id = p.cid</select>那么多对一、多对多怎么实现呢?还是利用<association>和<collection>,篇幅所限,这里就不展开了。
-
MyBatis 的$和# 传参的区别?
在 MyBatis 中,
$和#传参的区别如下:#(安全的参数占位符):- 使用
#时,MyBatis 会对传入的参数进行预处理,防止 SQL 注入。 - 适用于 SQL 语句中的参数替换,例如:
SELECT * FROM users WHERE id = #{id}。
- 使用
$(直接字符串替换):- 使用
$时,MyBatis 直接将参数作为字符串替换,不进行任何处理。 - 适用于动态表名、列名等场景,例如:
SELECT * FROM ${tableName}。 - 由于不安全,容易引发 SQL 注入,需谨慎使用。
- 使用
-
MyBatis映射文件的增删改是否需要返回值类型
不需要,因为增删改返回值都是int类型,无需特别指定
-
MyBatis映射文件Mapper标签中的namespace的作用以及注意事项
作用:实现和dao层或mapper层接口的绑定 namespace称为命名空间
namespace和对应接口的全限定名且唯一
-
简要说明映射文件中id属性的作用
id属性标识唯一的标签,和对应mapper接口中的方法名一致
-
MyBatis中多参绑定的方式有哪些
使用#{param1}代表第一个参数#{param2}代表第二个参数以此类推
使用#{arg0}代表第一个参数#{arg1}代表第二个参数以此类推
在持久层方法的形参上添加@Param(name)的方式,在映射文件中使用#{name}获取
-
在MyBatis中#{param}和${param}的区别
在MyBatis中#{param}使用预编译方式,可以有效防止sql注入
${param}使用sql拼接的方式,无法防止sql注入,常用于模糊查询以及分页操作
-
MyBatis中如何获取添加自动生成的主键
两种方式:全局配置,局部配置
全局配置:
(1)在配置文件中添加如下内容:
123<settings><settings name="useGeneratedKeys" value="true"></settings>(2)在添加标签上添加keyProperty属性并指定接受的属性名
局部配置:
在添加标签上设置 useGeneratedKeys="true"和keyProperty="接收的属性名"
-
MyBatis核心配置文件中的常用标签
properties 加载数据库参数
settings 设置返回主键
typeAliases 设置别名
environments 设置数据源
mappers 设置映射资源
-
在MyBatis的配置文件中Settings标签可以设置哪些内容
开启二级缓存、配置日志、设置使用生成主键、设置获取值为空的字段
-
简述MyBatis中动态标签有哪些
where 当where中任意条件成立时,在sql中添加where关键字。所有条件都不成立,则不拼接where关键字,去掉第一个条件的and关键字
if 判断操作 里面使用test 如
set 当set标签中的条件成立时,拼接set关键字,如果条件不成立,则不拼接,去除最后一个符合条件的逗号
trim 可以指定前缀(perfix="")后缀(suffix="")以及去除多余的符号(suffixoverrides="")
foreach 遍历集合或列表,指定开始标识和结束标识,可以指定每次循环的拼接符号,常用于批量删除添加操作
12345678collection :结果集1、如果入参是list、数组、map类型的可以直接写list、collection、array、map;2、或者按照参数的索引位置,arg0、arg1item:集合中的每一个对象index:下标open:循环以某个字符开头close:循环以某个字符结尾separator:循环内容之间的分隔符,会自动去掉多余的分隔符sql 将公共sql片段提取出来,封装在sql标签内 , include引入公共sql片段
12sql片段: <sql id=""> </sql>使用sql片段: <include refid="对应sql片段id"/>choose-when
12345<choose><when test=""></when><when test=""></when><otherwise></otherwise></choose> -
MyBatis中时间一对一、多对多映射的核心标签是?
一对一使用association,一对多使用collection
-
请简述resultType,resultMap属性及resultMap标签的区别
resultType属性 指定结果对应的Java类型
resultMap属性 指定结果对应的映射
resultMap标签 实现实体类属性和表中字段的映射
-
MyBatis的持久层的接口的方法可以重载吗
不能,因为映射文件的id是唯一的
-
MyBatis如何解决多个参数的问题
使用#{param1} #{arg0} 在持久层接口方法形参使用@Param
-
MyBatis的常用标签有哪些
<select>
<update>
<delete>
<insert> -
MyBatis如何调用存储过程
持久层方法没有返回值,因为存储过程没有返回值
映射文件对应SQL的执行器要修改:callable
SQL使用Call关键字调用,#{} 中使用 mode=IN/OUT 标记输入/输出参数。
存储过程的输出的结果会入参的对象
123456statementType:SQL执行器的类型statement:执行普通SQL,不能防止SQL注入prepared:执行普通SQL,可以防止SQL注入callable:执行存储过程或者函数useCache:使用缓存;false是不使用缓存,每次执行的时候都从数据库查询最新的mode:指定参数是输入还是输出参数。in和out -
MyBatis怎么防止入参为空(无效列类型:1111)
在值后面添加 jdbcType #{数据,jdbcType.类型}
-
如何解决Map映射为空的问题
在MyBatis配置文件中添加
123<settings><setting name="callSettersOnNulls" value="true"/></settings> -
MyBatis 是如何进行分页的?分页插件的原理是什么?
MyBatis 进行分页的常用方式是通过 分页插件,如 PageHelper。以下是其基本步骤和原理:
- 使用步骤
- 添加依赖:在项目中添加分页插件的依赖。
- 配置插件:在 MyBatis 配置文件中注册分页插件。
12345<plugins><plugin interceptor="com.github.pagehelper.PageHelper"><property name="dialect" value="mysql"/> <!-- 数据库类型 --></plugin></plugins> - 调用分页方法:在查询前设置分页参数。
12PageHelper.startPage(pageNum, pageSize); // 设置当前页和每页大小List<User> users = userMapper.findAll(); // 查询数据
- 原理
- 拦截器:分页插件通过 MyBatis 的插件机制拦截 SQL 执行。
- SQL 修改:插件修改原始 SQL,添加
LIMIT和OFFSET以实现分页。 - 结果封装:将结果封装成分页对象,包含总记录数和分页数据。
- 使用步骤
-
MyBatis 有几种分页方式?
MyBatis 有以下几种分页方式:
- 使用分页插件:如 PageHelper,通过拦截器自动处理 SQL 进行分页。
- 手动分页:在 SQL 中手动添加
LIMIT和OFFSET,根据传入的参数控制分页。 - 使用 RowBounds:使用
RowBounds对象进行内存中的分页,不改变原始 SQL。
-
MyBatis 逻辑分页和物理分页的区别是什么?
- 逻辑分页
- 定义:逻辑分页是指在应用层面进行分页处理,查询所有数据后再在内存中进行分页。
- 特点:
- 所有数据一次性加载到内存中,适合数据量小的场景。
- 可能会导致性能问题,因为需要处理完整的数据集。
- 实现方式:通过
RowBounds或手动切分结果集。
- 物理分页
- 定义:物理分页是指在数据库层面通过 SQL 语句进行分页,仅查询需要的数据。
- 特点:
- 只查询当前页的数据,节省了内存和网络传输资源。
- 更适合大数据量的场景,性能更优。
- 实现方式:通过
LIMIT和OFFSET或使用分页插件(如 PageHelper)。
- 总结
- 逻辑分页:在应用层处理,适合小数据集,可能影响性能。
- 物理分页:在数据库层处理,适合大数据集,性能更佳。
- 逻辑分页
-
MyBatis 流式查询有什么用?
- 减少内存占用
逐行处理查询结果,避免一次性加载所有数据到内存中。 - 提高性能
允许在结果加载时进行后续操作,缩短响应时间。 - 适用于大数据集
有效解决无法一次性加载大数据集的问题。 - 示例
使用ResultHandler逐行处理结果:
1234567sqlSession.select("namespace.selectStatement", new ResultHandler<User>() {@Overridepublic void handleResult(ResultContext<? extends User> resultContext) {User user = resultContext.getResultObject();// 逐行处理 user 对象}});
- 减少内存占用
-
MyBatis 与Hibernate,JdbcTemplate有哪些不同?
- 易用性:Hibernate > MyBatis > JdbcTemplate
- 性能:JdbcTemplate > MyBatis > Hibernate
- 灵活性:MyBatis > JdbcTemplate > Hibernate
-
为什么说 MyBatis 是半自动 ORM 映射工具?它与全自动的区别在哪里?
Hibernate 属于全自动ORM 映射工具,使用Hibernate 查询关联对象或者关联集合对象时,可以根据对象关系模型直接获取,所以它是全自动的。 … 而Mybatis 在查询关联对象或关联集合对象时,需要手动编写sql 来完成,所以,称之为半自动ORM 映射工具。
-
MyBatis 和JDBC有什么区别?
总之,MyBatis 提供了更多的自动化和简化,而 JDBC 需要更多手动控制。
MyBatis 和 JDBC 的区别主要有:- 代码简化:MyBatis 简化了 JDBC 中繁琐的数据库操作代码,如连接管理、结果集处理,而 JDBC 需要手动编写大量代码。
- SQL 映射:MyBatis 自动将 SQL 结果映射到 Java 对象,JDBC 需要手动解析结果集。
- 动态 SQL 支持:MyBatis 支持动态生成 SQL,而 JDBC 中 SQL 是固定的,需要手动拼接。
- 事务管理:MyBatis 集成了事务管理,JDBC 需要手动处理事务。
-
Hibernate 和 MyBatis 有什么区别?
相同点
- 都是对 jdbc 的封装,都是应用于持久层的框架。
不同点
1)映射关系
- MyBatis 是一个半自动映射的框架,配置 Java 对象与 sql 语句执行结果的对应关系,多表关联关系配置简单
- Hibernate 是一个全表映射的框架,配置 Java 对象与数据库表的对应关系,多表关联关系配置复杂
2)SQL 优化和移植性
- Hibernate 对 SQL 语句封装,提供了日志、缓存、级联(级联比 MyBatis 强大)等特性,此外还提供 HQL(Hibernate Query Language)操作数据库,数据库无关性支持好,但会多消耗性能。如果项目需要支持多种数据库,代码开发量少,但 SQL 语句优化困难。
- MyBatis 需要手动编写 SQL,支持动态 SQL、处理列表、动态生成表名、支持存储过程。开发工作量相对大些。直接使用 SQL 语句操作数据库,不支持数据库无关性,但 sql 语句优化容易。
3)MyBatis 和 Hibernate 的适用场景不同

Mybatis vs Hibernate - Hibernate 是标准的 ORM 框架,SQL 编写量较少,但不够灵活,适合于需求相对稳定,中小型的软件项目,比如:办公自动化系统
- MyBatis 是半 ORM 框架,需要编写较多 SQL,但是比较灵活,适合于需求变化频繁,快速迭代的项目,比如:电商网站
-
MyBatis 是否支持延迟加载?如果支持,它的实现原理是什么?
- 延迟加载就是按需加载,在需要查询的时候再去查询,使用延迟加载可以避免表连接查询,表连接查询比单表查询的效率低,但是它需要多次与数据库进行交互,所以延迟加载并不是银弹,使用需谨慎。
- Mybatis仅支持association关联对象和collection关联集合对象的延迟加载,association指的就是一对一,collection指的就是一对多查询。在Mybatis配置文件中,可以配置是否启用延迟加载lazyLoadingEnabled=true|false。
- 原理:使用CGLIB创建目标对象的代理对象,当调用目标方法时,进入拦截器方法,比如调用A.getB().getName(),拦截器invoke()方法发现A.getB()是null值,那么就会单独发送事先保存好的查询关联B对象的sql,把B查询上来,然后调用A.setB(b),于是a的对象b属性就有值了,接着完成A.getB().getName()方法的调用。这就是延迟加载的基本原理。
-
MyBatis什么时候建立和断开数据库连接?
这个要看是否使用了数据库连接池,如果没有的话,MyBatis 是在真正执行SQL前才去开启一个会话,然后去获取数据库连接执行SQL。
-
Xml 映射文件中,除了常见的 select|insert|update|delete 标签之外,还有哪些标签?
还有很多其他的标签,
<resultMap>、<parameterMap>、<sql>、<include>、<selectKey>,加上动态 sql 的 9 个标签,trim|where|set|foreach|if|choose|when|otherwise|bind等,其中为 sql 片段标签,通过<include>标签引入 sql 片段,<selectKey>为不支持自增的主键生成策略标签。 -
MyBatis动态 sql 是做什么的?都有哪些动态 sql?能简述一下动态 sql 的执行原理不?
MyBatis 动态 SQL 用于根据条件动态生成 SQL 语句,避免写多个 SQL。
常用动态 SQL:
<if>:条件判断。<choose>:类似switch-case。<trim>:去除多余的前后缀。<where>:自动添加WHERE。<set>:处理UPDATE语句。<foreach>:循环生成 SQL,常用于IN子句。
执行原理:根据传入参数,动态解析 SQL 标签生成最终 SQL,并执行。
-
MyBatis 怎么封装动态 SQL?
在 MyBatis 中,封装动态 SQL 可以通过以下几种方式实现:
- XML 映射文件
使用动态 SQL 标签,如<if>和<choose>:
12345678910<select id="findUsers" resultType="User">SELECT * FROM usersWHERE 1=1<if test="name != null">AND name = #{name}</if><if test="status != null">AND status = #{status}</if></select>
- 注解方式
在 Mapper 接口中使用注解和脚本:
12345678910111213@Select({"<script>","SELECT * FROM users","WHERE 1=1","<if test='name != null'>","AND name = #{name}","</if>","<if test='status != null'>","AND status = #{status}","</if>","</script>"})List<User> findUsers(@Param("name") String name, @Param("status") String status);
- 查询条件对象
定义一个查询条件对象,封装参数:
12345public class UserQuery {private String name;private String status;// getters and setters}
在 XML 中使用:
12345678910<select id="findUsers" resultType="User">SELECT * FROM usersWHERE 1=1<if test="name != null">AND name = #{name}</if><if test="status != null">AND status = #{status}</if></select>
- XML 映射文件
-
MyBatis trim 标签有什么用?
MyBatis 中的
<trim>标签用于处理 SQL 语句的前后缀,简化 SQL 的构建过程。它的主要作用是去除多余的分隔符(如AND、OR),确保生成的 SQL 语句语法正确。主要功能:
- 去除前缀:
- 可以在 SQL 语句开始前去除特定的前缀(如
AND或OR)。
- 可以在 SQL 语句开始前去除特定的前缀(如
- 去除后缀:
- 可以在 SQL 语句结束后去除特定的后缀(如
AND或OR)。
- 可以在 SQL 语句结束后去除特定的后缀(如
- 处理空值:
- 只有在满足某个条件时,才会添加对应的 SQL 部分。
示例:
12345678910111213<select id="findUsers" resultType="User">SELECT * FROM users<where><trim prefix="WHERE" prefixOverrides="AND |OR "><if test="name != null">AND name = #{name}</if><if test="status != null">AND status = #{status}</if></trim></where></select>总结:
<trim>标签可以有效管理 SQL 语句中的多余分隔符,使动态 SQL 的构建更加灵活和简洁。 - 去除前缀:
-
MyBatis where 标签有什么用?
MyBatis 中的
<where>标签用于自动处理 SQL 语句中的WHERE子句,主要功能包括:- 自动添加
WHERE:在有条件时自动插入WHERE关键字。 - 去除多余的
AND或OR:如果条件成立,自动去除多余的AND或OR,确保 SQL 语法正确。
示例:
1234567891011<select id="findUsers" resultType="User">SELECT * FROM users<where><if test="name != null">AND name = #{name}</if><if test="status != null">AND status = #{status}</if></where></select> - 自动添加
-
MyBatis 中的缓存机制有啥用?
MyBatis 中的缓存机制用于提高查询性能,减少对数据库的重复访问。它包括:
- 一级缓存:SqlSession 级别的缓存,默认开启,同一个 SqlSession 中的相同查询结果会缓存,减少重复查询。
- 二级缓存:Mapper 级别的缓存,可以跨 SqlSession,缓存同一个 Mapper 下的查询结果,需手动配置。
缓存机制减少数据库压力,提升应用性能。
-
MyBatis 一级缓存和二级缓存的区别?
MyBatis 一级缓存和二级缓存的区别:
- 缓存范围:
- 一级缓存:SqlSession 级别,默认开启,作用范围仅在同一个 SqlSession 内。
- 二级缓存:Mapper 级别,可以跨 SqlSession,需手动配置。
- 生效时机:
- 一级缓存:每次使用同一个 SqlSession 执行相同查询时生效。
- 二级缓存:不同 SqlSession 执行相同查询时也可生效。
- 失效条件:
- 一级缓存:SqlSession 关闭、提交或执行更新操作后失效。
- 二级缓存:数据更新后失效,但配置持久化时缓存内容可保存。
- 缓存范围:
-
MyBatis 一级缓存和二级缓存是什么数据结构?
MyBatis 一级缓存和二级缓存都使用 HashMap 作为数据结构来存储缓存数据。
-
MyBatis 中的缓存有哪些实现类型?
MyBatis 中的缓存实现类型主要有两种:
- PerpetualCache(永久缓存):默认的缓存实现,基于 HashMap 存储数据。
- Decorator 缓存:通过装饰器模式增强缓存功能,包括:
- LruCache:最近最少使用缓存淘汰策略。
- FifoCache:先进先出缓存淘汰策略。
- SoftCache:使用软引用,内存不足时自动回收。
- WeakCache:使用弱引用,GC 后自动回收。
- ScheduledCache:定时清理缓存。
- SynchronizedCache:线程安全的缓存。
- SerializedCache:序列化存储缓存内容。
这些类型提供了不同的缓存管理策略,适应不同的需求。
-
MyBatis 默认会开启缓存机制吗? 怎么开启?
MyBatis 默认开启一级缓存,一级缓存是 SqlSession 级别的,无需额外配置。
二级缓存默认关闭,需要手动开启。开启方法如下:
- 在
mybatis-config.xml中开启全局二级缓存:
123<settings><setting name="cacheEnabled" value="true"/></settings>
- 在对应的 Mapper 文件或 Mapper 接口中,通过
@CacheNamespace注解或 XML 配置开启二级缓存:
1<cache/>
这样 MyBatis 的二级缓存就会被启用。
- 在
-
MyBatis 为什么默认不会开启二级缓存?
MyBatis 默认不启用二级缓存,主要是出于以下考虑:
- 数据一致性问题:二级缓存是跨 SqlSession 的,数据更新后如果没有及时刷新缓存,可能导致脏数据(缓存与数据库不一致)。
- 内存占用:二级缓存存储在内存中,可能会占用较多内存资源,影响系统性能。
- 适用场景有限:二级缓存适合查询频繁、更新较少的场景,但并不适合所有项目,默认关闭可以避免不必要的性能开销。
因此,MyBatis 让开发者根据实际需求手动开启二级缓存。
-
MyBatis 中的缓存什么时候会被清理?
MyBatis 中缓存的清理时机如下:
- 一级缓存(SqlSession 级别缓存):
- 当
SqlSession关闭时,一级缓存会被清理。 - 当在同一个
SqlSession中执行INSERT、UPDATE或DELETE操作时,一级缓存会自动清空,确保数据一致性。 - 当手动调用
clearCache()方法时,也会清理一级缓存。
- 当
- 二级缓存(Mapper 级别缓存):
- 当执行
INSERT、UPDATE或DELETE操作时,二级缓存会被清除,确保数据一致性。 - 二级缓存也可以通过自定义的缓存策略(如时间策略或大小限制)自动清理。
- 如果使用了带有过期策略的缓存装饰器(如
ScheduledCache),缓存会根据设定的时间间隔清理。 - 可以通过调用
clearCache()方法手动清除二级缓存。
- 当执行
总结来说,缓存会在数据库发生修改操作或通过特定策略、手动清理时被清理,以保证数据的一致性和缓存的有效性。
- 一级缓存(SqlSession 级别缓存):
-
MyBatis 二级缓存清理策略有哪些?
MyBatis 二级缓存的清理策略主要有:
- 自动清理:执行
INSERT、UPDATE或DELETE操作时,缓存会自动清空。 - 基于时间的清理:使用
ScheduledCache,按照设定的时间间隔清理缓存。 - 基于缓存淘汰策略:
- LruCache:最近最少使用的缓存项会被清除。
- FifoCache:按照先入先出的顺序清理缓存。
- 手动清理:可以通过调用
clearCache()方法手动清除缓存。
- 自动清理:执行
-
说说 Mybatis 的一级、二级缓存?
- 一级缓存: 基于 PerpetualCache 的 HashMap 本地缓存,其存储作用域为 SqlSession,各个 SqlSession 之间的缓存相互隔离,当 Session flush 或 close 之后,该 SqlSession 中的所有 Cache 就将清空,MyBatis 默认打开一级缓存。

Mybatis一级缓存 - 二级缓存与一级缓存其机制相同,默认也是采用 PerpetualCache,HashMap 存储,不同之处在于其存储作用域为 Mapper(Namespace),可以在多个 SqlSession 之间共享,并且可自定义存储源,如 Ehcache。默认不打开二级缓存,要开启二级缓存,使用二级缓存属性类需要实现 Serializable 序列化接口(可用来保存对象的状态),可在它的映射文件中配置。

-
MyBatis 如何执行批量操作?

MyBatis批量操作 第一种方法:使用 foreach 标签
foreach 的主要用在构建 in 条件中,它可以在 SQL 语句中进行迭代一个集合。foreach 标签的属性主要有 item,index,collection,open,separator,close。
- item 表示集合中每一个元素进行迭代时的别名,随便起的变量名;
- index 指定一个名字,用于表示在迭代过程中,每次迭代到的位置,不常用;
- open 表示该语句以什么开始,常用“(”;
- separator 表示在每次进行迭代之间以什么符号作为分隔符,常用“,”;
- close 表示以什么结束,常用“)”。
在使用foreach 的时候最关键的也是最容易出错的就是 collection 属性,该属性是必须指定的,但是在不同情况下,该属性的值是不一样的,主要有以下 3 种情况:
- 如果传入的是单参数且参数类型是一个 List 的时候,collection 属性值为 list
- 如果传入的是单参数且参数类型是一个 array 数组的时候,collection 的属性值为 array
- 如果传入的参数是多个的时候,我们就需要把它们封装成一个 Map 了,当然单参数也可以封装成 map,实际上如果你在传入参数的时候,在 MyBatis 里面也是会把它封装成一个 Map 的,map 的 key 就是参数名,所以这个时候 collection 属性值就是传入的 List 或 array 对象在自己封装的 map 里面的 key
看看批量保存的两种用法:
12345678<!-- MySQL下批量保存,可以foreach遍历 mysql支持values(),(),()语法 --> //推荐使用<insert id="addEmpsBatch">INSERT INTO emp(ename,gender,email,did)VALUES<foreach collection="emps" item="emp" separator=",">(#{emp.eName},#{emp.gender},#{emp.email},#{emp.dept.id})</foreach></insert>12345678<!-- 这种方式需要数据库连接属性allowMutiQueries=true的支持如jdbc.url=jdbc:mysql://localhost:3306/mybatis?allowMultiQueries=true --><insert id="addEmpsBatch"><foreach collection="emps" item="emp" separator=";">INSERT INTO emp(ename,gender,email,did)VALUES(#{emp.eName},#{emp.gender},#{emp.email},#{emp.dept.id})</foreach></insert>第二种方法:使用 ExecutorType.BATCH
- Mybatis 内置的 ExecutorType 有 3 种,默认为 simple,该模式下它为每个语句的执行创建一个新的预处理语句,单条提交 sql;而 batch 模式重复使用已经预处理的语句,并且批量执行所有更新语句,显然 batch 性能将更优; 但 batch 模式也有自己的问题,比如在 Insert 操作时,在事务没有提交之前,是没有办法获取到自增的 id,在某些情况下不符合业务的需求。
具体用法如下:
1234567891011121314151617181920212223242526//批量保存方法测试@Testpublic void testBatch() throws IOException{SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();//可以执行批量操作的sqlSessionSqlSession openSession = sqlSessionFactory.openSession(ExecutorType.BATCH);//批量保存执行前时间long start = System.currentTimeMillis();try {EmployeeMapper mapper = openSession.getMapper(EmployeeMapper.class);for (int i = 0; i < 1000; i++) {mapper.addEmp(new Employee(UUID.randomUUID().toString().substring(0, 5), "b", "1"));}openSession.commit();long end = System.currentTimeMillis();//批量保存执行后的时间System.out.println("执行时长" + (end - start));//批量 预编译sql一次==》设置参数==》10000次==》执行1次 677//非批量 (预编译=设置参数=执行 )==》10000次 1121} finally {openSession.close();}}- mapper 和 mapper.xml 如下
1234public interface EmployeeMapper {//批量保存员工Long addEmp(Employee employee);}
1234567<mapper namespace="com.jourwon.mapper.EmployeeMapper"<!--批量保存员工 --><insert id="addEmp">insert into employee(lastName,email,gender)values(#{lastName},#{email},#{gender})</insert></mapper>
-
MyBatis 都有哪些 Executor 执行器?它们之间的区别是什么?
MyBatis 有三种基本的 Executor 执行器,SimpleExecutor 、 ReuseExecutor 、 BatchExecutor 。
SimpleExecutor :每执行一次 update 或 select,就开启一个 Statement 对象,用完立刻关闭 Statement 对象。
ReuseExecutor :执行 update 或 select,以 sql 作为 key 查找 Statement 对象,存在就使用,不存在就创建,用完后,不关闭 Statement 对象,而是放置于 Map<String, Statement>内,供下一次使用。简言之,就是重复使用 Statement 对象。
BatchExecutor :执行 update(没有 select,JDBC 批处理不支持 select),将所有 sql 都添加到批处理中(addBatch()),等待统一执行(executeBatch()),它缓存了多个 Statement 对象,每个 Statement 对象都是 addBatch()完毕后,等待逐一执行 executeBatch()批处理。与 JDBC 批处理相同。
作用范围:Executor 的这些特点,都严格限制在 SqlSession 生命周期范围内。
-
MyBatis 中如何指定使用哪一种 Executor 执行器?
在 MyBatis 配置文件中,可以指定默认的 ExecutorType 执行器类型,也可以手动给 DefaultSqlSessionFactory 的创建 SqlSession 的方法传递 ExecutorType 类型参数。
-
MyBatis 可以映射到枚举类吗?
- 默认映射:
- 如果枚举名称与数据库字段值相同,MyBatis 会自动映射。
123public enum Status {ACTIVE, INACTIVE;}
- 如果枚举名称与数据库字段值相同,MyBatis 会自动映射。
- 自定义类型处理器:
- 如果需要自定义映射,可以实现
BaseTypeHandler。12345678910public class StatusTypeHandler extends BaseTypeHandler<Status> {@Overridepublic void setNonNullParameter(PreparedStatement ps, int i, Status parameter, JdbcType jdbcType) throws SQLException {ps.setString(i, parameter.name());}@Overridepublic Status getNullableResult(ResultSet rs, String columnName) throws SQLException {return Status.valueOf(rs.getString(columnName));}}
- 如果需要自定义映射,可以实现
- 在 XML 中指定类型处理器:
- 在 SQL 映射中指定使用自定义类型处理器。
123<resultMap id="userMap" type="User"><result property="status" column="status_column" typeHandler="com.example.StatusTypeHandler"/></resultMap>
- 在 SQL 映射中指定使用自定义类型处理器。
总结:MyBatis 支持直接映射枚举或使用自定义类型处理器进行映射。
- 默认映射:
-
MyBatis 执行批量插入,能返回数据库主键列表吗?
能,JDBC 都能,MyBatis 当然也能。
-
Mybatis 是如何将 sql 执行结果封装为目标对象并返回的?都有哪些映射形式?
第一种是使用 标签,逐一定义列名和对象属性名之间的映射关系。
第二种是使用 sql 列的别名功能,将列别名书写为对象属性名,比如 T_NAME AS NAME,对象属性名一般是 name,小写,但是列名不区分大小写,MyBatis 会忽略列名大小写,智能找到与之对应对象属性名,你甚至可以写成 T_NAME AS NaMe,MyBatis 一样可以正常工作。有了列名与属性名的映射关系后,MyBatis 通过反射创建对象,同时使用反射给对象的属性逐一赋值并返回,那些找不到映射关系的属性,是无法完成赋值的。
-
如何编写一个插件
跟实现 Servlet Filter、Spring Interceptor 类似,我们需要先实现 MyBatis 的 Interceptor 接口来写具体的实现,然后通过注解指定切点,最后需要在全局配置文件中声明一下这个插件。
-
-
MyBatisPlus
-
MybatisPlus是什么?
只需简单配置,即可快速进行单表CRUD操作,从而节省大量时间。并且支持大量数据库,包括国产达梦、人大金仓等数据库。
-
BaseMapper有哪些你常用的方法?
插入:insert(user);
删除:
- 根据id删除单条:deleteById(id);
- 批量删除:deleteBatchIds(idList);
修改:updateById(user);
查询:
- 根据id查询:selectById(id);
- 查询全部:selectList(null);
-
Service有哪些自带常用方法?
- 查询记录数:count();
- 批量插入:saveBatch(List<User> users);
-
用过MybatisPlus的哪些注解?分别解释下都是什么作用?
(1)@TableName
MybatisPlus默认表名与实体类名对应,但如果你实体类名与表名不一样,则要用到此注解。比如实体类名为User,数据库表名为t_user,则默认不会对应,你需要在实体类中加入@TableName("t_user")注解。
(2)@TableId
MybatisPlus默认对应的主键名为id,也就是说如果你实体类名为id,数据库表主键名也是id,则默认可以对应,但如果你实体类名和数据库主键名都为uid,则对应失败报错,所以这时候用到@TableId(value="uid")注解。
(3)@TableField
MyBatis-Plus在执行SQL语句时,要保证实体类中的属性名和表中的字段名一致。如果实体类中的属性名和字段名不一致则用到此注解。
(4)@TableLogic
用做逻辑删除,将此注解置于逻辑删除列上。
-
如何带条件组装一条查询语句?
使用QueryWrapper,QueryWrapper有很多方法,如like、between、isNotNull、orderByDesc等方法。
1234567891011@Testpublic void test01(){//查询用户名包含a,年龄在20到30之间,并且邮箱不为null的用户信息//SELECT id,username AS name,age,email,is_deleted FROM t_user WHERE is_deleted=0 AND (username LIKE ? AND age BETWEEN ? AND ? AND email IS NOT NULL)QueryWrapper<User> queryWrapper = new QueryWrapper<>();queryWrapper.like("username", "a").between("age", 20, 30).isNotNull("email");List<User> list = userMapper.selectList(queryWrapper);list.forEach(System.out::println);} -
如何带条件拼接一条update语句?
123456789101112131415@Testpublic void test07() {// 将(年龄大于20或邮箱为null)并且用户名中包含有a的用户信息修改// 组装set子句以及修改条件UpdateWrapper<User> updateWrapper = new UpdateWrapper<>();// lambda表达式内的逻辑优先运算updateWrapper.set("age", 18).set("email", "user@atguigu.com").like("username", "a").and(i -> i.gt("age", 20).or().isNull("email"));int result = userMapper.update(null, updateWrapper);System.out.println(result);} -
MybatisPlus如何实现子查询?
123456789@Testpublic void test06() {// 查询id小于等于3的用户信息// SELECT id,username AS name,age,email,is_deleted FROM t_user WHERE (id IN (select id from t_user where id <= 3))QueryWrapper<User> queryWrapper = new QueryWrapper<>();queryWrapper.inSql("id", "select id from t_user where id <= 3");List<User> list = userMapper.selectList(queryWrapper);list.forEach(System.out::println);} -
MybatisPlus如何实现分页功能?
两种方式可以实现。
8.1 分页插件方式
(1)添加配置类
123456789101112@Configuration@MapperScan("com.oracle.mapper")public class MybatisPlusConfig {@Beanpublic MybatisPlusInterceptor mybatisPlusInterceptor() {MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));return interceptor;}}(2)使用selectPage方法查询
123456789101112131415@Testpublic void testPage(){// 设置分页参数Page<User> page = new Page<>(1, 5);userMapper.selectPage(page, null);// 获取分页数据List<User> list = page.getRecords();list.forEach(System.out::println);System.out.println("当前页:"+page.getCurrent());System.out.println("每页显示的条数:"+page.getSize());System.out.println("总记录数:"+page.getTotal());System.out.println("总页数:"+page.getPages());System.out.println("是否有上一页:"+page.hasPrevious());System.out.println("是否有下一页:"+page.hasNext());}8.2 xml自定义分页
(1)mapper中定义接口
1234567/*** 根据年龄查询用户列表,分页显示* @param page 分页对象,xml中可以从里面进行取值,传递参数 Page 即自动分页,必须放在第一位* @param age 年龄* @return*/IPage<User> selectPageVo(@Param("page") Page<User> page, @Param("age") Integer age);(2)mapper.xml实现
123456<!--SQL片段,记录基础字段--><sql id="BaseColumns">id,username,age,email</sql><select id="selectPageVo" resultType="com.oracle.pojo.User">SELECT <include refid="BaseColumns"></include> FROM t_user WHERE age > #{age}</select>(3)调用接口
123456789101112131415@Testpublic void testSelectPageVo(){// 设置分页参数Page<User> page = new Page<>(1, 5);userMapper.selectPageVo(page, 20);// 获取分页数据List<User> list = page.getRecords();list.forEach(System.out::println);System.out.println("当前页:"+page.getCurrent());System.out.println("每页显示的条数:"+page.getSize());System.out.println("总记录数:"+page.getTotal());System.out.println("总页数:"+page.getPages());System.out.println("是否有上一页:"+page.hasPrevious());System.out.println("是否有下一页:"+page.hasNext());} -
MybatisPlus如何实现乐观锁?
我们都知道乐观锁是通过一个版本号字段来实现的,首先你的数据库要有个version字段。
然后实体类要在version属性上添加注解@Version。
12345678@Datapublic class Product {private Long id;private String name;private Integer price;@Version // 标识乐观锁版本号private Integer version;}添加乐观锁插件配置:
123456789101112131415161718192021222324package com.oracle.config;import com.baomidou.mybatisplus.annotation.DbType;import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;import com.baomidou.mybatisplus.extension.plugins.inner.OptimisticLockerInnerInterceptor;import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;import org.mybatis.spring.annotation.MapperScan;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;@Configuration@MapperScan("com.oracle.mapper")public class MybatisPlusConfig {@Beanpublic MybatisPlusInterceptor mybatisPlusInterceptor() {MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));// 添加乐观锁插件interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor());return interceptor;}}
-
-
Spring Cloud/Alibaba/Dubbo
-
什么是微服务?
微服务架构是一种架构风格,它提倡将单一应用程序划分成一组小的服务,每个服务运行在其独立的自己的进程中,服务之间互相协调、互相配合,为用户提供最终价值。服务之间采用轻量级的通信机制互相沟通(通常是基于HTTP的RESTful API)。举个简单例子来说,我们以前都是单一的Web项目,包含着比如订单功能、支付功能、物流功能、日志功能等。但微服务是要你将这些功能按业务进行拆分,每个功能是一个SpringBoot项目,每个项目互相通信。
-
微服务有哪些优缺点?
优点:
每个服务足够内聚,足够小,代码容易理解这样能聚焦一个指定的业务功能或业务需求。
微服务是松稠合的。
微服务能使用不同的语言开发。
每个微服务都有自己的存储能力,可以有自己的数据库,也可以有统一数据库。缺点:
多服务运维难度,随着服务的增加,运维的压力也在增大。
服务间通信成本。
数据一致性。 -
微服务、分布式、集群的区别?
分布式:一个业务分拆多个子业务,部署在不同的服务器上。
集群:同一个业务,部署在多个服务器上。去饭店吃饭就是一个完整的业务,饭店的厨师、配菜师、传菜员、服务员就是分布式;厨师、配菜师、传菜员和服务员都不止一个人,这就是集群;分布式就是微服务的一种表现形式,分布式是部署层面,微服务是设计层面。 -
什么是Eureka?
Eureka 是一个 Spring Cloud Netflix 的一款老牌注册中心,设计用于实现云端部署微服务架构中的服务注册与发现功能。在技术领域,特别是分布式系统中,Eureka 作为一个基于 RESTFul 的服务,主要职责包括:服务注册:允许服务实例向 Eureka Server 注册自己的信息。这样,每个服务实例都能让 Eureka Server 获取到自身服务以及地址等信息。
服务发现:Eureka 客户端可以从 Eureka Server 查询到注册的服务实例信息,进而实现客户端的软负载均衡和故障转移。服务消费者可以查询 Eureka Server 获取到提供某一服务的所有服务实例列表,然后根据策略选择一个实例进行通信。
健康检查:Eureka 通过心跳机制监控服务实例的状态,确保服务列表的时效性和准确性。如果某个服务实例宕机或无法响应,Eureka Server 将从注册表中移除该实例,避免了将流量导向不可用的服务(默认 90s)。
高可用性:Eureka 通过部署多个 Eureka Server 实例并相互复制注册信息,可以构建高可用的服务注册中心集群,提高系统的整体稳定性。在 Spring Cloud 中,Eureka 被集成作为服务注册与服务发现的核心组件,通过 @EnableEurekaServer 和 @EnableEurekaClient 注解可以轻松实现服务注册中心或服务客户端。Eureka 在 2020 年后 Netflix 宣布不再积极维护,但它仍然是许多现有系统中服务注册中心的实现方案,并且有社区进行维护。 -
什么是Eureka的自我保护机制?
一句话总结:某时刻某一个微服务不可用 ,Eureka不会立刻清理,依旧会对该微服务的信息进行保存。Eureka的自我保护模式正是一种针对网络异常波动的安全保护措施,使用自我保护模式能使Eureka集群更加的健壮、稳定的运行。在正常情况下,Eureka客户端会定期向Eureka服务器发送心跳,以表明它仍然存活和可用。如果Eureka服务器在配置的时间间隔内未能从某个服务实例接收到心跳,它通常会将该实例从注册列表中移除,认为该实例不可用。然而,在自我保护模式下,如果Eureka服务器在短时间内丢失了对大量服务实例的心跳(15分钟内超过85%的客户端),它会认为这是一个网络问题,而不是所有这些服务实例都突然不可用。因此,服务器将进入自我保护模式。
-
SpringCloud有哪些服务注册中心?它们都有什么区别?
分别有Eureka、Consul、Zookeeper、Nacos等。一致性模型:一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)
AP 模型:Eureka
CP 模型:Zookeeper、Consul
AP 或 CP 模型:Nacos使用场景:
Eureka:与 Spring Cloud 紧密集成,是 Java 微服务应用的首选之一,使用门槛低,配置简单,适合中小型微服务项目。
Zookeeper:适用于Hadoop、HBase、Kafka 等大数据生态系统,作为协调服务。
Nacos:与 Spring Cloud Alibaba 无缝集成,适合国内市场,且社区活跃度高。
Consul:支持多语言客户端(如 Go、Java、Python 等),与 Kubernetes、Docker 等云原生技术兼容性好。 -
什么是Ribbon?
Ribbon是基于Netflix Ribbon实现的一套客户端负载均衡的工具。
简单的说,Ribbon是Netflix发布的开源项目,主要功能是提供客户端的软件负载均衡算法和服务调用。
一句话解释Ribbon,就是 负载均衡 + RestTemplate调用。 -
刚才你提到了RestTemplate,那么RestTemplate有什么常用的方法吗?
(1)getForObject方法/getForEntity方法(GET请求方法)。
getForObject():返回对象为响应体中数据转化成的对象,基本上可以理解为Json。
getForEntity():返回对象为ResponseEntity对象,包含了响应中的一些重要信息,比如响应头、响应状态码、响应体等。(2)postForObject方法/postForEntity方法(POST请求方法)。 -
Ribbon有哪些负载规则?
1、RoundRobinRule 轮询。
2、RandomRule 随机。
3、RetryRule 先按照RoundRobinRule的策略获取服务,如果获取服务失败则在指定时间内会进行重试,获取可用的服务。
4、WeightedResponseTimeRule 对RoundRobinRule的扩展,响应速度越快的实例选择权重越大,越容易被选择。
5、BestAvailableRule 会先过滤掉由于多次访问故障而处于断路器跳闸状态的服务,然后选择一个并发量最小的服务。
6、AvailabilityFilteringRule 先过滤掉故障实例,再选择并发较小的实例。
7、ZoneAvoidanceRule 默认规则,复合判断server所在区域的性能和server的可用性选择服务器。 -
Ribbon默认的轮询规则的原理是什么?
默认负载轮训算法:rest接口第几次请求数 % 服务器集群总数量 = 实际调用服务器位置下标,每次服务重启动后rest接口计数从1开始。我们的客户端现有2台机器,我们是第一次请求,那么按公式算就是1%2=1。
-
什么是Feign?
Feign 是一个声明式的 Web 服务客户端。所谓的声明式就是指不需要编写复杂的关于 Http 请求的东西。只需要声明一个一个接口,然后在这个接口上添加一些注解,这些注解包括了请求的方法(如 GET 和 POST)、请求的 URL 等信息。Feign 在运行时通过注解和接口上定义的内容来动态构造和发送 Http 请求。所以使用 Feign,开发者只需要定义服务接口并通过注解指明服务名和参数等信息,Feign 就能自动完成 Http 请求的构建、发送和结果处理。Feign 也是 Spring Cloud Netflix 组件之一,结合 Spring Cloud 的服务注册和发现、负载均衡等功能,能够让服务间的调用变得更加方便。总体来说,Feign 的主要特点有:
1、声明式的服务客户端,通过 Java 接口和注解构建服务客户端,简化了 Http 调用的使用过程,无需手动构建 HTTP 请求
2、很好地融入了 SpringCloud 生态,可以使用 SpringCloud 负载均衡、服务熔断等能力 -
Feign是如何实现负载均衡的?
Feign 是一个声明式的 Http 客户端调用工具,它使得开发者可以更加方便地调用远程服务。开发者只需要定义一个接口,并不需要写关于如何发送 Http 请求的代码。Feign 本身并没有负载均衡的能力,它负载均衡的能力需要依赖其它的框架。目前在 SpringCloud 体系下,主要有两个框架可以配合 Feign 实现负载均衡:Ribbon
loadbalancer
Ribbon 也是最开始配合 Feign 实现负载均衡的框架。loadbalancer 是 SpringCloud 团队自己写的,主要是因为 Ribbon 后面停止维护了,所以 SpringCloud 团队写了一个 loadbalancer 来替代 Ribbon。 -
为什么Feign第一次调用耗时很长?
这个主要是由于 Feign 内置的负载均衡组件 Ribbon 的懒加载机制。当第一次进行服务调用的时候,Feign 才会触发 Ribbon 的加载流程,然后从服务注册中心拉取服务列表,建立起对应的连接池,这个过程会增加第一次调用的耗时。解决方案:
1、主动预热:只需要在应用启动的时候进行服务预热,先自动执行一次随便的调用,提前加载 Ribbon 以及其他相关的服务调用组件。
2、开启 Ribbon 的饥饿加载12345# application.yml 配置ribbon:eager-load:enabled: trueclients: clientA, clientB配置说明:
ribbon.eager-load.enabled:将其设置为 true,表示启用 Ribbon 的饥饿加载机制。
ribbon.eager-load.clients:指定需要进行饥饿加载的 Feign 客户端列表,用逗号分隔。这些客户端的 Ribbon 配置和服务实例信息将在应用启动时预先加载。 -
Feign与OpenFeign的区别?
Feign是Spring Cloud组件中的一个轻量级RESTful的HTTP服务客户端。Feign内置了Ribbon,用来做客户端负载均衡,去调用服务注册中心的服务。Feign的使用方式是:使用Feign的注解定义接口,调用这个接口,就可以调用服务注册中心的服务。
OpenFeign是Spring Cloud在Feign的基础上支持了SpringMVC的注解,如@RequesMapping等等。OpenFeign的@Feignclient可以解析SpringMvc的@RequestMapping注解下的接口,并通过动态代理的方式产生实现类,实现类中做负载均衡并调用其他服务。
<dependency> <groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-feign</artifactId>
</dependency>
<dependency> <groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
-
简单讲一讲OpenFeign的超时控制?
我们在使用OpenFeign进行调用接口时,如果因为某些原因,调用时间过长,会导致报错。OpenFeign默认等待1秒钟,超过后报错。也就是说如果你调用接口总共花了3秒时间,超过1秒不返回直接就报错了。为了避免这样的情况,有时候我们需要设置Feign客户端的超时控制。
-
什么是OpenFeign日志增强?
说白了就是对Feign接口的调用情况进行监控和输出。
有以下四种日志级别:
NONE:默认的,不显示任何日志。
BASIC:仅记录请求方法、URL、响应状态码及执行时间。
HEADERS:除了BASIC中定义的信息之外,还有请求和响应的头信息。
FULL:除了HEADERS中定义的信息之外,还有请求和响应的正文及元数据。
-
什么是Hystrix?
Hystrix 是由 Netflix 开源的一个熔断器框架。它的核心思想是通过隔离、熔断、降级等机制,防止服务调用的雪崩效应,保证服务在出现异常时能够快速恢复。
-
什么是服务雪崩?
服务雪崩是指在微服务架构或分布式系统中,由于某个服务不可用或性能下降,导致依赖它的其他服务也出现连锁故障,最终使整个系统或大部分服务不可用的现象。
主要原因
服务调用链复杂
- 在微服务架构中,各个服务之间存在大量的相互调用关系。一个服务的不可用或性能下降可能会导致依赖它的多个上游服务响应变慢,甚至出现请求堆积,从而影响到整个调用链。
- 示例:服务 A 调用服务 B,服务 B 调用服务 C。如果服务 C 发生故障且请求无法及时返回,服务 B 的请求将被阻塞,进而导致服务 A 的响应变慢或超时。
重试机制的反作用
- 当服务调用失败时,通常会有重试机制以增加成功的概率。然而,在服务故障或超时情况下,重试机制可能会产生更多的请求,进一步加剧下游服务的压力,导致故障范围扩大。
- 示例:服务 A 调用服务 B,如果服务 B 出现超时,服务 A 可能会发起多次重试,这些重试请求可能会给服务 B 带来更大的压力,最终导致服务 B 的彻底崩溃。
-
什么是服务降级?
服务降级是一种在分布式系统和微服务架构中常用的容错机制,用于在系统压力过大或部分服务出现故障时,暂时减少或关闭某些不必要的功能,从而确保核心功能的正常运行。通过降级,可以提高系统的容错性和可用性。
服务降级的触发场景
服务调用超时或失败:
- 当某个服务的调用时间超过了设定的阈值,或者服务多次调用失败时,可以触发降级机制,返回预设的降级响应,避免长时间等待。
- 示例:当支付服务超时时,可以返回“支付服务暂时不可用,请稍后再试”的提示。
系统负载过高:
- 当系统的负载过高(如 CPU 使用率、内存占用率等)时,可以主动降级某些非核心功能,释放系统资源,确保核心业务的正常运行。
- 示例:在电商促销活动期间,订单服务可以降级不实时显示推荐商品,只展示基础订单信息,以减轻系统负担。
下游服务不可用:
- 如果下游依赖服务不可用或者响应时间过长,可以通过降级机制,返回缓存数据或默认数据,避免请求继续传播,影响用户体验。
- 示例:在查询库存服务不可用时,可以返回“库存信息暂时不可用”的缓存数据。
服务降级的实现框架与工具
Hystrix:
- 简介:Hystrix 是 Netflix 开源的熔断器和降级框架,通过
@HystrixCommand注解可以方便地实现服务的降级逻辑。
- 使用场景:适用于微服务架构中的服务降级和熔断处理,特别是在基于 Spring Cloud 的应用中。
- 替代品:Hystrix 已经进入维护模式,推荐使用 Resilience4j 作为替代方案。
Resilience4j:
- 简介:Resilience4j 是一个轻量级的容错框架,支持熔断、限流、降级等功能,采用函数式编程风格,适合与 Spring Boot 2.x 集成。
- 优势:更高效的性能,更现代化的设计,支持异步编程,适合在新的微服务项目中使用。
- 使用场景:可以通过配置降级方法实现服务降级,在请求失败或超时时提供备用响应。
Sentinel:
- 简介:Sentinel 是阿里巴巴开源的服务限流降级框架,提供流量控制、熔断降级、系统自适应保护等功能。
- 优势:与 Spring Cloud Alibaba 生态集成良好,适用于国内市场,功能丰富且易于配置。
- 使用场景:在流量高峰期或微服务系统中,通过 Sentinel 实现流量控制和服务降级,提升系统的稳定性。
-
什么是服务熔断?
服务熔断指的是当某个服务的调用失败率持续升高时,通过中断对该服务的请求,防止系统资源被不断消耗,进而保护整个系统不受影响。熔断机制的灵感来源于电路熔断器(保险丝),在出现异常时,通过快速切断服务调用,避免故障进一步扩散。
服务熔断的流程
当一个服务在一段时间内连续出现失败(如超时、请求错误等)并且失败率超过设定的阈值时,熔断器将切换到打开状态,暂时中断对该服务的调用请求。这样可以避免进一步的资源浪费和请求堆积。
经过一段时间后,熔断器会自动进入半开状态,尝试恢复调用,确保服务在故障恢复后,熔断器切换到关闭状态,反之继续打开。
服务熔断的常见触发条件
- 请求失败率高:当一个服务在设定的时间窗口内,连续多次请求失败(如超时、异常、HTTP 5xx 错误等),并且失败率超过设定阈值时,熔断器会自动触发,进入打开状态。
- 请求响应时间长:如果一个服务的响应时间长,导致调用超时,并且这种情况在一定时间内多次发生,熔断器也会触发熔断,阻止继续发送请求。
- 服务不可达:当服务完全不可访问(如网络故障或服务宕机),熔断器可以直接切断请求,快速返回错误,避免进一步的资源浪费。
熔断器的三种状态
Closed(关闭状态)
- 描述:熔断器在正常状态下处于关闭状态,所有请求都会正常发往目标服务。
- 状态转换:当服务调用失败次数或失败率达到阈值时,熔断器会从 Closed 状态变为 Open 状态。
Open(打开状态)
- 描述:当熔断器处于打开状态时,Hystrix 会阻断所有对目标服务的请求,直接返回降级结果。
- 状态转换:经过一段时间后,熔断器会自动进入 Half-Open 状态,尝试发送部分请求,以判断目标服务是否恢复。
Half-Open(半开状态)
- 描述:在半开状态下,部分请求可以尝试发往目标服务。如果这些请求成功率达到设定阈值,熔断器会关闭,恢复正常调用。
- 状态转换:如果半开状态下的请求失败率仍然很高,则熔断器会重新打开。
-
什么是服务限流?
服务限流是一种流量控制策略,它通过限制每秒请求的数量(QPS)、请求频率、并发数等,来保护服务的处理能力,防止系统因为流量过大而出现性能问题或资源耗尽。
服务限流可以认为是服务降级的一种,限流就是通过限制系统请求的输入和输出,从而实现对于系统的保护。这个和降级的概念很像,都是为了保证核心功能的正常运行。
限流是因为服务的吞吐量以及负载这些都是可以预估的,我们为了保证系统的正常运行,可以设置限制的阈值,即通过限制输入或者输出的方式来减少流量的流通,然后实现对于系统的保护。
限流有很多种实现方案,比如说限流算法、延迟解决、拒绝解决等等,保证请求的范围在系统可以接受的阈值以内,实现对系统的保护。 -
Sentinel是什么实现限流的?
12345678910// 原本的业务方法.@SentinelResource(blockHandler = "blockHandlerForGetTest")public Test getTestById(String id) {throw new RuntimeException("getTestById command failed");}// blockHandler 函数,原方法调用被限流/降级/系统保护的时候调用public Test blockHandlerForGetTest(String id, BlockException ex) {return new Test("Test");} -
Hystrix与Sentinel有什么区别吗?
首先它们俩都相当于断路器的作用,用来服务降级、服务熔断、流量控制等功能。
区别在于:
Hystrix
需要我们程序员自己手工搭建监控平台。
没有一套web界面可以给我们进行更加细粒度化得配置流控、速率控制、服务熔断、服务降级。
Sentinel
单独一个组件,可以独立出来。
直接界面化的细粒度统一配置。
-
什么是Zuul?
Spring Cloud Zuul 是 Spring Cloud 官方早期默认推荐的网关组件,不过其由于 2020 年 12 月开始已经停止维护了,其现在逐渐被 Spring Cloud Gateway 所取代。
Zuul 提供了鉴权、路由、限流等功能,可以与 Spring Cloud 的其他组件,比如说 Eureka、Ribbon、Hystrix、Feign 等组件配合实现,实现服务的注册与发现、负载均衡、服务保护、远程调用等功能。
其主要有以下几个方面的功能:
- 鉴权:由于网关的系统流量的入口,因此我们可以在网关处进行权限认证、校验等方面的内容,从而拒绝一些不符合要求的流量。
- 监控:由于网关是微服务架构中系统流量的入口,我们可以针对网关的功能,实现一些接口流量的统计、汇总,从而实现服务监控功能。
- 路由:网关是服务之间进行远程调用链路上的组件,可以结合注册中心实现请求的路由转发。
- 限流:这个点主要是为了服务保护,针对服务实现流量控制,防止服务崩溃。
-
什么是Gateway?
Spring Cloud Gateway 是 Spring Cloud 开源的网关组件,其使用了 WebFlux 框架,充分发挥了响应式编程的特性以及优点,其底层使用了 Netty 作为通信框架,并且包含了 Spring framework 5、SpringBoot 2 以及 Project Reactor 等技术,适配 Spring Cloud 生态体系。
在微服务架构中充当看前端入口点的角色,实现了路由转发、请求过滤、负载均衡等功能。
其主要功能如下:
- 路由转发:Spring Cloud Gateway 可以根据一开始定义的规则将接收到的请求转发到不同的微服务。这种路由功能使得客户端不需要直接了解各个微服务的地址,就可以实现服务的远程调用,提高了系统的可维护性和灵活性。
- 过滤器机制:这个主要是借鉴了 Zuul 的过滤器模式,但是在其基础上进行了改进,即支持非阻塞式异步处理。过滤器链允许在请求的处理过程中添加各种预处理和后处理逻辑,比如身份验证、请求转换、限流、熔断、日志记录等功能,即针对服务的功能都可以通过添加过滤器来进行实现。
- 响应式编程:Spring Cloud Gateway 使用了响应式编程框架 Webflux,充分发挥了响应式编程的优势,在处理大量并发请求的时候,其性能和可伸缩性较好。
- 生态集成良好:Spring Cloud Gateway 由于其是基于 Spring 体系进行开发的,其与 Spring Cloud 生态兼容以及集成较好,可以结合 Nacos、Eureka 等组件,实现服务注册与发现、远程调用等方面的功能。
- 统一管理:由于 Spring Cloud Gateway 是系统流量的统一入口,可以实现服务调用的统一管理,简化服务配置。
-
你项目里为什么选择Gateway作为网关?
选择 Spring Cloud Gateway 的原因主要有两个:
- 以前用得比较多的是 Spring Cloud 官方开源的 Zuul,其用得比较多的还是 1.0 的版本,不过 1.0 版本 Netflix 很早就宣布进入维护状态了。虽然 Zuul 已经出了 2.0 版本,但是 Spring Cloud 官方团队好像没有整合的计划,并且 Netflix 很多相关的组件,如 Eureka、Hystrix 都已经进入维护期了,所以不知道前景如何。然后 Spring Cloud 官方自己研发了 Spring Cloud Gateway,并且大力支持和推荐,所以相比与 Zuul,Gateway 是一个更好的选择。
- Spring Cloud Gateway 有很多的特性:
- 基于 Spring 5 和 Spring Boot 2 进行构建,与 Spring 生态兼容较好
- 动态路由:可以根据配置条件,如 URL、请求方法等实现动态配置
- 可以对路由指定断言(Predicate)和过滤器(Filter)
- 集成 Hystrix 断路器功能,可以实现服务熔断
- 集成 Spring Cloud 相关组件,如 Eureka、Nacos、Consul 等实现服务的注册与发现
- 内置了限流模块,可以根据配置实现服务限流
-
Zuul、Gateway 和 Nginx
Zuul、Gateway 和 Nginx 都是常用的网关技术,但它们在实现和功能方面有一些区别。
Zuul 是 Netflix 开源的一个服务网关,主要用于构建微服务架构中的边缘服务。它提供了动态路由、负载均衡、请求过滤、身份验证、安全性等功能。Zuul 通常与 Netflix 的 Eureka 服务发现框架结合使用,并通过配置路由规则将请求路由到适当的后端服务。
Gateway 是 Spring Cloud 的一部分,用于构建基于 Spring Boot 的微服务网关。它提供了类似于 Zuul 的功能,如路由、负载均衡、请求过滤、安全性等。Gateway 使用 Spring WebFlux 框架和 Reactor 库实现了异步非阻塞的处理模型。它可以与 Spring Cloud 的服务注册与发现组件(如 Eureka 或 Consul)进行集成。
Nginx 是一个高性能的开源 Web 服务器和反向代理服务器。虽然 Nginx 本身并不是专门设计用作网关,但它经常被用作反向代理和负载均衡器,以提供网关功能。Nginx 能够处理并转发 HTTP、HTTPS、SMTP、POP3 和 IMAP 等协议的请求,具有强大的性能和高并发处理能力。Nginx 还支持基于配置的路由和请求过滤功能,可以根据请求的 URL 路径或其他条件将流量路由到后端服务器。
Zuul 和 Gateway 是专门用于构建微服务架构的服务网关,提供了丰富的功能和易于配置的路由规则。而 Nginx 是一个通用的 Web 服务器和反向代理服务器,可以用作网关,但不像 Zuul 和 Gateway 那样专注于微服务架构。
-
GateWay有三个核心概念,你知道是什么吗?
1、Route(路由) – 路由是构建网关的基本模块,它由ID,目标URI,一系列的断言和过滤器组成,如断言为true则匹配该路由。
2、Predicate(断言) – 参考的是Java8的java.util.function.Predicate,开发人员可以匹配HTTP请求中的所有内容(例如请求头或请求参数),如果请求与断言相匹配则进行路由。
3、Filter(过滤) – 指的是Spring框架中GatewayFilter的实例,使用过滤器,可以在请求被路由前或者之后对请求进行修改。
举例:我去医院看牙科(请求),门卫大爷(Filter过滤)说不管你要看什么,必须先做核酸。当我做完核酸后门卫大爷让我进去了。这时我拿着手机上的挂号信息与医院的挂号信息相匹配(Predicate断言),匹配上了我可以找大夫看病了(路由)。
-
GateWay常用的Predicate断言有哪些?
After:比如在某段时间后才可以执行路由。这个After大多用在维护开服时间,比如游戏准备22年10月1日开服,那用After可以设置此时间之后的路由才好使。
Before:与After异曲同工。
Between:在两个时间段内才可执行路由。
Cookie:通过Cookie值去匹配。
Header:根据请求头信息来进行匹配。
-
SpringCloud Config是什么?有什么用处?
config是分布式配置中心,分布式系统面临的问题是,微服务意味着要将单体应用中的业务拆分成一个个子服务,每个服务的粒度相对较小,因此系统中会出现大量的服务。
由于每个服务都需要必要的配置信息才能运行,所以一套集中式的、动态的配置管理设施是必不可少的。
比如你现在有40个微服务都用的一个叫test的数据库,如果我们修改了数据库的名字,那还要每个微服务的配置文件都改一遍吗,所以我们需要Config进行集中式管理。
-
SpringCloud中,使用过全局事件总线bus吗?如果使用过请简单的谈一谈
bus一般配合config进行使用,config配置中心具有一个痛点,就是当你改了配置文件,你需要一个个的手动去通知到下面的服务,这样很麻烦。而bus就轻松的解决了这点,Spring Cloud Bus目前支持RabbitMQ和Kafka。
ConfigClient实例都会监听MQ中同一个topic(默认是Spring Cloud Bus)。当一个服务刷新数据的时候,它会把这个信息放入到Topic中,这样其它监听同一Topic的服务就能得到通知,然后去更新自身的配置。
-
SpringCloud中,使用过Stream消息驱动吗?如果使用过请简单的谈一谈
常见MQ(消息中间件):
- ActiveMQ
- RabbitMQ
- RocketMQ
- Kafka
有没有一种新的技术诞生,让我们不再关注具体MQ的细节,我们只需要用一种适配绑定的方式,自动的给我们在各种MQ内切换。(类似于Hibernate)
Cloud Stream是什么?屏蔽底层消息中间件的差异,降低切换成本,统一消息的编程模型。
其实Hibernate就是这个意思,我们不用关心它用的是oracle还是mysql,它给我们提供了session.create(),我们用就好了,不用关心具体的语法,我们也不可能所有数据库都精通。
比方说我们用到了RabbitMQ和Kafka,由于这两个消息中间件的架构上的不同,像RabbitMQ有exchange,kafka有Topic和Partitions分区。
这些中间件的差异性导致我们实际项目开发给我们造成了一定的困扰,我们如果用了两个消息队列的其中一种,后面的业务需求,我想往另外一种消息队列进行迁移,这时候无疑就是一个灾难性的,一大堆东西都要重新推倒重新做,因为它跟我们的系统耦合了,这时候Spring Cloud Stream给我们提供了—种解耦合的方式。
-
你知道Nacos配置中心的实现原理吗?
Nacos 配置中心的实现原理可以分为以下几个核心部分:
- 配置的存储:
- 企业内 Nacos 一般会使用数据库(如 MySQL)来存储配置数据。配置数据是以键值对的形式存储的,每个配置项对应一个数据 ID(Data ID),并且支持通过 Namespace(命名空间)、Group(组)来进行配置的隔离与分类。
- 配置存储层在 Nacos 集群的任意节点都可以进行读写,通过多副本的数据持久化保证配置的高可用性和可靠性。
- 配置的推送机制:
- Nacos 配置中心使用 gRPC 长连接来实现配置的实时推送。客户端与 Nacos 服务器通过 gRPC 建立长连接,当配置发生变更时,Nacos 服务器可以通过这个长连接实时向客户端推送配置更新。
- 客户端在启动时,会向 Nacos 注册监听器(Listener)并维持与服务器的长连接。当 Nacos 检测到配置变更时,会通知所有相关客户端进行配置刷新。
- 配置的缓存:
- Nacos 客户端维护一个本地缓存,客户端接收到配置更新后,会自动刷新本地缓存的配置。当与 Nacos 服务器的连接出现异常或服务器不可用时,可以从本地缓存中读取配置,保证系统的基本运行不受影响。这个缓存机制也有助于减少服务器压力,提高系统的可用性。(所以面试官问你 Nacos 配置中心挂了实例会立马受到影响吗?答案是不会。)Nacos 1.x 版本只有长轮询机制,2.x 使用的是 gRPC 长连接实现配置更新。
Nacos 的配置管理模型
数据模型:Nacos 使用的核心数据模型包括 Namespace、Group、Data ID,实现了配置的逻辑隔离和分组管理。
- Namespace:用于环境隔离,如 dev、test、prod。
- Group:在同一 Namespace 下进一步对配置进行分组管理,方便针对业务模块进行分类。
- Data ID:每个具体的配置项的唯一标识,通过这个 ID 可以精确定位到某个配置(可以认为是文件名)。
Nacos 配置中心的集群高可用
Nacos 通过多节点的集群部署,保证配置中心的高可用性。
- Nacos 集群至少需要 3 个节点,以确保在某些节点失效时,系统仍然可以正常工作。Nacos 采用了 Raft 协议来实现节点之间的数据一致性,确保配置数据在集群中的一致性。
- 多副本存储:Nacos 支持配置的多副本存储,通过在集群内多节点存储配置数据的方式,避免单点故障问题,提升了服务的可用性。
- 断线重连机制:客户端在与 Nacos 服务器的连接断开时,会自动尝试重新连接,并在连接恢复后同步最新的配置数据,保证配置更新不会因网络问题而丢失。
Nacos 2.x 的改进
gRPC 协议:Nacos 2.x 版本相较于 1.x,做出了显著的优化,将通信机制从 HTTP 长轮询切换为 gRPC。gRPC 基于 HTTP/2 协议,支持更高效的双向流通信,带来了以下优势:
- 高效推送:gRPC 能够实现真正的长连接,支持实时推送,减少了 HTTP 轮询带来的延迟和带宽消耗。
- 多路复用:HTTP/2 支持多路复用,客户端与服务器之间可以通过一个 gRPC 连接传输多路数据流,降低了连接开销。
- 压缩和流式传输:gRPC 支持数据压缩和流式传输,使得在大规模配置更新时的传输更为高效。
这些改进使得 Nacos 在分布式系统中的配置管理和高可用性方面表现更加出色。
- Nacos 客户端维护一个本地缓存,客户端接收到配置更新后,会自动刷新本地缓存的配置。当与 Nacos 服务器的连接出现异常或服务器不可用时,可以从本地缓存中读取配置,保证系统的基本运行不受影响。这个缓存机制也有助于减少服务器压力,提高系统的可用性。(所以面试官问你 Nacos 配置中心挂了实例会立马受到影响吗?答案是不会。)Nacos 1.x 版本只有长轮询机制,2.x 使用的是 gRPC 长连接实现配置更新。
- 配置的存储:
-
为什么需要在服务中使用链路追踪?springcloud有哪些链路追踪的解决方案?
在微服务系统中,少则五六个服务,多则上百个服务,如果某个环节出现问题了,一次调用可能涉及到很多服务。如果服务之间的日志没有关联,那么排查起来非常困难,这个时候就需要链路追踪。
链路追踪可以可视化地追踪请求从一个微服务到另一个微服务的调用情况,从而帮助问题的排查。另外一个方面就是链路追踪还可以帮助优化性能,可视化服务之间的依赖关系,并进行服务的监控与报警。
简单的实现就是在日志中定义一个统一的
TraceId,串联整体调用链路,每个服务之间还会定义一个spanId,标志服务内的调用链路。Spring Cloud 中常用的微服务链路追踪方案
Spring Cloud Sleuth + Zipkin(组合使用简单,集成度高,是 Spring Cloud 生态中常用的链路追踪解决方案):
- Spring Cloud Sleuth 是 Spring Cloud 提供的分布式链路追踪库,它会在每个请求中自动生成
Trace ID和Span ID,并将这些 ID 传递到调用链中的所有服务中,确保请求的追踪信息在各个微服务之间的传递。 - Zipkin 是一种分布式追踪系统,支持收集和展示 Spring Cloud Sleuth 生成的追踪数据。它能够将每个请求的详细路径进行可视化展示,便于开发者分析和排查问题。
Jaeger(Spring Cloud Sleuth + Jaeger):
- Jaeger 是由 CNCF(云原生计算基金会)托管的分布式追踪系统,支持高性能的追踪数据收集和存储。与 Zipkin 相比,Jaeger 更适合大规模分布式系统。
- Spring Cloud Sleuth 可以与 Jaeger 集成,利用 Jaeger 的强大功能进行请求追踪、分析和展示。Jaeger 提供了多维度的查询能力,支持对历史追踪数据的搜索和分析。
- Spring Cloud Sleuth 是 Spring Cloud 提供的分布式链路追踪库,它会在每个请求中自动生成
-
你们的服务是怎么做日志收集的?
我们服务采用的方案是 ELK 那套,Logstash 主要负责从微服务集群采集日志,然后将日志数据发送到 ElasticSearch,ES 主要负责数据的存储和检索,最后 Kibana 就负责日志数据的可视化分析。
- ElasticSearch: ElasticSearch 是一个分布式搜索和分析引擎,可以存储和索引大量的日志数据。它提供了快速的搜索和聚合功能,可以实现大规模日志数据的高效处理。
- Logstash: Logstash 是一个用于采集、过滤和转发日志数据的工具。它可以从文件、消息队列、网络等多种渠道实现日志数据的采集,并对数据进行处理以及转换,最后发到 ElasticSearch 进行存储和索引。
- Kibana: Kibana 是一个日志数据可视化以及分析的工具,它提供了丰富的图表以及仪表盘工具,可以帮助用户实现日志数据的实时监控和分析。
-
什么是Seata?
Seata(Simple Extensible Autonomous Transaction Architecture)是阿里巴巴开源的一款分布式事务解决方案。
其主要是为了解决分布式系统中全局事务的一致性问题。Seata 提供了多种事务模式,包括 AT、TCC、Saga 以及 XA 模式。
在 Seata 中有三个很重要的角色:事务协调者(TC)、事务管理者(TM)以及事务的作业管理器(RM)。
- 事务协调者(TC):主要负责管理全局的分支事务的状态,用于全局性事务的提交和回滚。它会对所有的分支事务进行注册,然后根据各个分支事务的状态来决定整体事务是否提交以及回滚。
- 事务管理者(TM):主要用于开发、提交以及回滚事务。它会根据业务逻辑来决定是否开启一个新事务,并且在适当的情况下进行事务的提交以及回滚操作。
- 资源管理器(RM):这个主要用于分支事务上的资源管理,其向 TC 注册分支事务,上报分支事务的状态,然后接受 TC 的命令来传达给事务管理者(TM)是否要提交或者回滚事务。
-
Seata支持哪些模式的分布式事务?
Seata 目前支持四种事务模式,分别是 AT、TCC、Saga 以及 XA 模式:
- AT 模式:通过代理数据库操作来实现分布式事务管理。Seata 在业务操作前后自动生成回滚日志,在提交时直接提交本地事务,在回滚时利用日志进行数据的还原。
- TCC 模式:是一种两阶段提交。将一个操作拆分为三个步骤:Try(预留资源)、Confirm(确认操作)、Cancel(回滚操作)。开发者需要自己实现每个步骤的逻辑。
- Saga 模式:是一种长事务模式,它将全局事务拆解为多个有序的小事务,每个事务都有对应的补偿操作。若某个事务失败,按照相反的顺序依次调用补偿操作。
- XA 模式:是基于两阶段提交协议(2PC)的标准化分布式事务管理模式。Seata 的 XA 模式通过协调多个资源管理器的事务提交和回滚来实现全局事务的管理。
-
- JVM调优
- 多线程
- 多线程并发
- Netty/NIO
- AI编程
- Cursor
- Cladue
-
Redis
-
Redis为什么这么快?
Redis 之所以如此快,主要有以下几个方面的原因:
- 基于内存:Redis 是一种基于内存的数据库,数据存储在内存中,数据的读写速度非常快,因为内存访问速度比硬盘访问速度快得多。
- 单线程模型:Redis 使用单线程模型,这意味着它的所有操作都是在一个线程内完成的,不需要进行线程切换和上下文切换。这大大提高了 Redis 的运行效率和响应速度。
- 多路复用 I/O 模型:Redis 在单线程的基础上,采用了 I/O 多路复用技术,实现了单个线程同时处理多个客户端连接的能力,从而提高了 Redis 的并发性能。
- 高效的数据结构:Redis 提供了多种高效的数据结构,如哈希表、有序集合、列表等,这些数据结构都被实现得非常高效,能够在 O(1) 的时间复杂度内完成数据读写操作,这也是 Redis 能够快速处理数据请求的重要因素之一。
- 多线程的引入:在 Redis 6.0 中,为了进一步提升 IO 的性能,引入了多线程的机制。采用多线程,使得网络处理的请求并发进行,就可以大大的提升性能。多线程除了可以减少由于网络 I/O 等待造成的影响,还可以充分利用 CPU 的多核优势。
-
如何解决Redis和数据库一致性的问题?
为了保证Redis和数据库的数据一致性,肯定是要缓存和数据库双写了。
一般来说,在业内有3种比较常见的具体方案:
- 先更新数据库,再删除缓存。
- 延迟双删:先删除缓存,再更新数据库,再删除一次缓存
- cache-aside:更新数据库,基于 binlog 监听进行缓存删除
-
redis的集群模式有哪些?
Redis有三种主要的集群模式,用于在分布式环境中实现高可用性和数据复制。这些集群模式分别是:主从复制(Master-Slave Replication)、哨兵模式(Sentinel)、Redis Cluster模式。
-
简单介绍一下主从模式
主从复制是Redis最简单的集群模式。这个模式主要是为了解决单点故障的问题,所以将数据复制到多个副本中,这样即使有一台服务器出现故障,其他服务器依然可以继续提供服务。主从模式中,包括一个主节点(Master)和一个或多个从节点(Slave)。主节点负责处理所有写操作和读操作,而从节点则复制主节点的数据,并且只能处理读操作。当主节点发生故障时,可以将一个从节点升级为主节点,实现故障转移(需要手动实现)。

优点:主从复制的优势在于简单易用,适用于读多写少的场景。
缺点:不具备故障自动转移的能力,没有办法做容错和恢复。 - 请介绍一下哨兵模式
为了解决主从模式的无法自动容错及恢复的问题,Redis引入了一种哨兵模式的集群架构。哨兵模式是在主从复制的基础上加入了哨兵节点。哨兵节点是一种特殊的Redis节点,用于监控主节点和从节点的状态。当主节点发生故障时,哨兵节点可以自动进行故障转移,选择一个合适的从节点升级为主节点,并通知其他从节点和应用程序进行更新。 在原来的主从架构中,引入哨兵节点,其作用是监控Redis主节点和从节点的状态。通常需要部署多个哨兵节点,以确保故障转移的可靠性。
在原来的主从架构中,引入哨兵节点,其作用是监控Redis主节点和从节点的状态。通常需要部署多个哨兵节点,以确保故障转移的可靠性。
工作原理
哨兵节点定期向所有主节点和从节点发送PING命令,如果在指定的时间内未收到PONG响应,哨兵节点将该节点标记为主观下线。如果一个主节点被多数哨兵节点标记为主观下线,那么它将被标记为客观下线。
当主节点被标记为客观下线时,哨兵节点会触发故障转移过程。它会从所有健康的从节点中选择一个新的主节点,并将所有从节点切换到新的主节点,实现自动故障转移。同时,哨兵节点会更新所有客户端的配置,指向新的主节点。
哨兵节点通过发布订阅功能来通知客户端有关主节点状态变化的消息。客户端收到消息后,会更新配置,将新的主节点信息应用于连接池,从而使客户端可以继续与新的主节点进行交互。
优点:为整个集群提供了一种故障转移和恢复的能力。
-
介绍一下Cluster模式
Redis Cluster是Redis推荐的分布式集群解决方案。它将数据自动分片到多个节点上,每个节点负责一部分数据。

Redis Cluster采用主从复制模式来提高可用性。每个分片都有一个主节点和多个从节点。主节点负责处理写操作,而从节点负责复制主节点的数据并处理读请求。Redis Cluster能够自动检测节点的故障。当一个主节点失去连接或不可达时,Redis Cluster会尝试将该节点标记为不可用,并从可用的从节点中提升一个新的主节点。
Redis Cluster是适用于大规模应用的解决方案,它提供了更好的横向扩展和容错能力。它自动管理数据分片和故障转移,减少了运维的负担。
Cluster模式的特点是数据分片存储在不同的节点上,每个节点都可以单独对外提供读写服务。不存在单点故障的问题。
- 缓存策略
- 穿透/雪崩解决方案
-
-
Kafka
-
Kafka为什么这么快?
Kafka是一个成熟的消息队列,一直以性能高著称,它之所以能够实现高吞吐量和低延迟,主要是由于以下几个方面的优化。我试着从发送端、存储端以及消费端分别介绍一下。消息发送
- 批量发送:Kafka通过将多个消息打包成一个批次,减少了网络传输和磁盘写入的次数,从而提高了消息的吞吐量和传输效率。
- 异步发送:生产者可以异步发送消息,不必等待每个消息的确认,这大大提高了消息发送的效率。
- 消息压缩:支持对消息进行压缩,减少网络传输的数据量。
- 并行发送:通过将数据分布在不同的分区(Partitions)中,生产者可以并行发送消息,从而提高了吞吐量。
消息存储
- 零拷贝技术:Kafka使用零拷贝技术来避免了数据的拷贝操作,降低了内存和CPU的使用率,提高了系统的性能。
- 顺序写入磁盘:Kafka将数据顺序写入磁盘,避免了随机写入带来的性能损耗。
- 页缓存:Kafka将其数据存储在磁盘上,但在访问数据时,它会先将数据加载到内存中的页缓存中,从而提高了数据访问速度。
- 稀疏索引:Kafka存储消?息是通过分段的日志文件,每个分段都有自己的索引文件。这些索引文件中的条目不是对分段中的每条消息都建立索引,而是每隔一定数量的消息建立一个索引点,这就构成了稀疏索引。稀疏索引减少了索引大小,使得加载到内存中的索引更小,提高了查找特定消息的效率。
- 分区和副本:Kafka采用分区和副本的机制,可以将数据分散到多个节点上进行处理,从而实现了分布式的高可用性和负载均衡。
消息消费
- 消费者群组:通过消费者群组可以实现消息的负载均衡和容错处理。
- 并行消费:不同的消费者可以独立地消费不同的分区,实现消费的并行处理。
- 批量拉取:Kafka支持批量拉取消息,可以一次性拉取多个消息进行消费。减少网络消耗,提升性能。
生产消息 (Production Messages) 存储消息 (Storage Messages) 消费消息 (Consumption Messages) 批量发送 (Bulk Send) 磁盘顺序写入 (Disk Sequential Write) 消费者群组 (Consumer Group) 异步发送 (Asynchronous Send) 页缓存 (Page Cache) 批量拉取 (Bulk Pull) 消息压缩 (Message Compression) 稀疏索引 (Sparse Index) 并行消费 (Parallel Consumption) 并行发送 (Parallel Send) 零拷贝 (Zero Copy) 分区和副本 (Partition and Replica)
-
- Elasticsearch
- MySQL
- 分库分表
- 读写分离
- 性能优化
- PostgresSQL
-
RabbitMQ
- RocketMQ
- Zookeeper
- Etcd
- Docker
- Kubernetes
- 服务网格/lstio
- 性能调优
- JVM
- GC
- SQL
- 网格
- 全链路监控
- Metrics
- Tracing
- Logging
- Prometheus
- SkyWalking
- ELK
- 安全漏洞
- OWASP Top 10
- 加密认证
- OAuth2.0
- JWT
- 高并发
- 分布式事务
- 分布式锁
- 高并发
- 物联网
- mqtt
- Vue2/3
- React
- 集群部署
- redis的集群部署
- nacos的集群部署
-
其他
-
反射
-
什么是 JPA?
JPA(Java Persistence API)是 Java 平台的标准规范,用于管理 Java 对象与数据库之间的持久化。它主要特点包括:
- 对象关系映射(ORM):将 Java 对象映射到数据库表。
- 持久化上下文:管理实体生命周期,确保数据一致性。
- 查询语言:提供 JPQL(Java Persistence Query Language)用于查询实体。
- 事务管理:支持与 JTA 集成,管理事务。
- 厂商独立性:支持多种实现(如 Hibernate、EclipseLink)。
总结:JPA 简化了 Java 应用程序的数据库操作,提供标准化的持久化解决方案。
- log4j日志级别有哪些log4j定义了8个级别的log(除去OFF和ALL,可以说分为6个级别),优先级从低到高依次为:OFF、FATAL、ERROR、WARN、INFO、DEBUG、TRACE、 ALL。
了解:
ALL: 最低等级的,用于打开所有日志记录
DEBUG:主要用于开发过程中打印一些运行信息。
INFO: 消息在粗粒度级别上突出强调应用程序的运行过程。
WARN: 表明会出现潜在错误的情形
ERROR: 指出虽然发生错误事件,但仍然不影响系统的继续运行
FATAL: 指出每个严重的错误事件将会导致应用程序的退出。
OFF:用于关闭所有日志记录 -
什么是CGLIB?
CGLIB是一个强大的、高性能的代码生成库,它可以在运行时动态地生成字节码,从而实现对Java类的扩展。它可以在不修改源代码的情况下,为类添加方法、属性、构造器等,并且可以实现AOP(面向切面编程)等功能。
CGLIB使用ASM框架来生成字节码,相对于JDK动态代理,它可以代理非接口类型的类,因此它更加强大和灵活。在Spring、Hibernate等框架中,都广泛使用了CGLIB来实现动态代理。
总之,CGLIB是Java中一款非常强大的代码生成库,它可以帮助我们在运行时动态地修改类的行为,实现更加灵活和强大的功能。
示例:12345678910111213141516171819202122232425262728293031323334353637383940import net.sf.cglib.proxy.Enhancer;import net.sf.cglib.proxy.MethodInterceptor;import net.sf.cglib.proxy.MethodProxy;import java.lang.reflect.Method;public class ProxyDemo {public static void main(String[] args) {// 创建目标对象UserService userService = new UserServiceImpl();// 创建CGLIB代理对象Enhancer enhancer = new Enhancer();enhancer.setSuperclass(UserServiceImpl.class);enhancer.setCallback(new MethodInterceptor() {@Overridepublic Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {System.out.println("before method " + method.getName());Object result = method.invoke(userService, objects);System.out.println("after method " + method.getName());return result;}});UserService proxy = (UserService) enhancer.create();// 调用代理对象的方法proxy.addUser("张三");}}interface UserService {void addUser(String name);}class UserServiceImpl implements UserService {@Overridepublic void addUser(String name) {System.out.println("add user: " + name);}}在上面的示例代码中,我们使用CGLIB创建了一个代理对象,并在代理对象的方法执行前后输出了一些信息。运行该代码,输出结果如下:
123before method addUseradd user: 张三after method addUser
-