Base:一种 Acid 的替代方案
原文链接: BASE: An Acid Alternative
数据库 ACID,都不陌生:原子性、一致性、隔离性和持久性,这在单台服务器就能搞定的时代,很容易实现,但是到了现在,面对如此庞大的访问量和数据量,单台服务器已经不可能适应了,而 ACID 在集群环境,几乎不可能达到我们的预期,保证了 ACID,效率就会大幅度下降,更要命的是,这么高的要求,不好扩展~于是又了 CAP 原则(Consistency(一致性)、Availability(可用性)、Partition tolerance(分区容错性))和 BASE 原则(Basically Available(基本可用)、Soft state(软状态)、Eventually consistent(最终一致)),看看它们的英文,Availability/Basically Available,Consistency/Eventually consistent,基本上,BASE 原则对 CAP 原则的进一步诠释。
本文是Ebay的架构师在2008年发表给ACM的文章,是一篇解释BASE原则,或者说最终一致性的经典文章. 文中Dan讨论了BASE与ACID原则的基本差异, 以及如何设计大型网站以满足不断增长的可伸缩性需求,期间如何对业务做调整与折衷. 以及一些具体的折衷技术的介绍.
在对数据库进行分区后,为了可用性(Availability)牺牲部分一致性(Consistency)可以显著的提升系统的可伸缩性(Scalability).
——By DAN PRITCHETT, EBAY ,Translated by Jametong
Web应用在过去10年变得越来越普及.无论是为最终用户还是为应用开发者构建的应用,对这个应用的希望很可能都是,此应用被最广泛的用户使用-广泛的使用会带来交易的增长.业务如果依赖于持久化,数据存储就很可能成为瓶颈.
扩展任何应用都有两种策略.第一种,也是最简单的一种,就是 纵向扩展 :将应用迁移到更大更强的计算机上. 目前可用的最大的机器也满足不了它的容量是它最明显的限制.纵向扩展也很昂贵,增加交易容量通常都需要购买下一个更大的机器.纵向扩展通常还会产生对供应商的依赖,从而进一步增加成本.
横向扩展 (Horizontal Scaling)提供了更多的灵活性,但也会显著的增加复杂度.横向数据扩展可能沿着两个方向发展.按 功能扩展 (Functional Scaling)牵涉到按功能对数据进行分组,并将不同的功能组分布在多个不同的数据库上.在功能内部将数据拆分到多个数据库上,也就是进行 分片 (Sharding),它为横向扩展增加一个新的维度.图-1简要阐释了横向数据扩展策略.
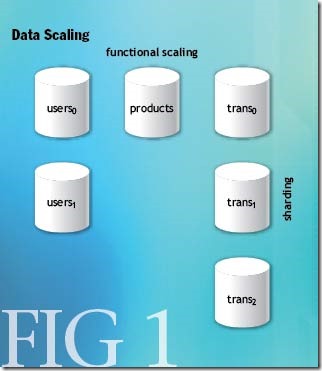
图-1
如图-1所示,横向扩展的两种方法可以同时进行运用.用户信息(Users)、产品信息(Products)与交易信息 (Transactions)可以存储在不同的数据库中.另外,每个功能区域根据其交易容量(transactional capacity)可以再拆分到多个数据库中.如图所示,功能区域可以相互独立地进行扩展.
功能分区(Functional Partitioning)
功能分区对于实现高可伸缩性相当重要.每一种好的数据库架构都会根据功能将概要(Schema)分解到多张表中.用户(Users)、产品 (Products)、交易(Transactions)以及通讯都是功能分区的例子. 常用的方法是,利用诸如外键(foreign key)一类的数据库概念来维持这些功能区域之间的数据一致性.
依赖数据库的约束保证功能组之间的一致性,会导致数据库的不同概要(schema)在部署策略上高度耦合.要支持约束,表必须存在单一的数据库服务器上,当交易率(transaction rate)增长时也无法对其进行横向扩展.很多情况下, 将数据的不同功能组迁移到相互独立的数据库服务器上是最容易实现的向外扩展(Scale-out)方案.
可扩展到非常高的交易量的概要会将不同的功能的数据放置在不同的数据库服务器上.这需要将数据之间的约束从数据库迁移到应用中去. 同时这也将引入一些新的挑战,本文的后续内容会对此进行深入探讨.
CAP定理(CAP Theorem)
Eric Brewer,一位加州大学伯克利分校的教授,Inktomi公司的共同创办人以及首席科学家,作出了以下推测,Web服务无法同时满足以下3个属性(由其首字母构成缩写CAP):
- 一致性(Consistency).客户端知道一系列的操作都会同时发生(生效).
- 可用性(Availability).每个操作都必须以可预期的响应结束.
- 分区容错性(Partition tolerance).即使出现单个组件无法可用,操作依然可以完成.
具体地讲,在任何数据库设计中,一个Web应用至多只能同时支持上面的两个属性.显然,任何横向扩展策略都要依赖于数据分区;因此,设计人员必须在一致性与可用性之间做出选择.
ACID解决方案
ACID数据库事务极大地简化了应用开发人员的工作.正如其缩写标识所示,ACID事务提供以下几种保证:
- 原子性(Atomicity).事务中的所有操作,要么全部成功,要么全部不做.
- 一致性(Consistency).在事务开始与结束时,数据库处于一致状态.
- 隔离性(Isolation). 事务如同只有这一个操作在被数据库所执行一样.
- 持久性(Durability). 在事务结束时,此操作将不可逆转.(也就是只要事务提交,系统将保证数据不会丢失,即使出现系统Crash,译者补充).
数据库厂商在很久以前就认识到数据库分区的必要性,并引入了一种称为2PC(两阶段提交)的技术来提供跨越多个数据库实例的ACID保证.这个协议分为以下两个阶段:
- 第一阶段,事务协调器要求每个涉及到事务的数据库预提交(precommit)此操作,并反映是否可以提交.
- 第二阶段,事务协调器要求每个数据库提交数据.
如果有任何一个数据库否决此次提交,那么所有数据库都会被要求回滚它们在此事务中的那部分信息.这样做的缺陷是什么呢? 我们可以在分区之间获得一致性.如果Brewer的猜测是对的,那么我们一定会影响到可用性,但,怎么可以这样呢?
任何系统的可用性都是执行操作的相关组件的可用性的产物.此陈述的后半段尤其重要.系统中可能会使用但又不是必需的组件,不会降低系统的可用性.在两阶段提交中涉及到两个数据库的事务,它的可用性是这两个数据库中每一个的可用性的产物.例如,如果我们假设每个数据库都有为99.9%的可用性,那么这个事务的可用性就是99.8%,或者说每月43分钟的额外停机时间.
关于两阶段提交,你可以看看"改变未来的九大算法",里边有精辟的讲解~
一种ACID的替代方案
如果ACID为分区的数据库提供一致性的选择,那么你如何实现可用性呢?答案是BASE(基本上可用、软(弱)状态、最终一致性).
BASE与ACID截然相反.ACID比较悲观,在每个操作结束时都强制保持一致性,而BASE比较乐观,接受数据库的一致性处于一种动荡不定的状态.虽然,听起来很难应付,实际上这相当好管理,并且可带来ACID无法企及的更高级别的可伸缩性.
BASE的可用性是通过支持局部故障而不是系统全局故障来实现的.下面是一个简单的例子:如果用户分区在5个数据库服务器上,BASE设计鼓励类似的处理方式,这样一个用户数据库的故障只会影响这台特定主机上的那20%的用户.这里不涉及任何魔法,不过,它确实可以带来更高的可感知的系统可用性.
因此,到目前为止,你已经将数据分解到了多个功能组中,并将最繁忙的功能组分区到了多个数据库中,如何在你的应用中应用BASE原则呢?与ACID 的典型应用场景相比,BASE需要对逻辑事务中的操作进行更加深入的分析.到底该如何进行分析呢?后续的内容将提供部分指导原则.
一致性模式(Consistency Patterns)
沿着Brewer的猜测,如果BASE在分区数据库中选择保留可用性(Availability), 那么,弱化一定程度的一致性就成为必然的选择.这通常难以决策,因为商业投资方与开发人员都倾向于认为一致性(Consistency)对应用的成功至关重要.哪怕是临时的不一致也瞒不过最终用户,因此,技术部门与产品部门都需要参与进来,以决定将一致性弱化到什么程度.
图-2是一个简单的概要,它阐释了BASE中一致性要考虑的事情.用户表存储用户信息,同时还包含总销售额与总购买额.这些都是运行时的统计.交易表存储每一笔交易,将买家、卖家以及交易金额关联在一起.这些是对实际使用的表进行过度简化后的结果,不过,它已经包含阐释一致性的多个方面的必要元素.

图 2
一般来说,功能组之间的一致性要比功能组内部的一致性要更加容易弱化.这个示例概要包含两个功能组:用户与交易.每当售出一个条目(的商品),交易表中就会增加一条记录,买家与卖家的计数器都会被更新.使用ACID风格的事务,SQL语句可能如图-3所示.

图 3
用户表中的总销售额的列与总购买额的列可以被认为是交易表的一份缓存(Cache).它的存在是为了提高系统的效率.有鉴于此,一致性的约束可以被弱化. 可以调整一下买家与卖家的期望设置,从而他们的运行结余(running balance)不能立即反映交易的结果.这种情况很常见,实际上,人们经常会遇到交易与运行结余之间的这种延迟(例如,ATM取款或者手机通话).
如何修改SQL语句来弱化一致性要取决于如何定义运行结余,如果它们只是简单的估计,也就是部分交易可以被错过不统计,SQL的修改非常简单,如图-4所示.

图 4
现在,我们已经将对用户表与交易表的更新做了解耦.两个表之间的一致性将再也无法保证.实际上,在第一个事务与第二个事务处理间隔发生故障,将导致用户表持久处于不一致的状态,不过,如果合同约定运行时汇总(running total)是估计值的话,这样做也足够了.
如果无法接受估计值,该怎么办呢?如何继续对用户表与交易表的更新进行解耦呢?引入一个持久消息队列来解决此问题. 有多种选择可以实现持久消息.然而,实现此消息队列的最关键的因素是,确保队列的持久化支持与数据库使用同样的资源.要实现队列在不涉及2PC的情况下按事务提交,这样做很有必要 .现在的SQL操作看上看去有点不同了,如图-5所示.

图 5
这个例子中的语法有点随意,为了阐释概念对其逻辑也做了大量的简化.通过在插入语句的同一个事务中对持久消息进行排队,可以抓取更新用户运行结余所需的信息.这个事务包含在同一个数据库实例中,因此,它不会影响系统的可用性.
一个独立的消息处理组件,会从队列中取出每条消息,并将此信息应用到用户表.这个例子看似解决了所有的问题,但是,还有一个问题没有解决.为了避免排队时发生2PC,消息是持久化在交易的主机上的.如果在涉及到用户主机的事务中从队列中取出消息,我们仍将遇到2PC的情景.
消息处理组件中的2PC的一种解决方案是什么都不做.通过将更新操作解耦到一个独立的后端(back-end)组件,可以保持面向客户的组件的可用性.业务需要或许可以接受较低的消息处理器的可用性.
不过,假定你的系统完全无法接受2PC.这个问题该如何解决呢?首先,你需要理解等幂概念.如果一个操作被应用一次或多次都能取得同样的结果,就被认为是等幂的.等幂操作非常有用,因为它们允许局部故障,重复执行它们不会改变系统的最终状态.
从等幂的角度看,所选的这个例子是有问题的.更新操作通常不等幂.这个例子中有累加账户列的操作.重复应用此操作显然会导致错误的账户余额.然而, 即使是仅仅设定一个值的更新操作也不是等幂的,因为它还涉及到操作执行的顺序.如果系统无法保证更新操作按照接收到的顺序被应用,系统的最终状态也将是不正确的.后面的内容会进一步讨论此问题.
在账户更新的例子中,你需要一种方式来跟踪哪些更新已经应用成功,哪些更新仍然未解决.一种技术是,使用一个表来记录已经应用的那些交易的唯一识别号.
图-6中展示的表会记录交易ID、更新了哪个帐号以及应用此帐号的用户ID.现在,我们的样本伪代码如图-7所示.

图 6

图 7
这个例子取决于可以窥视队列中的一条消息,并在成功处理后立即删除此消息.如有必要,可以通过两个独立的事务来处理它:消息队列上一个事务,用户数据库上一个事务.数据库操作成功提交,才提交队列操作.目前的算法可以支持局部故障,而且又能提供不依赖于2PC的事务保证.
如果只是关注更新的顺序的话,还有一个更加简单的技术可以确保等幂更新.我们来稍微调整一下我们的示例概要,来阐释面临的挑战以及相应的解决方案(见图-8).
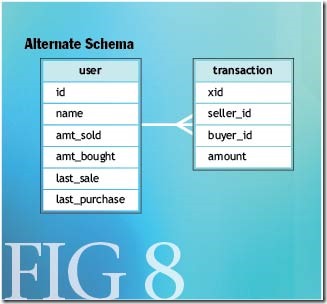
图 8
假设两笔购买交易在一个很短的时间窗口内发生,我们的消息系统无法确保顺序操作.您现在面临的情况是,取决于消息被处理的顺序,last_purchase可能出现一个不正确的值.幸运的是,可以通过对SQL语句做点简单调整来解决此类更新问题, 如图-9所描述.
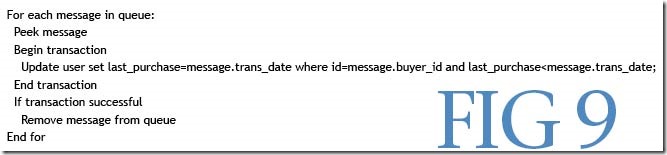
图 9
仅仅通过不允许last_purchase时间做逆向调整,就可以做到更新操作顺序不相关.也可以通过这种方法来保护任何更新免遭无序更新(out-of-order update).你还可以尝试使用单调递增的事务ID来取代时间.
消息队列的顺序
关于顺序消息投递,下面这个简短地附属说明可能有用.消息系统可以提供确保消息发送的顺序与接收的顺序一致的能力.不过,支持此功能可能非常昂贵,通常也没有必要,实际上,有时它也只是给出了一种虚假的安全感.
这里提供的例子阐释了如何弱化消息的顺序,并在最终仍然能够提供一个数据库的一致性视图.弱化消息排序所需的开销是名义上的,在大部分情况下,此开销要显著的少于在消息系统中确保消息顺序的开销.
进一步讲,无论互动风格如何,Web应用在语义上都是一个事件驱动的系统.客户端请求以任意顺序达到系统.每个请求所需的处理时间要求也各不相同. 整个系统的不同组件的请求调度也是不确定的,导致了消息排队的不确定.要求保持消息的顺序给出的是一种虚假的安全感.简单的事实是,不确定的输入会导致不确定的输出.
弱状态/最终一致性(Soft State/Eventually Consistent)
到此为止,重点一直是为了可用性而权衡牺牲部分一致性.硬币的另外一面是,理解软状态与最终一致性对应用设计有何影响.
由于软件工程师倾向于认为系统是闭环(closed loop)的.从预见投入产生预见的产出方面讲,我们可以这样考虑他们行为的可预测性.这对于创建正确的软件系统非常必要.好的消息是,在大部分情况下使用BASE不会改变一个闭环系统的可预测性,不过,它确实需要从整体上来进行审视.
一个简单的例子就可以帮助解释这一点.考虑这样一个系统,用户可以在此将资产转移给另一个用户.哪种类型的资产都没有关系,它可以是钱或者游戏中的装备.对于这个例子,我们假设,已经通过使用一个用于解耦的消息队列,对如下两个操作进行了解耦:从一个用户取出资产,将资产给另一个用户.
很快,系统就会感觉到有问题与不确定性.在资产离开一个用户到达另一个用户中间,有一段时间的延时. 这个时间窗口的大小由消息系统的设计所决定.无论如何,在开始状态与结束状态之间,始终会有一个时间间隔,在这段时间内, 看似任何用户都不享有这笔资产.
不过,如果我们从用户的视角来考虑这个问题,这个时间间隔可能就是无所谓的或者根本就不存在.无论是接收的用户还是发出的用户可能都不知道资产将在何时到达.如果在发送与接收之间的时间间隔是几秒钟,对于具体沟通资产转移的用户来讲,它将是隐蔽的或确实可以忍受的.在这种状况下,这种系统行为对用户来讲,就是一致并可接受的,即使,我们在实现中依赖了软状态以及最终一致性.
事件驱动架构(Event-Driven Architecture)
如果你确实需要知道,系统将在何时达到一致的状态?你可能需要一种算法,来应用到这个状态上,不过,仅仅在它达到一个与后续请求相关的一致状态时才会被应用.
继续讨论前面的例子,如果在资产到达时,需要通知用户,怎么办? 在将资产交付给接收用户的那个事务内创建一个事件,就可以提供一种机制,当达到一个事先确定的状态时,可以做进一步的处理.EDA(事件驱动架构,Event-Driven Architecture)可以显著改善可伸缩性以及架构的解耦.对于EDA应用的进一步讨论超出了本文的范畴.
结论
显著的扩展系统的交易率,需要以一种全新的方式来考虑如何对资源进行管理.当负载需要分布到大量的组件上时,传统的事务模型会漏洞百出.对操作进行解耦,并依次对它们进行处理,可能提供更好的可用性与伸缩性,不过是以牺牲一致性为代价.BASE提供了一种模型来考虑这种解耦.
参考
- http://highscalability.com/unorthodox-approach-database-design-coming-shard.
- http://citeseer.ist.psu.edu/544596.html.
Dan Pritchett是Ebay的一位技术人员,他过去4年一直是Ebay架构团队的成员.在此岗位上,他与Ebay市场部、Paypal以及Skype的战略、商业、产品与技术团队进行合作.他已经有20年技术公司的工作经历,他服务过的公司包含Sun,HP以及硅谷图形公司(Silicon Graphics),Pritchett具有丰富的技术经历,从网络层协议与操作系统到系统设计与软件模式.他拥有密苏里州Rolla大学的计算机科学学士学位.