linux zip删除指定文件和追加文件
使用zip命令的-d参数即可删除zip包中的特定文件。 示例:假设有test.zip,包含_code(目录)、_code.zip、readme.txt三个文件,现在要删除test.zip中的_code目录,则执行如下命令 zip -d test.zip _code zip -m myfile.zip ./rpm_info.txt 向压缩文件中myfile.zip中添加rpm_info.txt文件 from:https://www.cnblogs.com/jifeng/p/7839248.html
View Detailslinux命令:返回上一次目录
返回上一次目录 有时候千辛万苦进入了一个很深层的目录,一不小心输入了cd并回车,有什么办法快速回到刚才所在的目录呢?对于bash来说,只需要很管理的一个命令: cd – 该命令等同于cd $OLDPWD,关于这一点在bash的手册页(可使用命令man bash访问其手册页)中有介绍:
|
1 |
An argument of - is equivalent to $OLDPWD. |
并且它还会返回上一次目录的物理路径。 from:https://www.cnblogs.com/yixius/articles/6971080.html
View Details解决ssh_exchange_identification:read connection reset by peer 原因
服务器改了密码,试过密码多次后出现:
|
1 |
ssh_exchange_identification: read: Connection reset by peer |
可以通过ssh -v查看连接时详情
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
OpenSSH_6.6.1, OpenSSL 1.0.1k-fips 8 Jan 2015 debug1: Reading configuration data /etc/ssh/ssh_config debug1: /etc/ssh/ssh_config line 56: Applying options for * debug1: Connecting to xxx [xx] port 22. debug1: Connection established. debug1: identity file /home/yanue/.ssh/id_rsa type -1 debug1: identity file /home/yanue/.ssh/id_rsa-cert type -1 debug1: identity file /home/yanue/.ssh/id_dsa type -1 debug1: identity file /home/yanue/.ssh/id_dsa-cert type -1 debug1: identity file /home/yanue/.ssh/id_ecdsa type -1 debug1: identity file /home/yanue/.ssh/id_ecdsa-cert type -1 debug1: identity file /home/yanue/.ssh/id_ed25519 type -1 debug1: identity file /home/yanue/.ssh/id_ed25519-cert type -1 ........ |
最后找打解决方法:
|
1 |
vi /etc/hosts.allow |
追加:
|
1 |
sshd: ALL |
重启ssh就ok了
|
1 |
service sshd restart |
from:https://www.cnblogs.com/taoquns/p/9590960.html
View Detailsnginx 升级时 [emerg] module "/usr/lib64/nginx/modules/ngx_http_geoip_module.so" version 1010003 instead of 1016000 in /usr/share/nginx/modules/mod-http-geoip.conf:1
nginx -V
|
1 2 |
[root@VM_0_15_centos ~]# nginx -V nginx version: nginx/1.10.2 |
检查/换源
|
1 2 3 4 5 6 7 |
[root@VM_0_15_centos ~]# cd /etc/yum.repos.d/ [root@VM_0_15_centos yum.repos.d]# vim nginx.repo [nginx] name=nginx repo baseurl=http://nginx.org/packages/centos/$releasever/$basearch/ gpgcheck=0 enabled=1 |
升级
|
1 |
[root@VM_0_15_centos yum.repos.d]# yum update nginx |
[root@VM_0_15_centos ~]# nginx -V nginx version: nginx/1.16.0 检查时报错
|
1 2 3 |
[root@VM_0_15_centos yum.repos.d]# nginx -t nginx: [emerg] module "/usr/lib64/nginx/modules/ngx_http_geoip_module.so" version 1010003 instead of 1016000 in /usr/share/nginx/modules/mod-http-geoip.conf:1 nginx: configuration file /etc/nginx/nginx.conf test failed |
解决问题
|
1 2 |
<strong>yum remove nginx-mod* ### 卸载旧模块 </strong> |
|
1 |
<strong>yum install nginx-module-* ### 安装新的</strong> |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
[root@VM_0_15_centos yum.repos.d]# rpm -qa|grep nginx nginx-mod-http-perl-1.10.3-1.el6.x86_64 nginx-mod-mail-1.10.3-1.el6.x86_64 nginx-1.16.0-1.el6.ngx.x86_64 nginx-filesystem-1.10.3-1.el6.noarch nginx-mod-stream-1.10.3-1.el6.x86_64 nginx-mod-http-xslt-filter-1.10.3-1.el6.x86_64 nginx-mod-http-geoip-1.10.3-1.el6.x86_64 nginx-mod-http-image-filter-1.10.3-1.el6.x86_64 [root@VM_0_15_centos yum.repos.d]#<strong> yum remove nginx-mod*</strong> [root@VM_0_15_centos yum.repos.d]#<strong> yum install nginx-module-*</strong> [root@VM_0_15_centos yum.repos.d]# nginx -t nginx: the configuration file /etc/nginx/nginx.conf syntax is ok nginx: configuration file /etc/nginx/nginx.conf test is successful [root@VM_0_15_centos yum.repos.d]# nginx -s reload ###直接平滑重启不可以 |
from:https://www.cnblogs.com/mingetty/p/11125391.html
View Details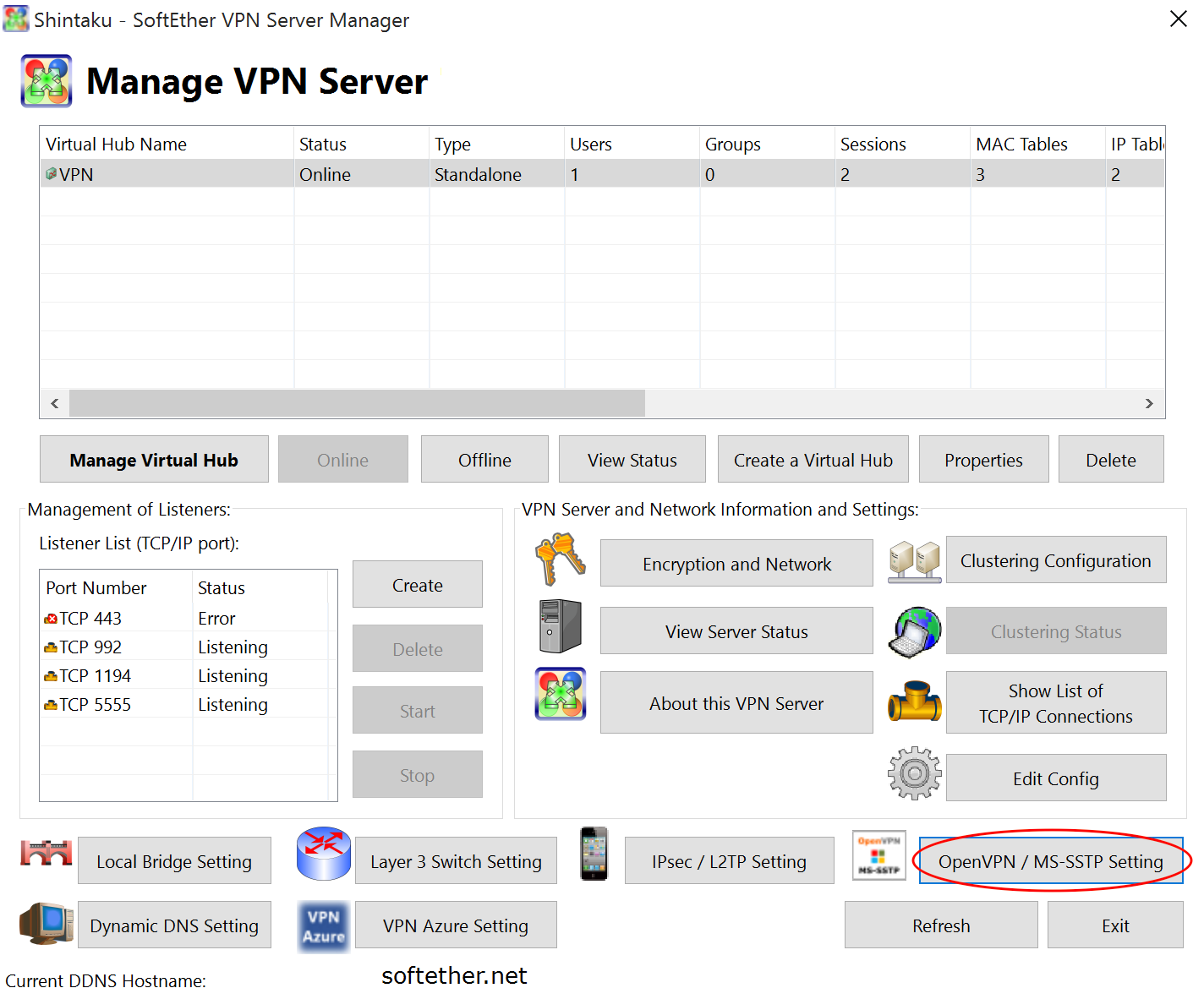
服务器架设:安装SoftEtherVPN Server For Linux
SoftEtherVPN是由日本筑波大学(University of Tsukuba)的登 大遊 (Daiyu Nobori)在硕士论文中提出的开源、跨平台、多重协议的虚拟专用网方案。 本文以64位CentOS 7安装环境为例,讲解如何安装SoftEtherVPN Server For Linux。 第一部分:安装SoftEtherVPN Server 安装编译环境
|
1 |
yum -y install gcc |
从SoftEther下载中心下载SoftEtherVPN Server For Linux
|
1 |
wget http://www.softether-download.com/files/softether/v4.30-9696-beta-2019.07.08-tree/Linux/SoftEther_VPN_Server/64bit_-_Intel_x64_or_AMD64/softether-vpnserver-v4.30-9696-beta-2019.07.08-linux-x64-64bit.tar.gz |
或者从GitHub下载SoftEtherVPN Server For Linux
|
1 |
wget https://github.com/SoftEtherVPN/SoftEtherVPN_Stable/releases/download/v4.30-9696-beta/softether-vpnserver-v4.30-9696-beta-2019.07.08-linux-x64-64bit.tar.gz |
解压文件
|
1 |
tar -zxvf softether-vpnserver-*.tar.gz |
进入到解压目录
|
1 |
cd vpnserver |
启动安装脚本
|
1 |
./.install.sh |
阅读License,根据提示,输入“1”然后回车确认。 如果提示不识别某些命令比如gcc,另行安装即可。如果没有异常则说明安装成功。 启动服务
|
1 |
./vpnserver start |
(停止服务命令为:./vpnserver stop) 在CentOS 7系统中可以用systemd启动vpnserver,先新建启动脚本/etc/systemd/system/vpnserver.service:
|
1 2 3 4 5 6 7 8 9 10 11 |
[Unit] Description=SoftEther VPN Server After=network.target [Service] Type=forking ExecStart=/root/vpnserver/vpnserver start ExecStop=/root/vpnserver/vpnserver stop [Install] WantedBy=multi-user.target |
然后就可以通过systemctl start vpnserver启动了,并通过systemctl enable vpnserver设置开机自启。 启动成功后我们需要设置远程登录密码以便本地管理服务。运行下面的命令进入VPN的命令行:
|
1 |
./vpncmd |
选择1. Management of VPN Server or VPN Bridge 这里需要选择地址和端口。默认443端口,如果需要修改,可以输入localhost:5555(实际端口),然后出现:
|
1 2 3 |
If connecting to the server by Virtual Hub Admin Mode, please input the Virtual Hub name. If connecting by server admin mode, please press Enter without inputting anything. Specify Virtual Hub Name: |
这里就是指定一个虚拟HUB名字,用默认的直接回车就行。
|
1 2 3 4 5 |
Connection has been established with VPN Server "localhost" (port 5555). You have administrator privileges for the entire VPN Server. VPN Server> |
这时我们需要输入ServerPasswordSet命令设置远程管理密码,确认密码后就可以通过Windows版的SoftEther VPN Server Manager远程管理了。 第二部分:VPN管理 首先下载并安装SoftEther VPN Server Manager,安装之后运行它: 在这里点新建: Host Name填服务器的地址或域名,端口如果之前改过了在这也记得改过来,右下角的密码填之前设置过的密码。新建完成后Connect就会弹出Easy Setup窗口(如果提示连不上请检查一下服务器的防火墙设置): 这里在第一个远程连接挑钩然后下一步即可,虚拟HUB名像之前一样默认就好。 然后会弹出一个动态DNS功能的窗口,由于不能确定它给的域名是不是被墙了,我们就不去用它,把这个窗口关了就行了。 之后会有一个协议设置的窗口: 这里把启用L2TP挑上钩,下面设置一个IPsec预共享密钥就行了。 之后又会弹出一个VPN Azure Cloud服务的窗口,感觉没什么用,禁用了就行了。即使有用以后也可以再启用。 接下来要新建用户: 其中用户名是必填的,验证类型选密码验证就行,然后在右侧设置用户密码。 之后回到管理界面,点管理虚拟HUB: 点虚拟NAT和虚拟DHCP服务器,弹出窗口: 在里面启用SecureNAT并点SecureNAT配置: 注意DNS要改为8.8.8.8和8.8.4.4。这里就算配置完毕。然后顺便生成一下OpenVPN的配置文件,点OpenVPN / MS-SSTP Setting: […]
View DetailsPPTP/L2TP内外网VPN映射端口及协议
|
1 2 3 4 5 6 7 8 9 |
PPTP需开放端口: UDP:1723 L2TP需开放端口: UDP:500 UDP:4500 UDP:1701 注意:端口映射时应该将协议设置为UDP,否则无法生效 |
from:https://www.bokezhu.com/2018/10/18/377.html
View Details使用.gitignore忽略文件或者文件夹及其失效解决方法
git如果需要忽略某个文件夹,可以在初始化之后,在仓库根目录下创建一个.gitignore文件,添加需要忽略的文件和文件夹即可。 我们也不需要从头写.gitignore文件,GitHub已经为我们准备了各种配置文件,只需要组合一下就可以使用了。所有配置文件可以直接在线浏览:https://github.com/github/gitignore 例如排除Windows自动生成的垃圾文件和仓库的APP1子文件夹:
|
1 2 3 4 5 6 |
# Windows: Thumbs.db ehthumbs.db Desktop.ini #Directories APP1/ |
如果已经提交过的文件或者文件夹怎么办?此时更改.gitignore文件对已经提交的文件是无效的。 2.1 首先,编辑.gitignore文件。 2.2 然后如果是单个文件,可以使用如下命令从仓库中删除: git rm --cached logs/xx.log 如果是整个目录: git rm --cached logs/* 如果文件很多,那么直接 git rm --cached . 如果提示某个文件无法忽略,可以添加-f参数强制忽略。 git rm -f --cached logs/xx.log 2.3 然后 git add . git commit -m "Update .gitignore" 把被忽略的某个文件强制添加回去: git add -f filename ignore规则检查: git check-ignore 一些规则 a# 忽略所有 .a 结尾的文件 !lib.a# 但lib.a 除外 /TODO# 仅仅忽略项目根目录下的 TODO 文件,不包括 subdir/TODO build/# 忽略build/ 目录下的所有文件 doc/.txt# 会忽略 doc/notes.txt 但不包括 doc/server/arch.txt 参考文献: Git忽略特殊文件 – 廖雪峰的官方网站 git如何忽略已经提交的文件 (.gitignore文件无效) – 简书 Git 中.gitignore 使用和.gitignore 无效的解决方法 – 简书 from:https://blog.csdn.net/toopoo/article/details/88660806
View Details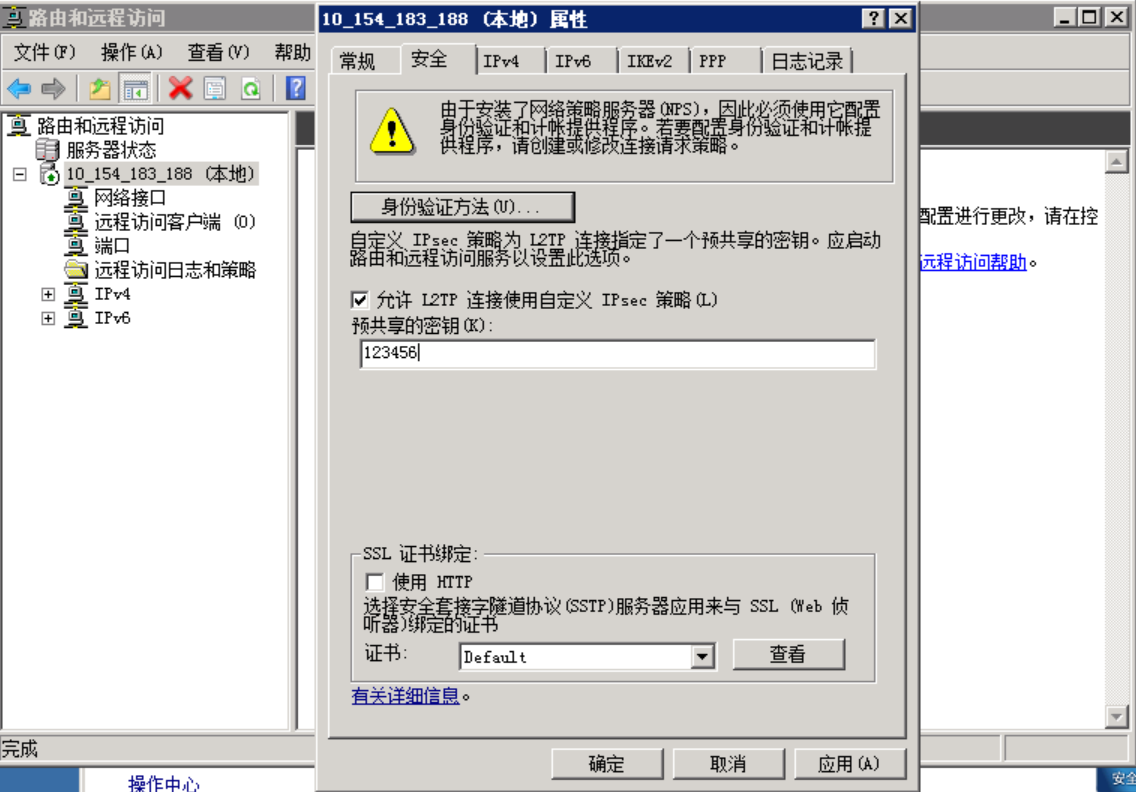
windows 2008 VPN(PPTP/L2TP)搭建
PPTP和L2TP只差一步配置,现在苹果已经不支持PPTP,所以只能使用L2TP连接。废话不多说,下面开始搭建: 1、PPTP VPN 配置 新安装好的OS,进入系统,首先添加角色 勾选添加网络策略和访问服务 如图勾选需要的角色服务 安装完成后,依次点击开始-管理工具-路由与远程访问工具 如图在服务器上右键,选择“配置并启动路由和远程访问服务” 因为是单网卡机器,所以选择自定义配置 选择VPN访问和NAT。 向导安装完成之后,配置添加VPN连接客户机所用的地址池。 此处也可以配置dhcp动态池,此处省略了,测试过也是可以的。 然后按照下图开启NAT访问,否则VPN无法上网 右键,新增接口 至此,RRAS的配置已经完成了,接下来进入NPS配置。 客户端的设置 此处填写VPN服务器的外网ip 至此,win08 pptp VPN的搭建配置已经成功,此时客户机可以通过vpn连接到腾讯云的服务器,并且可以通过VPN服务器连接上internet。 2:L2TP 服务器搭建 按照下图操作,打开路由与远程访问,找到服务器右键属性——安全——允许L2TP连接使用自定义IPSEC策略,然后配置密钥,确定之后重启一下服务即可,在客户端连接的时候输入将配置的密钥输入进去就可以正常连接啦 2020/02/23 如果配完不能用,请把【路由与远程访问】部署禁用再配一下遍。 from:https://www.wyxxw.cn/blog-detail-22-24-494
View Details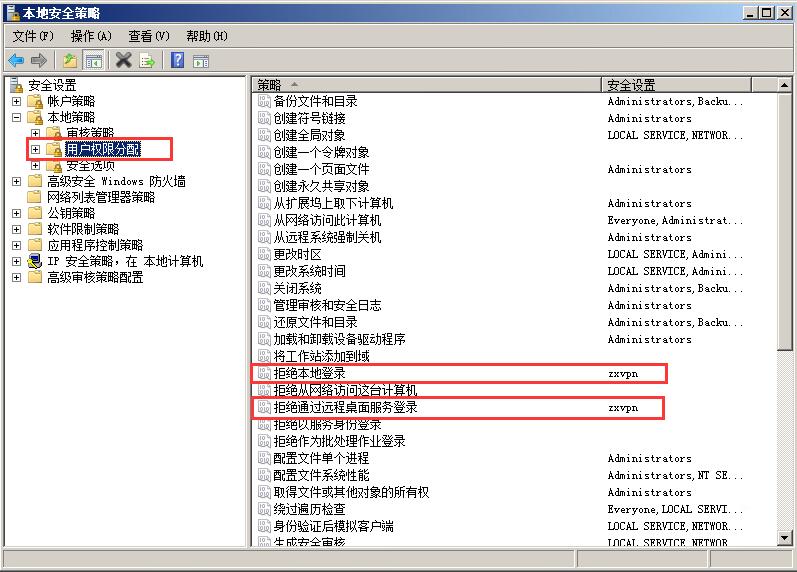
Windows Server 2008 R2 单网卡搭建VPN最详细图解
如何用Windows Server 2008 R2 单网卡搭建VPN? 今天上午做了个详细图解教程,希望对大家有所帮助! 开始! 找一台安装Windows Server 2008 r2的服务器 第一步:安装角色 添加角色 把网络策略和访问服务打上勾号 在角色服务里按图打上勾号,点下一步 点击安装,等待安装完成 点击关闭,完成安装 第二步:配置路由和远程访问 在开始菜单中-->管理工具中找到“路由和远程访问” 如图:右键选择“配置并启用路由和远程访问” 选择自定义配置 全部打上勾号,并下一步 点“完成” 点“确定”,并等待完成配置 完成好配置如下 右键NAT,选择新增接口 选择“本地连接” 选择公用接口到专用网络 按图示操作 按图中步骤,添加的IP地址数,按您的实际要求填写 第三步:配置网络策略服务 按图中找到“网络策略服务器” 网络策略中的红叉的行,右键选择属性,再选择授予访问权限,并点击确定。 第四步:添加VPN账号密码 打开“服务器管理器” 按图示添加VPN的账号密码 第五步:本地安全策略的设置 本步骤是为服务器安全,以网址随便登录桌面和远程桌面。 打开“本地安全策略和组” 按图示步骤一步一步操作,一共是两项,拒绝本地登录和拒绝通过远程桌面服务登录。 完成后如图示 这样整合VPN的安装配置就完成了,快去找一台电脑测试下吧! from:http://www.min68.com/archives/WinddowsServer2008r2danwangkavpndajian.html
View Detailswin2008架设vpn 新建用户指定IP地址的方法
008架设vpn服务器完毕,新建账户,分配了静态IP地址, 但是客户端拨号后获取了另一个IP 怎么才能给客户端指定IP,这里就为大家分享一下 自己解决了,具体如下 1、开启NPS, 2、创建并配置策略 (备注:本人新建账户均归属guests,故选择用户组添加“GUESTS”) 主要就是下面红框框一定要勾上 操作完毕,解决 from:https://www.jb51.net/article/103056.htm
View Details