linux下移植wifi之安装iw and iw操作(五)
第四节 安装iw and iw操作 一、 先查看README,获取了三个有用点: 1. This is 'iw', a tool to use nl80211(iw需要nl80211) 2. To build iw, just enter 'make'. If that fails, set the PKG_CONFIG_PATH environment variable to allow the Makefile to find libnl.(通过这个参数来指定libnl库的位置) 3. 'iw' is currently maintained at http://git.sipsolutions.net/iw.git/,(iw软件下载网站) 4. some more documentation is available at http://wireless.kernel.org/en/users/Documentation/iw. (iw 操作说明文档) 解压:tar -xf /mnt/hgfs/linux_share/0711/iw-4.9.tar.xz nl80211已经安装了,通过PKG_CONFIG_PATH变量,我们已经指定了nl80211头文件和库的路径,可以通过命令进行查看。 命令:echo $PKG_CONFIG_PATH 得:/home/clh/work/libnl-3.2.25/tmp/lib/pkgconfig: 二、编译 在info.c的代码前面添加 #define htole16(X) (((((uint16_t)(X)) << 8) | ((uint16_t)(X) >> 8)) & 0xffff) 修改Makefile ,加上libnl的头文件 和 lib库。 CFLAGS += -I/home/clh/work/libnl-3.2.25/tmp/include/libnl3 LDFLAGS += -L/home/clh/work/libnl-3.2.25/tmp/lib make CC=arm-linux-gcc make DESTDIR=$PWD/tmp […]
View Details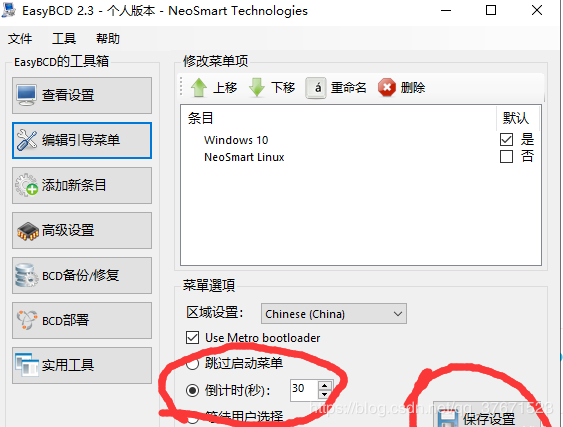
centos7 与windows10之间的开机引导
一、centos7下引导windows10 当在win10系统下安装centos7系统后进入centos系统需要引导windows10开机启动项。 1、打开terminal,输入命令vi /boot/grub2/grub2.cfg 编辑开机引导文件。 2、在 70 行左右的 ### END /etc/grub.d/00 header 和 ### BEGIN /etc/grub.d/10_linux ### 间添加 menuentry ‘Windows10’{ set root = (hd0,1) chainloader +1 } 表示 Windows7 的引导设备为第 1块磁盘的第 1 个分区,根据实际情况填,如果不知道输入命令lsblk查看,或者试几次,如果不正确的话开机选择win10后会报错。 4、重启reboot,即可看到开机引导项。 二、windows10下引导linux 当在centos7系统下安装win10系统后进入win10系统需要引导centos开机启动项。 1、下载并安装EasyBCD开机引导软件,软件很小,功能很强大。如果懒得 百度下,附上百度云下载链接https://pan.baidu.com/s/1-yF3s1fmumnE06_NV2rUYg 2、打开easybcd,点击添加新条目,选择linux,类型选择GRUN2,名称随便写,就是你开机引导显示的名称,然后点击驱动器选择你linux安装的分区,如果不知道,方法同上可以多试几次,点击添加条目,即可添加成功。 centos7 与windows10之间的开机引导 3、最重要的一点,添加成功后点击编辑引导菜单选择倒计时那一项然后点击保存设置,时间自己定,我上次就是没看自动选择的跳过菜单而导致重启n次也显示不出启动项。 from:https://blog.csdn.net/qq_37671523/article/details/102161216
View Details获取指定的历史版本代码
首先 ,把项目 clone 到其他文件夹下
|
1 |
git clone git@github.com:skyming/BMAdScrollView.git |
然后查看指定历史版本 tree 的 SHA checkout 即可,哎,程序员,需要什么学什么。。。
|
1 |
git checkout b0362a895d39061c0bc6f05c575af47de1b3f702 |
然后就顺利切到指定的分支版本了。。。 from:https://www.cnblogs.com/jiu0821/p/9270145.html
View Details修改文件,查看修改内容,git status、git diff(四)
在第三篇时,我们已经成功地添加并提交了一个index.html文件,现在我们继续修改index.html文件,改成如下内容: 现在,运行命令 git status 查看结果: git status命令可以让我们时刻掌握仓库当前的状态, 上面的命令 modified:index.html,输出告诉我们,index.html被修改过了, 需要重新添加文件,(git add命令); 虽然Git 告诉我们index.html被修改了,如果要查看具体修改了什么内容,怎么办呢? 如果休假回来,已经记不清上次怎么修改index.html的内容,这时,可以使用命令git diff 来查看: git diff 命令表示查看difference;显示的格式正是Unix通用的diff格式。 可以从上面的命令输出中看到,两行红色字体的内容是修改前的旧内容,而两行绿色字体的内容为修改后的新内容; 现在知道了对index.html作了什么修改后,再把它提交到仓库。提交修改和提交新文件是同样的步骤和操作; 第一步:执行 git add 命令 ;之后再执行 git status命令,看看仓库当前的状态; git status命令可知:可以提交的文件包括index.html,下一步:执行 git commit 命令; 提交之后,再使用 git status 命令 查看仓库当前状态:nothing to commit,working tree clean 表示当前没有需要提交,工作目录是干净的; 小结: git status 命令 表示 查看仓库当前状态; git diff 命令 表示 查看修改内容; 转载来自:https://www.liaoxuefeng.com/wiki/0013739516305929606dd18361248578c67b8067c8c017b000 from:https://blog.csdn.net/qq_40415721/article/details/82145156
View Details推荐.Net、C# 逆向反编译四大工具利器
转自:https://blog.csdn.net/kongwei521/article/details/54927689 在项目开发过程中,估计也有人和我遇到过同样的经历:运行环境出现了重大Bug亟需解决、或者由于电脑挂了、旧代码覆盖新代码,而在这种情况下,我们不能直接在当前的代码中修改这个Bug然后发布,这会导致更严重的问题,因为相当于版本回退了。还有电脑挂了代码整个都没有,这种情况下 我们只能只能利用一些逆向的技巧和工具了 来解析在服务器发布好的dll。那么你只是单纯的修改一个.Net程序集中的某个方法或功能,而且这个程序集还是出自于你自己或你所在团队之手,这实在是一件非常容易的事情,这和破解别人的程序完全不同,你不会遇到无法破解的加密算法,也不会遇到让人恶心的加壳混淆。所以我要把用过的工具一个个的列出来总结一下。 推荐四大发编译工具 1:.Net Reflector 【收费】 一提起.Net逆向,其实很多人第一反应都是Reflector这款神器,这一方面是由于Reflector良好的用户体验和强大的插件功能,另一方面要归功于Reflector堪称完美的智能反编译能力,使用它不仅能看到反编译后的IL源码甚至能直接反编译出C#源码,而且和编写时的代码几无二致,如果需要还可以直接另存为工程文件用Visual Studio打开,不过现在已经收费了,所以老司机都选择破解版,有钱人选择正版。 破解地址就不在这里放出,大家自行搜索. 使用方法:可以直接把dll、exe拖放到左侧,或者文件选择选择 官方网址:http://www.red-gate.com/products/dotnet-development/reflector/ 2:ILSpy/dnSpy 【免费】 ILSpy是唯一免费且开源的.NET反编译器,它基于MIT许可证发布。ILSpy的代码生成和语法高亮功能做的非常好。对于反编译的程序集,它既可以将其保存在一个文件中,也可以为所有文件创建一个项目。ILSpy是一个独立的工具,没有Visual Studio集成。,ILSpy 是为了完全替代收费的Reflector而生,它是由 iCSharpCode 团队出品,这个团队开发了著名的 SharpDevelop 。ILSpy 完全开源,ILSpy的使用和上面的Reflector完全类似,可以直接把dll、exe拖放到左侧,或者文件选择选择。 官方网址:http://ilspy.net/ ILSPY还有一款同门师弟,感觉比ILSPY还强大 dnSpy is a .NET assembly editor, decompiler, and debugger forked from ILSpy * Assembly editor * Decompiler * Debugger * Tabs and tab groups * Themes (blue, dark, light and high contrast) If you want to help, fork the project and send pull requests. Latest release: https://github.com/0xd4d/dnSpy/releases Latest build: https://ci.appveyor.com/project/0xd4d/dnspy/build/artifacts 3:JetBrains dotPeek【免费】 JetBrains是捷克的一家软件开发公司,出品了大量著名的开发工具,包括:IntelliJ IDEA、PHPStorm、ReSharper、TeamCity、YouTrack等等,每一款产品都如雷贯耳。dotPeek 是 JetBrains 开发的一款.Net反编译工具,是.Net工具套件中的一个相比于前面几款工具来说,dotPeek算比较小众的一款,它生成的代码质量很高,它还会尝试到源代码服务器上抓取代码。DotPeek的导航功能和快捷键非常便捷。它还能精确查找符号的使用,同时支持插件。DotPeek不能与Visual Studio集成。个人感觉它最大的特色就是Visual Studio风格,这对于那些长期在Visual Studio下进行开发的人来说应该更亲切一点。 官方网址:http://www.jetbrains.com/decompiler/ 4:Telerik JustDecompile 【需要输入信息安装】不喜欢这个就卸载了 Telerik JustDecompile是一个免费的.NET反编译器,但是有商业化支持。它生成的代码质量也很高。它可以为反编译程序集得到的代码创建一个项目。JustDecompile提供了健壮的查找功能,能够支持全文查找和符号使用查找。它还有一个插件系统,目前在Telerik的网站上有两个可用的扩展。JustDecompile不能与Visual Studio集成。 […]
View DetailsLinux下查看CPU型号,内存大小,硬盘空间的命令(详解)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 |
# dmidecode |grep -A16 "Memory Device$" Memory Device Array Handle: 0x1000 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: 2048 MB //1条2G内存 Form Factor: DIMM Set: 1 Locator: DIMM1 Bank Locator: Not Specified Type: DDR2 Type Detail: Synchronous Speed: 667 MHz Manufacturer: 7F7F7F7F7F510000 Serial Number: 0403E324 Asset Tag: 450721 Part Number: 72T256220HR3SA -- Memory Device Array Handle: 0x1000 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: 2048 MB //1条2G内存 Form Factor: DIMM Set: 1 Locator: DIMM2 Bank Locator: Not Specified Type: DDR2 Type Detail: Synchronous Speed: 667 MHz Manufacturer: 7F7F7F7F7F510000 Serial Number: 0403E324 Asset Tag: 450721 Part Number: 72T256220HR3SA -- Memory Device Array Handle: 0x1000 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: No Module Installed //1个内存空槽 Form Factor: DIMM Set: 2 Locator: DIMM3 Bank Locator: Not Specified Type: DDR2 Type Detail: Synchronous Speed: Unknown Manufacturer: Serial Number: Asset Tag: Part Number: -- Memory Device Array Handle: 0x1000 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: No Module Installed //1个内存空槽 Form Factor: DIMM Set: 2 Locator: DIMM4 Bank Locator: Not Specified Type: DDR2 Type Detail: Synchronous Speed: Unknown Manufacturer: Serial Number: Asset Tag: Part Number: -- Memory Device Array Handle: 0x1000 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: No Module Installed //1个内存空槽 Form Factor: DIMM Set: 3 Locator: DIMM5 Bank Locator: Not Specified Type: DDR2 Type Detail: Synchronous Speed: Unknown Manufacturer: Serial Number: Asset Tag: Part Number: -- Memory Device Array Handle: 0x1000 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: No Module Installed //1个内存空槽 Form Factor: DIMM Set: 3 Locator: DIMM6 Bank Locator: Not Specified Type: DDR2 Type Detail: Synchronous Speed: Unknown Manufacturer: Serial Number: Asset Tag: Part Number: |
感谢有奉献精神的人 转自:https://blog.csdn.net/zhangliao613/article/details/79021606 转自:http://www.jb51.net/article/97157.htm 1 查看CPU 1.1 查看CPU个数 # cat /proc/cpuinfo | grep "physical id" | uniq | wc -l 2 **uniq命令:删除重复行;wc –l命令:统计行数** 1.2 查看CPU核数 # cat /proc/cpuinfo | grep "cpu cores" | uniq cpu cores : 4 1.3 查看CPU型号 # cat /proc/cpuinfo | grep 'model name' |uniq model name : Intel(R) Xeon(R) CPU E5630 @ 2.53GHz 总结:该服务器有2个4核CPU,型号Intel(R) Xeon(R) CPU E5630 @ 2.53GHz 2 查看内存 2.1 查看内存总数 #cat /proc/meminfo | grep MemTotal MemTotal: 32941268 kB //内存32G 下面是一些命令的集合,供参考: uname -a # 查看内核/操作系统/CPU信息的linux系统信息 head -n l /etc/issue # 查看操作系统版本 cat /proc/cpuinfo # 查看CPU信息 hostname # 查看计算机名的linux系统信息命令 lspci -tv # 列出所有PCI设备 lsusb -tv # 列出所有USB设备的linux系统信息命令 lsmod # 列出加载的内核模块 env # 查看环境变量资源 […]
View Detailsgit查看只commit没有push的文件或者提交记录
1 git status 查看有多少次 提交了 没有push到版本库 eg:Your branch is ahead of 'origin/master' by 1 commit. (我这里有一次) 2. 查看已经提交 但是未传送到远程代码库的提交描述/说明 git cherry -v eg: + 27122d40164dbf08276d96960bde20a2059cdb8b 修改页面 3.查看已经提交但是未传送到远程代码库的提交详情(可能不止一次) git log master ^origin/master eg: commit 27122d40164dbf08276d96960bde20a2059cdb8b Author: huyw Date: Mon Oct 8 11:43:19 2018 +0800 修改页面 总结:一定要记住时刻本地和服务器保持一致,一旦出现冲突,生产环境就很麻烦(当然,不怕冲突多的,可以忽略) git status 只能查看未传送代码库提交的次数 git cherry -v只能查看未传送代码库提交的描述/说明(唯一id) git log master ^origin/master则可以查看未传送代码库提交的详细信息 ———————————————— 版权声明:本文为CSDN博主「跨省少年」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/u010089432/article/details/85318995
View Detailswsdl手动生成,生成单文件
|
1 |
wsdl /language:c# /n:JSRMYY /out:c:/WebServiceForAutoOrder.cs http://{url}/hisOrderReal/WebServiceForAutoOrder.asmx?WSDL |
公司一老哥提供的方法,避免生成一大堆文件~ wsdl.exe下载
View Details解决方案:CS0016: 未能写入输出文件“c:\Windows\Microsoft.NET\Framework64\v4.0.30319\--”--“拒绝访问。 ”
IIS部署的网站打开出现问题: CS0016: 未能写入输出文件“c:\Windows\Microsoft.NET\Framework64\v4.0.30319\Temporary ASP.NET Files\root\6ba3b83b\52fcdeee\App_global.asax.7ky3gsdp.dll”--“拒绝访问。 ” 将windows/temp属性-安全-高级 添加IIS_USERS用户,同时编辑权限为完全控制(写入和编辑)保存即可 from:https://www.cnblogs.com/yinrq/p/4712948.html
View Detailsgit查看远程地址,更新代码,提交代码,切换分支命令总结
一.简述 git项目管理,包含克隆项目,上传代码,拉去代码,分支管理。 二.命令行 查看远程git地址:git remote -v 拉去远程所有分支:git fetch -p 删除远程项目地址:git remote rm origin 添加远程代码仓库:git remote add origin http://jcode.cbpmgt.com/git/epp_saas_m_mht_man.git 更新远程分支列表:git remote update origin --prune 已有git地址情况下,修改新的git地址:git remote set-url origin git@github.com:xuweixiao/vue-pc.git 克隆代码:git clone 项目地址 拉去代码:git pull origin 分支名 更新代码:s 查看文件状态:git status git add . git commit -m “说明” git push 新建本地分支:git branch 分支名. 新建远程分支: git push --set-upstream origin 分支名 删除分支:git branch -d 分支名 删除远程分支: git push origin -d 分支名 查看本地分支:git branch 查看远程分支:git branch -a 切换分支:git checkout 分支名 设置git缓存值大小:git config --global http.postBuffer 5242880000 查看git配置:git config --global http.postBuffer 5242880000 拉去远程的分支:git fetch origin branch1 […]
View Details