Monthly Archives: October 2019
Kafka学习之路 (一)Kafka的简介
目录 一、简介 1.1 概述 1.2 消息系统介绍 1.3 点对点消息传递模式 1.4 发布-订阅消息传递模式 二、Kafka的优点 2.1 解耦 2.2 冗余(副本) 2.3 扩展性 2.4 灵活性&峰值处理能力 2.5 可恢复性 2.6 顺序保证 2.7 缓冲 2.8 异步通信 三、常用Message Queue对比 3.1 RabbitMQ 3.2 Redis 3.3 ZeroMQ 3.4 ActiveMQ 3.5 Kafka/Jafka 四、Kafka中的术语解释 4.1 概述 4.2 broker 4.3 Topic 4.3 Partition 4.4 Producer 4.5 Consumer 4.6 Consumer Group 4.7 Leader 4.8 Follower 正文 回到顶部 一、简介 1.1 概述 Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。 主要应用场景是:日志收集系统和消息系统。 Kafka主要设计目标如下: 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能。 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。 支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。 同时支持离线数据处理和实时数据处理。 Scale out:支持在线水平扩展 1.2 消息系统介绍 一个消息系统负责将数据从一个应用传递到另外一个应用,应用只需关注于数据,无需关注数据在两个或多个应用间是如何传递的。分布式消息传递基于可靠的消息队列,在客户端应用和消息系统之间异步传递消息。有两种主要的消息传递模式:点对点传递模式、发布-订阅模式。大部分的消息系统选用发布-订阅模式。Kafka就是一种发布-订阅模式。 1.3 点对点消息传递模式 在点对点消息系统中,消息持久化到一个队列中。此时,将有一个或多个消费者消费队列中的数据。但是一条消息只能被消费一次。当一个消费者消费了队列中的某条数据之后,该条数据则从消息队列中删除。该模式即使有多个消费者同时消费数据,也能保证数据处理的顺序。这种架构描述示意图如下: 生产者发送一条消息到queue,只有一个消费者能收到。 1.4 发布-订阅消息传递模式 在发布-订阅消息系统中,消息被持久化到一个topic中。与点对点消息系统不同的是,消费者可以订阅一个或多个topic,消费者可以消费该topic中所有的数据,同一条数据可以被多个消费者消费,数据被消费后不会立马删除。在发布-订阅消息系统中,消息的生产者称为发布者,消费者称为订阅者。该模式的示例图如下: 发布者发送到topic的消息,只有订阅了topic的订阅者才会收到消息。 回到顶部 二、Kafka的优点 2.1 解耦 在项目启动之初来预测将来项目会碰到什么需求,是极其困难的。消息系统在处理过程中间插入了一个隐含的、基于数据的接口层,两边的处理过程都要实现这一接口。这允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。 2.2 冗余(副本) 有些情况下,处理数据的过程会失败。除非数据被持久化,否则将造成丢失。消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的"插入-获取-删除"范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。 2.3 扩展性 因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。不需要改变代码、不需要调节参数。扩展就像调大电力按钮一样简单。 2.4 灵活性&峰值处理能力 在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见;如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。 2.5 可恢复性 系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。 2.6 顺序保证 在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。Kafka保证一个Partition内的消息的有序性。 2.7 缓冲 在任何重要的系统中,都会有需要不同的处理时间的元素。例如,加载一张图片比应用过滤器花费更少的时间。消息队列通过一个缓冲层来帮助任务最高效率的执行———写入队列的处理会尽可能的快速。该缓冲有助于控制和优化数据流经过系统的速度。 2.8 异步通信 很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。 回到顶部 三、常用Message Queue对比 3.1 RabbitMQ RabbitMQ是使用Erlang编写的一个开源的消息队列,本身支持很多的协议:AMQP,XMPP, SMTP, STOMP,也正因如此,它非常重量级,更适合于企业级的开发。同时实现了Broker构架,这意味着消息在发送给客户端时先在中心队列排队。对路由,负载均衡或者数据持久化都有很好的支持。 3.2 Redis Redis是一个基于Key-Value对的NoSQL数据库,开发维护很活跃。虽然它是一个Key-Value数据库存储系统,但它本身支持MQ功能,所以完全可以当做一个轻量级的队列服务来使用。对于RabbitMQ和Redis的入队和出队操作,各执行100万次,每10万次记录一次执行时间。测试数据分为128Bytes、512Bytes、1K和10K四个不同大小的数据。实验表明:入队时,当数据比较小时Redis的性能要高于RabbitMQ,而如果数据大小超过了10K,Redis则慢的无法忍受;出队时,无论数据大小,Redis都表现出非常好的性能,而RabbitMQ的出队性能则远低于Redis。 3.3 ZeroMQ ZeroMQ号称最快的消息队列系统,尤其针对大吞吐量的需求场景。ZeroMQ能够实现RabbitMQ不擅长的高级/复杂的队列,但是开发人员需要自己组合多种技术框架,技术上的复杂度是对这MQ能够应用成功的挑战。ZeroMQ具有一个独特的非中间件的模式,你不需要安装和运行一个消息服务器或中间件,因为你的应用程序将扮演这个服务器角色。你只需要简单的引用ZeroMQ程序库,可以使用NuGet安装,然后你就可以愉快的在应用程序之间发送消息了。但是ZeroMQ仅提供非持久性的队列,也就是说如果宕机,数据将会丢失。其中,Twitter的Storm 0.9.0以前的版本中默认使用ZeroMQ作为数据流的传输(Storm从0.9版本开始同时支持ZeroMQ和Netty作为传输模块)。 3.4 ActiveMQ ActiveMQ是Apache下的一个子项目。 […]
View DetailsKafka
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
View Detailsrabbitmq
RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件)。RabbitMQ服务器是用Erlang语言编写的,而集群和故障转移是构建在开放电信平台框架上的。所有主要的编程语言均有与代理接口通讯的客户端库。
View DetailsSolr
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
View DetailsJava Set集合的详解
一,Set Set:注重独一无二的性质,该体系集合可以知道某物是否已近存在于集合中,不会存储重复的元素 用于存储无序(存入和取出的顺序不一定相同)元素,值不能重复。 对象的相等性 引用到堆上同一个对象的两个引用是相等的。如果对两个引用调用hashCode方法,会得到相同的结果,如果对象所属的类没有覆盖Object的hashCode方法的话,hashCode会返回每个对象特有的序号(java是依据对象的内存地址计算出的此序号),所以两个不同的对象的hashCode值是不可能相等的。 如果想要让两个不同的Person对象视为相等的,就必须覆盖Object继下来的hashCode方法和equals方法,因为Object hashCode方法返回的是该对象的内存地址,所以必须重写hashCode方法,才能保证两个不同的对象具有相同的hashCode,同时也需要两个不同对象比较equals方法会返回true 该集合中没有特有的方法,直接继承自Collection。
|
1 2 3 4 5 6 7 8 9 10 11 |
---| Itreable 接口 实现该接口可以使用增强for循环 ---| Collection 描述所有集合共性的接口 ---| List接口 可以有重复元素的集合 ---| ArrayList ---| LinkedList ---| Set接口 不可以有重复元素的集合 |
案例:set集合添加元素并使用迭代器迭代元素。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
public class Demo4 { public static void main(String[] args) { //Set 集合存和取的顺序不一致。 Set hs = new HashSet(); hs.add("世界军事"); hs.add("兵器知识"); hs.add("舰船知识"); hs.add("汉和防务"); System.out.println(hs); // [舰船知识, 世界军事, 兵器知识, 汉和防务] Iterator it = hs.iterator(); while (it.hasNext()) { System.out.println(it.next()); } } } |
二,HashSet
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
---| Itreable 接口 实现该接口可以使用增强for循环 ---| Collection 描述所有集合共性的接口 ---| List接口 可以有重复元素的集合 ---| ArrayList ---| LinkedList ---| Set接口 不可以有重复元素的集合 ---| HashSet 线程不安全,存取速度快。底层是以哈希表实现的。 |
HashSet 哈希表边存放的是哈希值。HashSet存储元素的顺序并不是按照存入时的顺序(和List显然不同) 是按照哈希值来存的所以取数据也是按照哈希值取得。 HashSet不存入重复元素的规则.使用hashcode和equals 由于Set集合是不能存入重复元素的集合。那么HashSet也是具备这一特性的。HashSet如何检查重复?HashSet会通过元素的hashcode()和equals方法进行判断元素师否重复。 当你试图把对象加入HashSet时,HashSet会使用对象的hashCode来判断对象加入的位置。同时也会与其他已经加入的对象的hashCode进行比较,如果没有相等的hashCode,HashSet就会假设对象没有重复出现。 简单一句话,如果对象的hashCode值是不同的,那么HashSet会认为对象是不可能相等的。 因此我们自定义类的时候需要重写hashCode,来确保对象具有相同的hashCode值。 如果元素(对象)的hashCode值相同,是不是就无法存入HashSet中了? 当然不是,会继续使用equals 进行比较.如果 equals为true 那么HashSet认为新加入的对象重复了,所以加入失败。如果equals 为false那么HashSet 认为新加入的对象没有重复.新元素可以存入. 总结: 元素的哈希值是通过元素的hashcode方法 来获取的, HashSet首先判断两个元素的哈希值,如果哈希值一样,接着会比较equals方法 如果 equls结果为true ,HashSet就视为同一个元素。如果equals 为false就不是同一个元素。 哈希值相同equals为false的元素是怎么存储呢,就是在同样的哈希值下顺延(可以认为哈希值相同的元素放在一个哈希桶中)。也就是哈希一样的存一列。 hashtable 图1:hashCode值不相同的情况 图2:hashCode值相同,但equals不相同的情况。 HashSet:通过hashCode值来确定元素在内存中的位置。一个hashCode位置上可以存放多个元素。 当hashcode() 值相同equals() 返回为true 时,hashset 集合认为这两个元素是相同的元素.只存储一个(重复元素无法放入)。调用原理:先判断hashcode 方法的值,如果相同才会去判断equals 如果不相同,是不会调用equals方法的。 HashSet到底是如何判断两个元素重复。 通过hashCode方法和equals方法来保证元素的唯一性,add()返回的是boolean类型 判断两个元素是否相同,先要判断元素的hashCode值是否一致,只有在该值一致的情况下,才会判断equals方法,如果存储在HashSet中的两个对象hashCode方法的值相同equals方法返回的结果是true,那么HashSet认为这两个元素是相同元素,只存储一个(重复元素无法存入)。 注意:HashSet集合在判断元素是否相同先判断hashCode方法,如果相同才会判断equals。如果不相同,是不会调用equals方法的。 HashSet 和ArrayList集合都有判断元素是否相同的方法, boolean contains(Object o) HashSet使用hashCode和equals方法,ArrayList使用了equals方法 案例: 使用HashSet存储字符串,并尝试添加重复字符串 回顾String类的equals()、hashCode()两个方法。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
public class Demo4 { public static void main(String[] args) { // Set 集合存和取的顺序不一致。 Set hs = new HashSet(); hs.add("世界军事"); hs.add("兵器知识"); hs.add("舰船知识"); hs.add("汉和防务"); // 返回此 set 中的元素的数量 System.out.println(hs.size()); // 4 // 如果此 set 尚未包含指定元素,则返回 true boolean add = hs.add("世界军事"); // false System.out.println(add); // 返回此 set 中的元素的数量 System.out.println(hs.size());// 4 Iterator it = hs.iterator(); while (it.hasNext()) { System.out.println(it.next()); } } } |
使用HashSet存储自定义对象,并尝试添加重复对象(对象的重复的判定)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 |
public class Demo4 { public static void main(String[] args) { HashSet hs = new HashSet(); hs.add(new Person("jack", 20)); hs.add(new Person("rose", 20)); hs.add(new Person("hmm", 20)); hs.add(new Person("lilei", 20)); hs.add(new Person("jack", 20)); Iterator it = hs.iterator(); while (it.hasNext()) { Object next = it.next(); System.out.println(next); } } } class Person { private String name; private int age; Person() { } public Person(String name, int age) { this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public int hashCode() { System.out.println("hashCode:" + this.name); return this.name.hashCode() + age * 37; } @Override public boolean equals(Object obj) { System.out.println(this + "---equals---" + obj); if (obj instanceof Person) { Person p = (Person) obj; return this.name.equals(p.name) && this.age == p.age; } else { return false; } } @Override public String toString() { return "Person@name:" + this.name + " age:" + this.age; } } |
问题:现在有一批数据,要求不能重复存储元素,而且要排序。ArrayList 、 LinkedList不能去除重复数据。HashSet可以去除重复,但是是无序。 所以这时候就要使用TreeSet了 三,TreeSet 案例:使用TreeSet集合存储字符串元素,并遍历
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
public class Demo5 { public static void main(String[] args) { TreeSet ts = new TreeSet(); ts.add("ccc"); ts.add("aaa"); ts.add("ddd"); ts.add("bbb"); System.out.println(ts); // [aaa, bbb, ccc, ddd] } } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
---| Itreable 接口 实现该接口可以使用增强for循环 ---| Collection 描述所有集合共性的接口 ---| List接口 有序,可以重复,有角标的集合 ---| ArrayList ---| LinkedList ---| Set接口 无序,不可以重复的集合 ---| HashSet 线程不安全,存取速度快。底层是以hash表实现的。 ---| TreeSet 红-黑树的数据结构,默认对元素进行自然排序(String)。如果在比较的时候两个对象返回值为0,那么元素重复。 |
红–黑树 红黑树是一种特定类型的二叉树 红黑树算法的规则: […]
View DetailsLinkedList、ConcurrentLinkedQueue、LinkedBlockingQueue对比分析
写这篇文章源于我经历过的一次生产事故,在某家公司的时候,有个服务会收集业务系统的日志,此服务的开发人员在给业务系统的sdk中就因为使用了LinkedList,又没有做并发控制,就造成了此服务经常不能正常收集到业务系统的日志(丢日志以及日志上报的线程停止运行)。看一下add()方法的源码,我们就可以知道原因了:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
public boolean add(E e) { linkLast(e);//调用linkLast,在队列尾部添加元素 return true; } void linkLast(E e) { final Node<E> l = last; final Node<E> newNode = new Node<>(l, e, null); last = newNode; if (l == null) first = newNode; else l.next = newNode; size++;//多线程情况下,如果业务系统没做并发控制,size的数量会远远大于实际元素的数量 modCount++; } |
demo Lesson2LinkedListThreads 展示了在多线程且没有做并发控制的环境下,size的值远远大于了队列的实际值,100个线程,每个添加1000个元素,最后实际只加进去2030个元素: List的变量size值为:88371 第2031个元素取出为null 解决方案,使用锁或者使用ConcurrentLinkedQueue、LinkedBlockingQueue等支持添加元素为原子操作的队列。 上一节我们已经分析过LinkedBlockingQueue的put等方法的源码,是使用ReentrantLock来实现的添加元素原子操作。我们再简单看一下高并发queue的add和offer()方法,方法中使用了CAS来实现的无锁的原子操作: public boolean add(E e) { return offer(e); }
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
public boolean offer(E e) { checkNotNull(e); final Node<E> newNode = new Node<E>(e); for (Node<E> t = tail, p = t;;) { Node<E> q = p.next; if (q == null) { // p is last node if (p.casNext(null, newNode)) { // Successful CAS is the linearization point // for e to become an element of this queue, // and for newNode to become "live". if (p != t) // hop two nodes at a time casTail(t, newNode); // Failure is OK. return true; } // Lost CAS race to another thread; re-read next } else if (p == q) // We have fallen off list. If tail is unchanged, it // will also be off-list, in which case we need to // jump to head, from which all live nodes are always // reachable. Else the new tail is a better bet. p = (t != (t = tail)) ? t : head; else // Check for tail updates after two hops. p = (p != t && t != (t = tail)) ? t : q; } } |
接下来,我们再利用高并发queue对上面的demo进行改造,大家只要改变demo中的内容,讲下面两行的注释内容颠倒,即可发现没有丢失任何的元素: public static LinkedList list = new LinkedList(); //public static ConcurrentLinkedQueue list = new ConcurrentLinkedQueue(); 再看一下高性能queue的poll()方法,才觉得NB,取元素的方法也用CAS实现了原子操作,因此在实际使用的过程中,当我们在不那么在意元素处理顺序的情况下,队列元素的消费者,完全可以是多个,不会丢任何数据:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
public E poll() { restartFromHead: for (;;) { for (Node<E> h = head, p = h, q;;) { E item = p.item; if (item != null && p.casItem(item, null)) { // Successful CAS is the linearization point // for item to be removed from this queue. if (p != h) // hop two nodes at a time updateHead(h, ((q = p.next) != null) ? q : p); return item; } else if ((q = p.next) == null) { updateHead(h, p); return null; } else if (p == q) continue restartFromHead; else p = q; } } } |
关于ConcurrentLinkedQueue和LinkedBlockingQueue: 1.LinkedBlockingQueue是使用锁机制,ConcurrentLinkedQueue是使用CAS算法,虽然LinkedBlockingQueue的底层获取锁也是使用的CAS算法 2.关于取元素,ConcurrentLinkedQueue不支持阻塞去取元素,LinkedBlockingQueue支持阻塞的take()方法,如若大家需要ConcurrentLinkedQueue的消费者产生阻塞效果,需要自行实现 3.关于插入元素的性能,从字面上和代码简单的分析来看ConcurrentLinkedQueue肯定是最快的,但是这个也要看具体的测试场景,我做了两个简单的demo做测试,测试的结果如下,两个的性能差不多,但在实际的使用过程中,尤其在多cpu的服务器上,有锁和无锁的差距便体现出来了,ConcurrentLinkedQueue会比LinkedBlockingQueue快很多: demo Lesson2ConcurrentLinkedQueuePerform:在使用ConcurrentLinkedQueue的情况下100个线程循环增加的元素数为:33828193 demo Lesson2LinkedBlockingQueuePerform:在使用LinkedBlockingQueue的情况下100个线程循环增加的元素数为:33827382 from:https://www.cnblogs.com/mantu/p/5802393.html
View DetailsJava并发容器之非阻塞队列ConcurrentLinkedQueue
参考资料:http://blog.csdn.net/chenchaofuck1/article/details/51660521 实现一个线程安全的队列有两种实现方式:一种是使用阻塞算法,阻塞队列就是通过使用加锁的阻塞算法实现的;另一种非阻塞的实现方式则可以使用循环CAS(比较并交换)的方式来实现。 ConcurrentLinkedQueue是一个基于链表实现的无界线程安全队列,它采用先进先出的规则对节点进行排序,当我们添加一个元素的时候,它会添加到队列的尾部,当我们获取一个元素时,它会返回队列头部的元素。默认情况下head节点存储的元素为空,tair节点等于head节点。 一:入队 入队主要做两件事情, 第一是将入队节点设置成当前队列的最后一个节点。 第二是更新tail节点,如果原来的tail节点的next节点不为空,则将tail更新为刚入队的节点(即队尾结点),如果原来的tail节点(插入前的tail)的next节点为空,则将入队节点设置成tail的next节点(而tial不移动,成为倒数第二个节点),所以tail节点不总是尾节点!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
public boolean offer(E e) { if (e == null) throw new NullPointerException(); //入队前,创建一个入队节点 Node</e><e> n = new Node</e><e>(e); retry: //死循环,入队不成功反复入队。 for (;;) { //创建一个指向tail节点的引用 Node</e><e> t = tail; //p用来表示队列的尾节点,默认情况下等于tail节点。 Node</e><e> p = t; //获得p节点的下一个节点。 Node</e><e> next = succ(p); //next节点不为空,说明p不是尾节点,需要更新p后在将它指向next节点 if (next != null) { //循环了两次及其以上,并且当前节点还是不等于尾节点 if (hops > HOPS && t != tail) continue retry; p = next; } //如果p是尾节点,则设置p节点的next节点为入队节点。 else if (p.casNext(null, n)) { //如果tail节点有大于等于1个next节点,则将入队节点设置成tair节点,更新失败了也没关系,因为失败了表示有其他线程成功更新了tair节点。 if (hops >= HOPS) casTail(t, n); // 更新tail节点,允许失败 return true; } // p有next节点,表示p的next节点是尾节点,则重新设置p节点 else { p = succ(p); } } } } |
二:出队 不是每次出队时都更新head节点,当head节点里有元素时,直接弹出head节点里的元素,而不会更新head节点。只有当head节点里没有元素时,则弹出head的next结点并更新head结点为原来head的next结点的next结点。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
public E poll() { Node</e><e> h = head; // p表示头节点,需要出队的节点 Node</e><e> p = h; for (int hops = 0;; hops++) { // 获取p节点的元素 E item = p.getItem(); // 如果p节点的元素不为空,使用CAS设置p节点引用的元素为null,如果成功则返回p节点的元素。 if (item != null && p.casItem(item, null)) { if (hops >= HOPS) { //将p节点下一个节点设置成head节点 Node</e><e> q = p.getNext(); updateHead(h, (q != null) ? q : p); } return item; } // 如果头节点的元素为空或头节点发生了变化,这说明头节点已经被另外一个线程修改了。那么获取p节点的下一个节点 Node</e><e> next = succ(p); // 如果p的下一个节点也为空,说明这个队列已经空了 if (next == null) { // 更新头节点。 updateHead(h, p); break; } // 如果下一个元素不为空,则将头节点的下一个节点设置成头节点 p = next; } return null; } |
三:非阻塞却线程安全的原因 观察入队和出队的源码可以发现,无论入队还是出队,都是在死循环中进行的,也就是说,当一个线程调用了入队、出队操作时,会尝试获取链表的tail、head结点进行插入和删除操作,而插入和删除是通过CAS操作实现的,而CAS具有原子性。故此,如果有其他任何一个线程成功执行了插入、删除都会改变tail/head结点,那么当前线程的插入和删除操作就会失败,则通过循环再次定位tail、head结点位置进行插入、删除,直到成功为止。也就是说,ConcurrentLinkedQueue的线程安全是通过其插入、删除时采取CAS操作来保证的。不会出现同一个tail结点的next指针被多个同时插入的结点所抢夺的情况出现。 from:https://www.cnblogs.com/ygj0930/p/6544543.html
View Detailsjava 中 阻塞队列 非阻塞队列 和普通队列的区别
阻 塞队列与普通队列的区别在于,当队列是空的时,从队列中获取元素的操作将会被阻塞,或者当队列是满时,往队列里添加元素的操作会被阻塞。试图从空的阻塞队列中获取元素的线程将会被阻塞,直到其他的线程往空的队列插入新的元素。同样,试图往已满的阻塞队列中添加新元素的线程同样也会被阻塞,直到其他的线程使队列重新变得空闲起来,如从队列中移除一个或者多个元素,或者完全清空队列. 1.ArrayDeque, (数组双端队列) 2.PriorityQueue, (优先级队列) 3.ConcurrentLinkedQueue, (基于链表的并发队列) 4.DelayQueue, (延期阻塞队列)(阻塞队列实现了BlockingQueue接口) 5.ArrayBlockingQueue, (基于数组的并发阻塞队列) 6.LinkedBlockingQueue, (基于链表的FIFO阻塞队列) 7.LinkedBlockingDeque, (基于链表的FIFO双端阻塞队列) 8.PriorityBlockingQueue, (带优先级的无界阻塞队列) 9.SynchronousQueue (并发同步阻塞队列) 阻塞队列和生产者-消费者模式 阻塞队列(Blocking queue)提供了可阻塞的put和take方法,它们与可定时的offer和poll是等价的。如果Queue已经满了,put方法会被阻塞直到有空间可用;如果Queue是空的,那么take方法会被阻塞,直到有元素可用。Queue的长度可以有限,也可以无限;无限的Queue永远不会充满,所以它的put方法永远不会阻塞。 阻塞队列支持生产者-消费者设计模式。一个生产者-消费者设计分离了“生产产品”和“消费产品”。该模式不会发现一个工作便立即处理,而是把工作置于一个任务(“to do”)清单中,以备后期处理。生产者-消费者模式简化了开发,因为它解除了生产者和消费者之间相互依赖的代码。生产者和消费者以不同的或者变化的速度生产和消费数据,生产者-消费者模式将这些活动解耦,因而简化了工作负荷的管理。 生产者-消费者设计是围绕阻塞队列展开的,生产者把数据放入队列,并使数据可用,当消费者为适当的行为做准备时会从队列中获取数据。生产者不需要知道消费者的省份或者数量,甚至根本没有消费者—它们只负责把数据放入队列。类似地,消费者也不需要知道生产者是谁,以及是谁给它们安排的工作。BlockingQueue可以使用任意数量的生产者和消费者,从而简化了生产者-消费者设计的实现。最常见的生产者-消费者设计是将线程池与工作队列相结合。 阻塞队列简化了消费者的编码,因为take会保持阻塞直到可用数据出现。如果生产者不能足够快地产生工作,让消费者忙碌起来,那么消费者只能一直等待,直到有工作可做。同时,put方法的阻塞特性也大大地简化了生产者的编码;如果使用一个有界队列,那么当队列充满的时候,生产者就会阻塞,暂不能生成更多的工作,从而给消费者时间来赶进进度。 有界队列是强大的资源管理工具,用来建立可靠的应用程序:它们遏制那些可以产生过多工作量、具有威胁的活动,从而让你的程序在面对超负荷工作时更加健壮。 虽然生产者-消费者模式可以把生产者和消费者的代码相互解耦合,但是它们的行为还是间接地通过共享队列耦合在一起了 类库中包含一些BlockingQueue的实现,其中LinkedBlockingQueue和ArrayBlockingQueue是FIFO队列,与 LinkedList和ArrayList相似,但是却拥有比同步List更好的并发性能。PriorityBlockingQueue是一个按优先级顺序排序的队列,当你不希望按照FIFO的属性处理元素时,这个PriorityBolckingQueue是非常有用的。正如其他排序的容器一样,PriorityBlockingQueue可以比较元素本身的自然顺序(如果它们实现了Comparable),也可以使用一个 Comparator进行排序。 最后一个BlockingQueue的实现是SynchronousQueue,它根本上不是一个真正的队列,因为它不会为队列元素维护任何存储空间。不过,它维护一个排队的线程清单,这些线程等待把元素加入(enqueue)队列或者移出(dequeue)队列。因为SynchronousQueue没有存储能力,所以除非另一个线程已经准备好参与移交工作,否则put和take会一直阻止。SynchronousQueue这类队列只有在消费者充足的时候比较合适,它们总能为下一个任务作好准备。 非阻塞算法 基于锁的算法会带来一些活跃度失败的风险。如果线程在持有锁的时候因为阻塞I/O,页面错误,或其他原因发生延迟,很可能所有的线程都不能前进了。 一个线程的失败或挂起不应该影响其他线程的失败或挂起,这样的算法成为非阻塞(nonblocking)算法;如果算法的每一个步骤中都有一些线程能够继续执行,那么这样的算法称为锁自由(lock-free)算法。在线程间使用CAS进行协调,这样的算法如果能构建正确的话,它既是非阻塞的,又是锁自由的。非竞争的CAS总是能够成功,如果多个线程以一个CAS竞争,总会有一个胜出并前进。非阻塞算法堆死锁和优先级倒置有“免疫性”(但它们可能会出现饥饿和活锁,因为它们允许重进入)。 非阻塞算法通过使用低层次的并发原语,比如比较交换,取代了锁。原子变量类向用户提供了这些底层级原语,也能够当做“更佳的volatile变量”使用,同时提供了整数类和对象引用的原子化更新操作。 from:https://blog.csdn.net/u012240455/article/details/81844055
View Details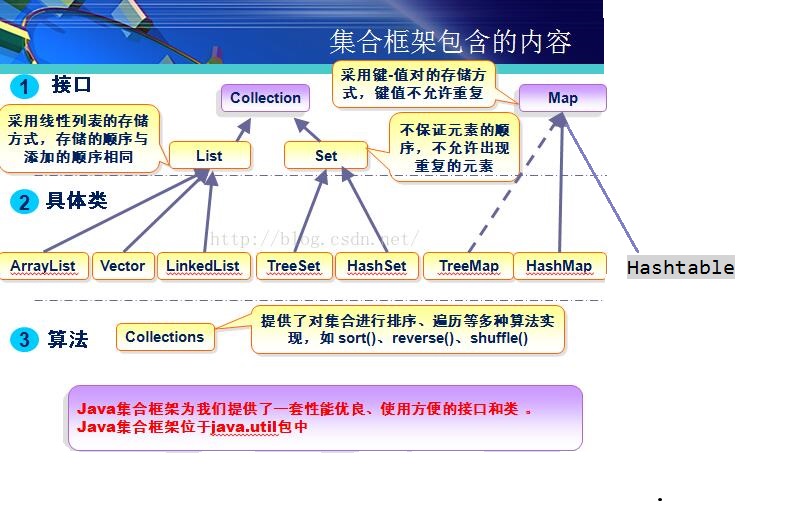
java队列——queue详细分析
Queue: 基本上,一个队列就是一个先入先出(FIFO)的数据结构 Queue接口与List、Set同一级别,都是继承了Collection接口。LinkedList实现了Deque接 口。 Queue的实现 1、没有实现的阻塞接口的LinkedList: 实现了java.util.Queue接口和java.util.AbstractQueue接口 内置的不阻塞队列: PriorityQueue 和 ConcurrentLinkedQueue PriorityQueue 和 ConcurrentLinkedQueue 类在 Collection Framework 中加入两个具体集合实现。 PriorityQueue 类实质上维护了一个有序列表。加入到 Queue 中的元素根据它们的天然排序(通过其 java.util.Comparable 实现)或者根据传递给构造函数的 java.util.Comparator 实现来定位。 ConcurrentLinkedQueue 是基于链接节点的、线程安全的队列。并发访问不需要同步。因为它在队列的尾部添加元素并从头部删除它们,所以只要不需要知道队列的大 小, ConcurrentLinkedQueue 对公共集合的共享访问就可以工作得很好。收集关于队列大小的信息会很慢,需要遍历队列。 2)实现阻塞接口的: java.util.concurrent 中加入了 BlockingQueue 接口和五个阻塞队列类。它实质上就是一种带有一点扭曲的 FIFO 数据结构。不是立即从队列中添加或者删除元素,线程执行操作阻塞,直到有空间或者元素可用。 五个队列所提供的各有不同: * ArrayBlockingQueue :一个由数组支持的有界队列。 * LinkedBlockingQueue :一个由链接节点支持的可选有界队列。 * PriorityBlockingQueue :一个由优先级堆支持的无界优先级队列。 * DelayQueue :一个由优先级堆支持的、基于时间的调度队列。 * SynchronousQueue :一个利用 BlockingQueue 接口的简单聚集(rendezvous)机制。 下表显示了jdk1.5中的阻塞队列的操作: add 增加一个元索 如果队列已满,则抛出一个IIIegaISlabEepeplian异常 remove 移除并返回队列头部的元素 如果队列为空,则抛出一个NoSuchElementException异常 element 返回队列头部的元素 如果队列为空,则抛出一个NoSuchElementException异常 offer 添加一个元素并返回true 如果队列已满,则返回false poll 移除并返问队列头部的元素 如果队列为空,则返回null peek 返回队列头部的元素 如果队列为空,则返回null put 添加一个元素 如果队列满,则阻塞 take 移除并返回队列头部的元素 如果队列为空,则阻塞 remove、element、offer 、poll、peek 其实是属于Queue接口。 阻塞队列的操作可以根据它们的响应方式分为以下三类:aad、removee和element操作在你试图为一个已满的队列增加元素或从空队列取得元素时 抛出异常。当然,在多线程程序中,队列在任何时间都可能变成满的或空的,所以你可能想使用offer、poll、peek方法。这些方法在无法完成任务时 只是给出一个出错示而不会抛出异常。 注意:poll和peek方法出错进返回null。因此,向队列中插入null值是不合法的 最后,我们有阻塞操作put和take。put方法在队列满时阻塞,take方法在队列空时阻塞。 LinkedBlockingQueue的容量是没有上限的(说的不准确,在不指定时容量为Integer.MAX_VALUE,不要然的话在put时怎么会受阻呢),但是也可以选择指定其最大容量,它是基于链表的队列,此队列按 FIFO(先进先出)排序元素。 ArrayBlockingQueue在构造时需要指定容量, 并可以选择是否需要公平性,如果公平参数被设置true,等待时间最长的线程会优先得到处理(其实就是通过将ReentrantLock设置为true来 达到这种公平性的:即等待时间最长的线程会先操作)。通常,公平性会使你在性能上付出代价,只有在的确非常需要的时候再使用它。它是基于数组的阻塞循环队 列,此队列按 FIFO(先进先出)原则对元素进行排序。 PriorityBlockingQueue是一个带优先级的 队列,而不是先进先出队列。元素按优先级顺序被移除,该队列也没有上限(看了一下源码,PriorityBlockingQueue是对 PriorityQueue的再次包装,是基于堆数据结构的,而PriorityQueue是没有容量限制的,与ArrayList一样,所以在优先阻塞 队列上put时是不会受阻的。虽然此队列逻辑上是无界的,但是由于资源被耗尽,所以试图执行添加操作可能会导致 OutOfMemoryError),但是如果队列为空,那么取元素的操作take就会阻塞,所以它的检索操作take是受阻的。另外,往入该队列中的元 素要具有比较能力。 DelayQueue(基于PriorityQueue来实现的)是一个存放Delayed […]
View DetailsHadoop、Spark等5种大数据框架对比,你的项目该用哪种?
数据是收集、整理、处理大容量数据集,并从中获得见解所需的非传统战略和技术的总称。虽然处理数据所需的计算能力或存储容量早已超过一台计算机的上限,但这种计算类型的普遍性、规模,以及价值在最近几年才经历了大规模扩展。 本文将介绍大数据系统一个最基本的组件:处理框架。处理框架负责对系统中的数据进行计算,例如处理从非易失存储中读取的数据,或处理刚刚摄入到系统中的数据。数据的计算则是指从大量单一数据点中提取信息和见解的过程。 下文将介绍这些框架: 仅批处理框架:Apache hadoop 仅流处理框架:Apache Storm;Apache Samza 混合框架:Apache Spark;Apache Flink 大数据处理框架是什么? 处理框架和处理引擎负责对数据系统中的数据进行计算。虽然“引擎”和“框架”之间的区别没有什么权威的定义,但大部分时候可以将前者定义为实际负责处理数据操作的组件,后者则可定义为承担类似作用的一系列组件。 例如Apache Hadoop可以看作一种以MapReduce作为默认处理引擎的处理框架。引擎和框架通常可以相互替换或同时使用。例如另一个框架Apache Spark可以纳入Hadoop并取代MapReduce。组件之间的这种互操作性是大数据系统灵活性如此之高的原因之一。 虽然负责处理生命周期内这一阶段数据的系统通常都很复杂,但从广义层面来看它们的目标是非常一致的:通过对数据执行操作提高理解能力,揭示出数据蕴含的模式,并针对复杂互动获得见解。 为了简化这些组件的讨论,我们会通过不同处理框架的设计意图,按照所处理的数据状态对其进行分类。一些系统可以用批处理方式处理数据,一些系统可以用流方式处理连续不断流入系统的数据。此外还有一些系统可以同时处理这两类数据。 在深入介绍不同实现的指标和结论之前,首先需要对不同处理类型的概念进行一个简单的介绍。 批处理系统 批处理在大数据世界有着悠久的历史。批处理主要操作大容量静态数据集,并在计算过程完成后返回结果。 批处理模式中使用的数据集通常符合下列特征… 有界:批处理数据集代表数据的有限集合 持久:数据通常始终存储在某种类型的持久存储位置中 大量:批处理操作通常是处理极为海量数据集的唯一方法 批处理非常适合需要访问全套记录才能完成的计算工作。例如在计算总数和平均数时,必须将数据集作为一个整体加以处理,而不能将其视作多条记录的集合。这些操作要求在计算进行过程中数据维持自己的状态。 需要处理大量数据的任务通常最适合用批处理操作进行处理。无论直接从持久存储设备处理数据集,或首先将数据集载入内存,批处理系统在设计过程中就充分考虑了数据的量,可提供充足的处理资源。由于批处理在应对大量持久数据方面的表现极为出色,因此经常被用于对历史数据进行分析。 大量数据的处理需要付出大量时间,因此批处理不适合对处理时间要求较高的场合。 Apache Hadoop Apache Hadoop是一种专用于批处理的处理框架。Hadoop是首个在开源社区获得极大关注的大数据框架。基于谷歌有关海量数据处理所发表的多篇论文与经验的Hadoop重新实现了相关算法和组件堆栈,让大规模批处理技术变得更易用。 新版Hadoop包含多个组件,即多个层,通过配合使用可处理批数据: HDFS:HDFS是一种分布式文件系统层,可对集群节点间的存储和复制进行协调。HDFS确保了无法避免的节点故障发生后数据依然可用,可将其用作数据来源,可用于存储中间态的处理结果,并可存储计算的最终结果。 YARN:YARN是Yet Another Resource Negotiator(另一个资源管理器)的缩写,可充当Hadoop堆栈的集群协调组件。该组件负责协调并管理底层资源和调度作业的运行。通过充当集群资源的接口,YARN使得用户能在Hadoop集群中使用比以往的迭代方式运行更多类型的工作负载。 MapReduce:MapReduce是Hadoop的原生批处理引擎。 批处理模式 Hadoop的处理功能来自MapReduce引擎。MapReduce的处理技术符合使用键值对的map、shuffle、reduce算法要求。基本处理过程包括: 从HDFS文件系统读取数据集 将数据集拆分成小块并分配给所有可用节点 针对每个节点上的数据子集进行计算(计算的中间态结果会重新写入HDFS) 重新分配中间态结果并按照键进行分组 通过对每个节点计算的结果进行汇总和组合对每个键的值进行“Reducing” 将计算而来的最终结果重新写入 HDFS 优势和局限 由于这种方法严重依赖持久存储,每个任务需要多次执行读取和写入操作,因此速度相对较慢。但另一方面由于磁盘空间通常是服务器上最丰富的资源,这意味着MapReduce可以处理非常海量的数据集。同时也意味着相比其他类似技术,Hadoop的MapReduce通常可以在廉价硬件上运行,因为该技术并不需要将一切都存储在内存中。MapReduce具备极高的缩放潜力,生产环境中曾经出现过包含数万个节点的应用。 MapReduce的学习曲线较为陡峭,虽然Hadoop生态系统的其他周边技术可以大幅降低这一问题的影响,但通过Hadoop集群快速实现某些应用时依然需要注意这个问题。 围绕Hadoop已经形成了辽阔的生态系统,Hadoop集群本身也经常被用作其他软件的组成部件。很多其他处理框架和引擎通过与Hadoop集成也可以使用HDFS和YARN资源管理器。 总结 Apache Hadoop及其MapReduce处理引擎提供了一套久经考验的批处理模型,最适合处理对时间要求不高的非常大规模数据集。通过非常低成本的组件即可搭建完整功能的Hadoop集群,使得这一廉价且高效的处理技术可以灵活应用在很多案例中。与其他框架和引擎的兼容与集成能力使得Hadoop可以成为使用不同技术的多种工作负载处理平台的底层基础。 流处理系统 流处理系统会对随时进入系统的数据进行计算。相比批处理模式,这是一种截然不同的处理方式。流处理方式无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作。 流处理中的数据集是“无边界”的,这就产生了几个重要的影响: 完整数据集只能代表截至目前已经进入到系统中的数据总量。 工作数据集也许更相关,在特定时间只能代表某个单一数据项。 处理工作是基于事件的,除非明确停止否则没有“尽头”。处理结果立刻可用,并会随着新数据的抵达继续更新。 流处理系统可以处理几乎无限量的数据,但同一时间只能处理一条(真正的流处理)或很少量(微批处理,Micro-batch Processing)数据,不同记录间只维持最少量的状态。虽然大部分系统提供了用于维持某些状态的方法,但流处理主要针对副作用更少,更加功能性的处理(Functional processing)进行优化。 功能性操作主要侧重于状态或副作用有限的离散步骤。针对同一个数据执行同一个操作会或略其他因素产生相同的结果,此类处理非常适合流处理,因为不同项的状态通常是某些困难、限制,以及某些情况下不需要的结果的结合体。因此虽然某些类型的状态管理通常是可行的,但这些框架通常在不具备状态管理机制时更简单也更高效。 此类处理非常适合某些类型的工作负载。有近实时处理需求的任务很适合使用流处理模式。分析、服务器或应用程序错误日志,以及其他基于时间的衡量指标是最适合的类型,因为对这些领域的数据变化做出响应对于业务职能来说是极为关键的。流处理很适合用来处理必须对变动或峰值做出响应,并且关注一段时间内变化趋势的数据。 Apache Storm Apache Storm是一种侧重于极低延迟的流处理框架,也许是要求近实时处理的工作负载的最佳选择。该技术可处理非常大量的数据,通过比其他解决方案更低的延迟提供结果。 流处理模式 Storm的流处理可对框架中名为Topology(拓扑)的DAG(Directed Acyclic Graph,有向无环图)进行编排。这些拓扑描述了当数据片段进入系统后,需要对每个传入的片段执行的不同转换或步骤。 拓扑包含: Stream:普通的数据流,这是一种会持续抵达系统的无边界数据。 Spout:位于拓扑边缘的数据流来源,例如可以是API或查询等,从这里可以产生待处理的数据。 Bolt:Bolt代表需要消耗流数据,对其应用操作,并将结果以流的形式进行输出的处理步骤。Bolt需要与每个Spout建立连接,随后相互连接以组成所有必要的处理。在拓扑的尾部,可以使用最终的Bolt输出作为相互连接的其他系统的输入。 Storm背后的想法是使用上述组件定义大量小型的离散操作,随后将多个组件组成所需拓扑。默认情况下Storm提供了“至少一次”的处理保证,这意味着可以确保每条消息至少可以被处理一次,但某些情况下如果遇到失败可能会处理多次。Storm无法确保可以按照特定顺序处理消息。 为了实现严格的一次处理,即有状态处理,可以使用一种名为Trident的抽象。严格来说不使用Trident的Storm通常可称之为Core Storm。Trident会对Storm的处理能力产生极大影响,会增加延迟,为处理提供状态,使用微批模式代替逐项处理的纯粹流处理模式。 为避免这些问题,通常建议Storm用户尽可能使用Core Storm。然而也要注意,Trident对内容严格的一次处理保证在某些情况下也比较有用,例如系统无法智能地处理重复消息时。如果需要在项之间维持状态,例如想要计算一个小时内有多少用户点击了某个链接,此时Trident将是你唯一的选择。尽管不能充分发挥框架与生俱来的优势,但Trident提高了Storm的灵活性。 Trident拓扑包含: 流批(Stream batch):这是指流数据的微批,可通过分块提供批处理语义。 操作(Operation):是指可以对数据执行的批处理过程。 优势和局限 目前来说Storm可能是近实时处理领域的最佳解决方案。该技术可以用极低延迟处理数据,可用于希望获得最低延迟的工作负载。如果处理速度直接影响用户体验,例如需要将处理结果直接提供给访客打开的网站页面,此时Storm将会是一个很好的选择。 […]
View Details