Category Archives: SQLServer
SQL Server中数据库文件的存放方式,文件和文件组
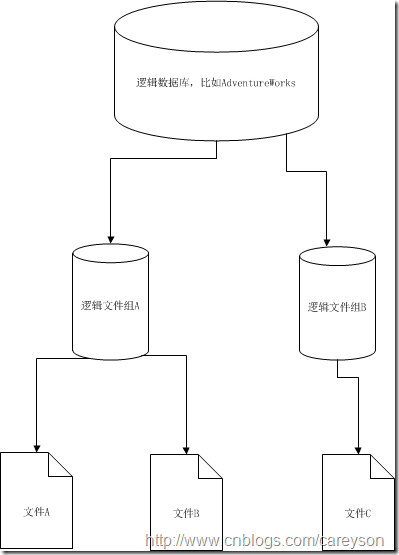
写在前面:上次我关于索引的文章有几个园友发站内信问我如何将索引和表存储在不同的硬盘上。我觉的需要专门写一篇文章来讲述一下文件和文件组应该更容易理解. 简介 在SQL SERVER中,数据库在硬盘上的存储方式和普通文件在Windows中的存储方式没有什么不同,仅仅是几个文件而已.SQL SERVER通过管理逻辑上的文件组的方式来管理文件.理解文件和文件组的概念对于更好的配置数据库来说是最基本的知识。 理解文件和文件组 在SQL SERVER中,通过文件组这个逻辑对象对存放数据的文件进行管理. 先来看一张图: 我们看到的逻辑数据库由一个或者多个文件组构成 而文件组管理着磁盘上的文件.而文件中存放着SQL SERVER的实际数据. 为什么通过文件组来管理文件 对于用户角度来说,需对创建的对象指定存储的文件组只有三种数据对象:表,索引和大对象(LOB) 使用文件组可以隔离用户和文件,使得用户针对文件组来建立表和索引,而不是实际磁盘中的文件。当文件移动或修改时,由于用户建立的表和索引是建立在文件组上的,并不依赖具体文件,这大大加强了可管理性. 还有一点是,使用文件组来管理文件可以使得同一文件组内的不同文件分布在不同的硬盘中,极大的提高了IO性能. SQL SERVER会根据每个文件设置的初始大小和增长量会自动分配新加入的空间,假设在同一文件组中的文件A设置的大小为文件B的两倍,新增一个数据占用三页(Page),则按比例将2页分配到文件A中,1页分配到文件B中. 文件的分类 首要文件:这个文件是必须有的,而且只能有一个。这个文件额外存放了其他文件的位置等信息.扩展名为.mdf 次要文件:可以建任意多个,用于不同目的存放.扩展名为.ndf 日志文件:存放日志,扩展名为.ldf 在SQL SERVER 2008之后,还新增了文件流数据文件和全文索引文件. 上述几种文件名扩展名可以随意修改,但是我推荐使用默认的扩展名。 我们可以通过如下语句查看数据库中的文件情况: 还有一点要注意的是,如果一个表是存在物理上的多个文件中时,则表的数据页的组织为N(N为具体的几个文件)个B树.而不是一个对象为一个B树. 创建和使用文件组 创建文件或是文件组可以通过在SSMS中或者使用T-SQL语句进行。对于一个数据库来说,既可以在创建时增加文件和文件组,也可以向现有的数据库添加文件和文件组.这几种方式大同小异.下面来看一下通过SSMS向现有数据库添加文件和文件组. 首先创建文件组: 文件组创建好后就可以向现有文件组中添加文件了: 下面我们就可以通过语句将创建的表或者索引加入到新的文件组中了: 使用多个文件的优点与缺点 通常情况下,小型的数据库并不需要创建多个文件来分布数据。但是随着数据的增长,使用单个文件的弊端就开始显现。 首先:使用多个文件分布数据到多个硬盘中可以极大的提高IO性能. 其次:多个文件对于数据略多的数据库来说,备份和恢复都会轻松很多.我碰见过遇到一个150G的数据库,手头却没有这么大的存储设备… 但是,在数据库的世界中,每一项好处往往伴随着一个坏处: 显而易见,使用多文件需要占用更多的磁盘空间。这是因为每个文件中都有自己的一套B树组织方式,和自己的增长空间。当然了,还有一套自己的碎片-.-但是在大多数情况下,多占点磁盘空间带来的弊端要远远小于多文件带来的好处. 总结 本文对SQL SERVER中文件和文件组的概念进行了简单阐述,并在文中讲述了文件和文件组的配置方式。按照业务组织好不同的文件组来分布不同的文件,使得性能的提升,对于你半夜少接几个电话的帮助是灰常大滴:-) from:http://www.cnblogs.com/CareySon/archive/2011/12/26/2301597.html
View Details使用子查询可提升 COUNT DISTINCT 速度 50 倍
注:这些技术是通用的,只不过我们选择使用Postgres的语法。使用独特的pgAdminIII生成解释图形。 很有用,但太慢 Count distinct是SQL分析时的祸根,因此它是我第一篇博客的不二选择。 首先:如果你有一个大的且能够容忍不精确的数据集,那像HyperLogLog这样的概率计数器应该是你最好的选择。(我们会在以后的博客中谈到HyperLogLog。)但对于需要快速、精准答案的查询,一些简单的子查询可以节省你很多时间。 让我们以我们一直使用的一个简单查询开始:哪个图表的用户访问量最大? 1 select 2 dashboards.name, 3 count(distinct time_on_site_logs.user_id) 4 from time_on_site_logs 5 join dashboards on time_on_site_logs.dashboard_id = dashboards.id 6 group by name 7 order by count desc 首先,我们假设user_id和dashboard_id上已经设置了索引,且有比图表和用户数多得多的日志条目。 一千万行数据时,查询需要48秒。要知道原因让我们看一下SQL解析: 它慢是因为数据库遍历了所有日志以及所有的图表,然后join它们,再将它们排序,这些都在真正的group和分组和聚合工作之前。 先聚合,然后Join group-聚合后的任何工作代价都要低,因为数据量会更小。group-聚合时我们不需使用dashboards.name,我们也可以先在数据库上做聚集,在join之前: 01 select 02 dashboards.name, 03 log_counts.ct 04 from dashboards 05 join ( 06 select 07 dashboard_id, 08 count(distinct user_id) as ct 09 from time_on_site_logs 10 group by dashboard_id 11 ) as log_counts 12 on log_counts.dashboard_id = dashboards.id 13 order by log_counts.ct desc 现在查询运行了20秒,提升了2.4倍。再次通过解析来看一下原因: 正如设计的,group-聚合在join之前。而且,额外的我们可以利用time_on_site_logs表里的索引。 首先,缩小数据集 我们可以做的更好。通过在整个日志表上group-聚合,我们处理了数据库中很多不必要的数据。Count distinct为每个group生成一个哈希——在本次环境中为每个dashboard_id——来跟踪哪些bucket中的哪些值已经检查过。 我们可以预先计算差异,而不是处理全部数据,这样只需要一个哈希集合。然后我们在此基础上做一个简单的聚集即可。 01 select 02 dashboards.name, 03 log_counts.ct 04 from dashboards 05 join ( 06 select distinct_logs.dashboard_id, 07 count(1) as ct 08 from ( 09 select distinct dashboard_id, user_id 10 from time_on_site_logs 11 ) as distinct_logs 12 group by distinct_logs.dashboard_id 13 ) as log_counts 14 on log_counts.dashboard_id = dashboards.id […]
View Details解决SQLServer中变更海量数据表结构时产生【无法修改表. Timeout 时间已到. 在操作完成之前超时时间已过或服务器未响应. 】
【解决办法】: 工具->选项>设计器->表设计器和数据库设计器->右侧勾选“为表设计器更新重写连接字符串的超时值”,在它下面的“事务超时时间”默认应该是 30 秒,改得稍微大一些,不过好像不能超过65535. 转自:http://blog.csdn.net/abandonship/article/details/8516541
View DetailsSQL SERVER2005 复制订阅功能介绍
一、复制简介 复制是将数据或数据库对象从一个数据库复制和分发到另外一个数据库,并进行数据同步,从而使源数据库和目标数据库保持一致。使用复制,可以在局域网和广域网、拨号连接、无线连接和 Internet 上将数据分发到不同位置以及分发给远程或移动用户。 一组SQL SERVER2005复制有发布服务器、分发服务器、订阅服服务器(图1 复制服务器之间的关系图)组成,他们之间的关系类似于书报行业的报社或出版社、邮局或书店、读者之间的关系。以报纸发行为例说明,发布服务器类似于报社,报社提供报刊的内容并印刷,是数据源;分发服务器相当于邮局,他将各报社的报刊送(分发)到订户手中;订阅服务器相当于订户,从邮局那里收到报刊。在实际的复制中,发布服务器是一种数据库实例,它通过复制向其他位置提供数据,分发服务器也是一种数据库实例,它起着存储区的作用,用于复制与一个或多个发布服务器相关联的特定数据。每个发布服务器都与分发服务器上的单个数据库(称作分发数据库)相关联。分发数据库存储复制状态数据和有关发布的元数据,并且在某些情况下为从发布服务器向订阅服务器移动的数据起着排队的作用。在很多情况下,一个数据库服务器实例充当发布服务器和分发服务器两个角色。这称为“本地分发服务器”。订阅服务器是接收复制数据的数据库实例。一个订阅服务器可以从多个发布服务器和发布接收数据。 (图1) 复制有三种类:事务复制、快照复制、合并复制。事务复制是将复制启用后的所有发布服务器上发布的内容在修改时传给订阅服务器,数据更改将按照其在发布服务器上发生的顺序和事务边界,应用于订阅服务器,在发布内部可以保证事务的一致性。快照复制将数据以特定时刻的瞬时状态分发,而不监视对数据的更新。发生同步时,将生成完整的快照并将其发送到订阅服务器。合并复制通常是从发布数据库对象和数据的快照开始,并且用触发器跟踪在发布服务器和订阅服务器上所做的后续数据更改和架构修改。订阅服务器在连接到网络时将与发布服务器进行同步,并交换自上次同步以来发布服务器和订阅服务器之间发生更改的所有行。 二、复制实例 这里以配置一个事务复制来说明复制配置过程 。 试验在同一台机器的二个实例间进行,实例名分别是SERVER01、SERVER02 。将SERVER01配置发布服务器和分发服务器(也就是前面提到的“本地分发服务器”),SERVER02配置为订阅服务器。在本例中将SERVER01中一个DBCoper库中person表作为发布的数据,在发布前请确保person表有主键、SQL SERVER 代理自动启动、发布数据库是日志是完整模式。 第一步:完全备份SERVER01 DBCopy数据库,在SERVER02上恢复DBCopy数据库(复制前的同步,使用发布的源和目标数据一致) 第二步:在SERVER01上设置发布和分发A 在SERVER01的复制节点—>本地发布右键选择新建订阅(图2) ()(图2) B B 在新建发布向导中首先要求选择分发服务器,本例选择本机作为分发服务器,选择默认值。(图3) (图3) C 向导第三步要求选择快照的路径,一般情况下选择默认路径 D 向导第四步选择发布的数据库(如图四),选择DBCopy (图4) E 接着选择发布的类型,这里选择事务复制(如图5) (图5) F 选择发布的内容(PERSON),这里不仅可以发表,还可以发布其他的数据库对象,比如函数。在选择某一个表之后还可以选择发布某一列或几列。在这个步骤下一个界面中可以选择要发布的行。 (图6) G 设置发布的内容之后设置 运行SQL代理的账号。设置如下: (图7) H 设置上一步之后,给复制起个名字PersonCopy。到此为止,发布和分发已配置成功。(如图8) (图8) 第三步:配置订阅。 订阅有两种方种,一种是由发布服务器向订阅服务器“推”数据,由订阅服务器去请求订阅数据。本例在SERVER02上设置请求订阅。 A 第一步在SERVER02复制节点右击订阅,新建订阅(图9) (图9) B 选择发布服务器,在下拉列表框中选择查找SQL SERVER 发布服务器,选择SERVER01,就可以看到刚才新建的发布PersonCopy。如图(10) (图10) C 选择订阅方式。(图11) 这里选择请求订阅 (图11) D 选择订阅的本地数据库(如图12)。 (图12) E 设置完本地数据库之后要求设置运行代理的安全性,设置成SQL 代理账号。完成以上设置后,订阅已设置完成。 在SERVER01表中插入一条新记录后,在SERVER02中去检查是否同步过来。一般来说,几乎SERVER01执行完了,SERVER02就可以看到更新后的数据。 转自:http://blog.csdn.net/kira155716/article/details/6072747
View DetailsSQL Server存储过程Return、output参数及使用技巧
SQL Server目前正日益成为WindowNT操作系统上面最为重要的一种数据库管理系统,随着 SQL Server2000的推出,微软的这种数据库服务系统真正地实现了在WindowsNT/2000系列操作系统一统天下的局面,在微软的操作系统上,没有任何一种数据库系统能与之抗衡,包括数据库领域中的领头羊甲骨文公司的看家数据库Oracle在内。不可否认,SQL Server最大的缺陷就是只能运行在微软自己的操作系统上,这一点是SQL Server的致命点。但在另一方面却也成了最好的促进剂,促使SQL Server在自己仅有的“土地”上面将自己的功能发挥到了极至最大限度的利用了NT系列操作系统的各种潜能!作为SQL Server数据库系统中很重要的一个概念就是存储过程,合理的使用存储过程,可以有效的提高程序的性能;并且将商业逻辑封装在数据库系统中的存储过程中,可以大大提高整个软件系统的可维护性,当你的商业逻辑发生改变的时候,不再需要修改并编译客户端应用程序以及重新分发他们到为数众多的用户手中,你只需要修改位于服务器端的实现相应商业逻辑的存储过程即可。合理的编写自己需要的存储过程,可以最大限度的利用SQL Server的各种资源。下面我们来看看各种编写SQL Server存储过程和使用存储过程的技巧经验。 Input 此参数只用于将信息从应用程序传输到存储过程。 InputOutput 此参数可将信息从应用程序传输到存储过程,并将信息从存储过程传输回应用程序。 Output 此参数只用于将信息从存储过程传输回应用程序。 ReturnValue 此参数表示存储过程的返回值。SQL Server 的存储过程参数列表中不显示该参数。它只与存储过程的 RETURN 语句中的值相关联。 存储过程为主键生成新值后,通常使用存储过程中的 RETURN 语句返回该值,因此用来访问该值的参数类型是 ReturnValue 参数。 1、不带输入参数的简单存储过程 if object_id('up_user') is not null drop proc up_user go create proc up_user as set nocount on delcare @name varchar(10) begin select @name=uname from user end set nocount off go esec up_user 2、带输入参数的简单存储过程 if object_id('up_user') is not null drop proc up_user go create proc up_user @id int as set nocount on delcare @name varchar(10) begin select @name=uname from user where uid=@id end set nocount off go --执行该存储过程 esec up_user 1 3、带Return参数的存储过程 if […]
View DetailsROW_NUMBER() OVER函数的基本用法用法
语法:ROW_NUMBER() OVER(PARTITION BY COLUMN ORDER BY COLUMN) 简单的说row_number()从1开始,为每一条分组记录返回一个数字,这里的ROW_NUMBER() OVER (ORDER BY xlh DESC) 是先把xlh列降序,再为降序以后的没条xlh记录返回一个序号。 示例: xlh row_num 1700 1 1500 2 1085 3 710 4 row_number() OVER (PARTITION BY COL1 ORDER BY COL2) 表示根据COL1分组,在分组内部根据 COL2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的) 实例: 初始化数据 create table employee (empid int ,deptid int ,salary decimal(10,2)) insert into employee values(1,10,5500.00) insert into employee values(2,10,4500.00) insert into employee values(3,20,1900.00) insert into employee values(4,20,4800.00) insert into employee values(5,40,6500.00) insert into employee values(6,40,14500.00) insert into employee values(7,40,44500.00) insert into employee values(8,50,6500.00) insert into employee values(9,50,7500.00) 数据显示为 empid deptid salary ———-- ———-- ————————————— […]
View Details存储过程中执行动态Sql语句
MSSQL为我们提供了两种动态执行SQL语句的命令,分别是EXEC和sp_executesql;通常,sp_executesql则更具有优势,它提供了输入输出接口,而EXEC没有。还有一个最大的好处就是利用sp_executesql,能够重用执行计划,这就大大提供了执行性能,还可以编写更安全的代码。EXEC在某些情况下会更灵活。除非您有令人信服的理由使用EXEC,否侧尽量使用sp_executesql. 1.EXEC的使用 EXEC命令有两种用法,一种是执行一个存储过程,另一种是执行一个动态的批处理。以下所讲的都是第二种用法。 下面先使用EXEC演示一个例子,代码1 代码 DECLARE @TableName VARCHAR(50),@Sql NVARCHAR (MAX),@OrderID INT; SET @TableName = 'Orders'; SET @OrderID = 10251; SET @sql = ’SELECT * FROM '+QUOTENAME(@TableName) +’WHERE OrderID = '+ CAST(@OrderID AS VARCHAR(10))+' ORDER BY ORDERID DESC' EXEC(@sql); 注:这里的EXEC括号中只允许包含一个字符串变量,但是可以串联多个变量,如果我们这样写EXEC: EXEC('SELECT TOP('+ CAST(@TopCount AS VARCHAR(10)) +')* FROM '+ QUOTENAME(@TableName) +' ORDER BY ORDERID DESC'); SQL编译器就会报错,编译不通过,而如果我们这样:
|
1 |
EXEC(@sql+@sql2+@sql3); |
编译器就会通过; 所以最佳的做法是把代码构造到一个变量中,然后再把该变量作为EXEC命令的输入参数,这样就不会受限制了。 EXEC的缺点是不提供接口,这里的接口是指,它不能执行一个包含一个带变量符的批处理,如下 代码 DECLARE @TableName VARCHAR(50),@Sql NVARCHAR(MAX),@OrderID INT; SET @TableName = 'Orders'; SET @OrderID = 10251; SET @sql = 'SELECT * FROM '+QUOTENAME(@TableName) + ’WHERE OrderID = @OrderID […]
View DetailsSQL Server 存储过程
Transact-SQL中的存储过程,非常类似于Java语言中的方法,它可以重复调用。当存储过程执行一次后,可以将语句缓存中,这样下次执行的时候直接使用缓存中的语句。这样就可以提高存储过程的性能。 Ø 存储过程的概念 存储过程Procedure是一组为了完成特定功能的SQL语句集合,经编译后存储在数据库中,用户通过指定存储过程的名称并给出参数来执行。 存储过程中可以包含逻辑控制语句和数据操纵语句,它可以接受参数、输出参数、返回单个或多个结果集以及返回值。 由于存储过程在创建时即在数据库服务器上进行了编译并存储在数据库中,所以存储过程运行要比单个的SQL语句块要快。同时由于在调用时只需用提供存储过程名和必要的参数信息,所以在一定程度上也可以减少网络流量、简单网络负担。 1、 存储过程的优点 A、 存储过程允许标准组件式编程 存储过程创建后可以在程序中被多次调用执行,而不必重新编写该存储过程的SQL语句。而且数据库专业人员可以随时对存储过程进行修改,但对应用程序源代码却毫无影响,从而极大的提高了程序的可移植性。 B、 存储过程能够实现较快的执行速度 如果某一操作包含大量的T-SQL语句代码,分别被多次执行,那么存储过程要比批处理的执行速度快得多。因为存储过程是预编译的,在首次运行一个存储过程时,查询优化器对其进行分析、优化,并给出最终被存在系统表中的存储计划。而批处理的T-SQL语句每次运行都需要预编译和优化,所以速度就要慢一些。 C、 存储过程减轻网络流量 对于同一个针对数据库对象的操作,如果这一操作所涉及到的T-SQL语句被组织成一存储过程,那么当在客户机上调用该存储过程时,网络中传递的只是该调用语句,否则将会是多条SQL语句。从而减轻了网络流量,降低了网络负载。 D、 存储过程可被作为一种安全机制来充分利用 系统管理员可以对执行的某一个存储过程进行权限限制,从而能够实现对某些数据访问的限制,避免非授权用户对数据的访问,保证数据的安全。 Ø 系统存储过程 系统存储过程是系统创建的存储过程,目的在于能够方便的从系统表中查询信息或完成与更新数据库表相关的管理任务或其他的系统管理任务。系统存储过程主要存储在master数据库中,以“sp”下划线开头的存储过程。尽管这些系统存储过程在master数据库中,但我们在其他数据库还是可以调用系统存储过程。有一些系统存储过程会在创建新的数据库的时候被自动创建在当前数据库中。 常用系统存储过程有:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
exec sp_databases; --查看数据库 exec sp_tables; --查看表 exec sp_columns student;--查看列 exec sp_helpIndex student;--查看索引 exec sp_helpConstraint student;--约束 exec sp_stored_procedures; exec sp_helptext 'sp_stored_procedures';--查看存储过程创建、定义语句 exec sp_rename student, stuInfo;--修改表、索引、列的名称 exec sp_renamedb myTempDB, myDB;--更改数据库名称 exec sp_defaultdb 'master', 'myDB';--更改登录名的默认数据库 exec sp_helpdb;--数据库帮助,查询数据库信息 exec sp_helpdb master; |
系统存储过程示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
--表重命名 exec sp_rename 'stu', 'stud'; select * from stud; --列重命名 exec sp_rename 'stud.name', 'sName', 'column'; exec sp_help 'stud'; --重命名索引 exec sp_rename N'student.idx_cid', N'idx_cidd', N'index'; exec sp_help 'student'; --查询所有存储过程 select * from sys.objects where type = 'P'; select * from sys.objects where type_desc like '%pro%' and name like 'sp%'; |
Ø 用户自定义存储过程 1、 创建语法
|
1 2 3 4 5 6 7 |
create proc | procedure pro_name [{@参数数据类型} [=默认值] [output], {@参数数据类型} [=默认值] [output], .... ] as SQL_statements |
2、 创建不带参数存储过程
|
1 2 3 4 5 6 7 8 9 10 |
--创建存储过程 if (exists (select * from sys.objects where name = 'proc_get_student')) drop proc proc_get_student go create proc proc_get_student as select * from student; --调用、执行存储过程 exec proc_get_student; |
3、 修改存储过程
|
1 2 3 4 |
--修改存储过程 alter proc proc_get_student as select * from student; |
4、 带参存储过程
|
1 2 3 4 5 6 7 8 9 10 |
--带参存储过程 if (object_id('proc_find_stu', 'P') is not null) drop proc proc_find_stu go create proc proc_find_stu(@startId int, @endId int) as select * from student where id between @startId and @endId go exec proc_find_stu 2, 4; |
5、 带通配符参数存储过程
|
1 2 3 4 5 6 7 8 9 10 11 |
--带通配符参数存储过程 if (object_id('proc_findStudentByName', 'P') is not null) drop proc proc_findStudentByName go create proc proc_findStudentByName(@name varchar(20) = '%j%', @nextName varchar(20) = '%') as select * from student where name like @name and name like @nextName; go exec proc_findStudentByName; exec proc_findStudentByName '%o%', 't%'; |
6、 带输出参数存储过程
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
if (object_id('proc_getStudentRecord', 'P') is not null) drop proc proc_getStudentRecord go create proc proc_getStudentRecord( @id int, --默认输入参数 @name varchar(20) out, --输出参数 @age varchar(20) output--输入输出参数 ) as select @name = name, @age = age from student where id = @id and sex = @age; go -- declare @id int, @name varchar(20), @temp varchar(20); set @id = 7; set @temp = 1; exec proc_getStudentRecord @id, @name out, @temp output; select @name, @temp; print @name + '#' + @temp; |
7、 不缓存存储过程
|
1 2 3 4 5 6 7 8 9 10 11 |
--WITH RECOMPILE 不缓存 if (object_id('proc_temp', 'P') is not null) drop proc proc_temp go create proc proc_temp with recompile as select * from student; go exec proc_temp; |
8、 加密存储过程
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
--加密WITH ENCRYPTION if (object_id('proc_temp_encryption', 'P') is not null) drop proc proc_temp_encryption go create proc proc_temp_encryption with encryption as select * from student; go exec proc_temp_encryption; exec sp_helptext 'proc_temp'; exec sp_helptext 'proc_temp_encryption'; |
9、 带游标参数存储过程
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
if (object_id('proc_cursor', 'P') is not null) drop proc proc_cursor go create proc proc_cursor @cur cursor varying output as set @cur = cursor forward_only static for select id, name, age from student; open @cur; go --调用 declare @exec_cur cursor; declare @id int, @name varchar(20), @age int; exec proc_cursor @cur = @exec_cur output;--调用存储过程 fetch next from @exec_cur into @id, @name, @age; while (@@fetch_status = 0) begin fetch next from @exec_cur into @id, @name, @age; print 'id: ' + convert(varchar, @id) + ', name: ' + @name + ', age: ' + convert(char, @age); end close @exec_cur; deallocate @exec_cur;--删除游标 |
10、 分页存储过程
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
---存储过程、row_number完成分页 if (object_id('pro_page', 'P') is not null) drop proc proc_cursor go create proc pro_page @startIndex int, @endIndex int as select count(*) from product ; select * from ( select row_number() over(order by pid) as rowId, * from product ) temp where temp.rowId between @startIndex and @endIndex go --drop proc pro_page exec pro_page 1, 4 -- --分页存储过程 if (object_id('pro_page', 'P') is not null) drop proc pro_stu go create procedure pro_stu( @pageIndex int, @pageSize int ) as declare @startRow int, @endRow int set @startRow = (@pageIndex - 1) * @pageSize +1 set @endRow = @startRow + @pageSize -1 select * from ( select *, row_number() over (order by id asc) as number from student ) t where t.number between @startRow and @endRow; exec pro_stu 2, 2; |
Ø Raiserror Raiserror返回用户定义的错误信息,可以指定严重级别,设置系统变量记录所发生的错误。 语法如下:
|
1 2 3 4 5 |
Raiserror({msg_id | msg_str | @local_variable} {, severity, state} [,argument[,…n]] [with option[,…n]] ) |
# msg_id:在sysmessages系统表中指定的用户定义错误信息 # msg_str:用户定义的信息,信息最大长度在2047个字符。 # severity:用户定义与该消息关联的严重级别。当使用msg_id引发使用sp_addmessage创建的用户定义消息时,raiserror上指定严重性将覆盖sp_addmessage中定义的严重性。 任何用户可以指定0-18直接的严重级别。只有sysadmin固定服务器角色常用或具有alter trace权限的用户才能指定19-25直接的严重级别。19-25之间的安全级别需要使用with log选项。 # state:介于1至127直接的任何整数。State默认值是1。
|
1 2 3 4 5 6 7 |
raiserror('is error', 16, 1); select * from sys.messages; --使用sysmessages中定义的消息 raiserror(33003, 16, 1); raiserror(33006, 16, 1); 转自:<a href="http://www.cnblogs.com/hoojo/archive/2011/07/19/2110862.html">http://www.cnblogs.com/hoojo/archive/2011/07/19/2110862.html</a> |
SqlServer2005高效分页sql查询语句汇总
sqlserver2005不支持关键字limit ,所以它的分页sql查询语句将不能用mysql的方式进行,幸好sqlserver2005提供了top,rownumber等关键字,这样就能通过这几个关键字实现分页。 下面是本人在网上查阅到的几种查询脚本的写法: 几种sqlserver2005高效分页sql查询语句 top方案: sql codeselect top 10 * from table1 where id not in(select top 开始的位置 id from table1) max: sql codeselect top 10 * from table1 where id>(select max(id) from (select top 开始位置 id from table1order by id)tt) row: sql codeselect * from ( select row_number()over(order by tempcolumn)temprownumber,* from (select top 开始位置+10 tempcolumn=0,* from table1)t )tt where temprownumber>开始位置 3种分页方式,分别是max方案,top方案,row方案 效率: 第1:row 第2:max 第3:top 缺点: max:必须用户编写复杂sql,不支持非唯一列排序 top:必须用户编写复杂sql,不支持复合主键 row:不支持sqlserver2000 测试数据: 共320万条数据,每页显示10条数据,分别测试了2万页、15万页和32万页。 页码,top方案,max方案,row方案 2万,60ms,46ms,33ms 15万,453ms,343ms,310ms 32万,953ms,720ms,686ms 是一种通过程序拼接sql语句的分页方案, 用户提过的sql语句不需要编写复杂的sql逻辑 诺用户提供sql如下 sql code select * from table1 从第5条开始,查询5条,处理后sql变为 sql code […]
View Detailswin8安装SQL Server 2005问题解决方法
1、正常安装任一版本的SQL Server 2005(最好安装企业版)。 2、安装到SqlServer服务的时候提示启动服务失败(提示重试的时候),这里就是关键啦,下载本文的两个附件,里面是SP4(2005.90.5000.0)版本的sqlservr.exe和sqlos.dll。 sqlservr64.rar sqlservr32.rar 3、进入SQL Server 2005的安装路径,进入MSSQL文件夹下面的Binn文件夹,在该文件夹里面搜索“sqlservr.exe”文件,并把它复制一份到桌面或其它地方作为备份,然后把上面第2步下载的文件解压出 sqlservr.exe和sqlos.dll两个文件,复制到Binn文件夹里面覆盖原文件(即点击替换)。 例如“D:\Program Files\Microsoft SQL Server\MSSQL.2\MSSQL\Binn”。 4、点击“重试”,安装继续,安装程序安装成功。 5、安装完成之后,去任务管理器找到sqlservr.exe进程,把它结束掉,把备份的sqlservr.exe文件还原回去,也就是替换回去(否则SP4安装程序以为你已经应用过SP4),然后立即打上SP4补丁(即安装已经下载好的SP4更新程序)。(在此之前不要运行SQL任何软件) 6、安装完SP4补丁,SQL Server运行正常。(补丁可以网上下载,是一个exe格式的可执行文件,实际上就是一个更新软件包,也可叫补丁,只是叫法不一样)。 7、连接SQL服务器时可能会遇到下面所示的错误(红叉错误)。 解决办法: 打开SQLServer Management Studio的时候,不要直接点击,要右击选择“以管理员身份运行”。 服务器类型:数据库引擎 服务器名称:MyComputer\SQLSERVER2005(或localhost\SQLSERVER2005) 身份验证:因为安装的时候,我选择的是混合验证模式,所以这里的身份验证可以采用两种模式,一种是Windwos身体验证,直接点连接就可以连接上。另一种是SQL Server身份验证,这种验证方式就要使用登录名和密码,登录名是安装时的默认登录名(即sa),密码是安装时输入的密码。 使用windows身份验证 使用SQL Server身份验证 (注:服务器名称格式是“主机名\服务器名”,上面的MyComputer是本机的主机名(即计算机名),服务器名是安装的时候的“实例名”,因为我安装的时候不是采用默认“实例名”,而是选择了第二项“命名实例”(如下图),自己输入了一个名字叫“SQLServer2005”,所以服务器名称里面的数据库名就是SQLServer2005了,输入服务器名的时候不分大小写)。 另外,服务器名称前面“主机名”部分除了可以使用计算机名外,还可以使用localhost,即用“localhost\SQLSERVER2005”一样可以登录,localhost就是本机的意思。 转自:http://blog.sina.com.cn/s/blog_6db312f10101aak3.html
View Details