Category Archives: Programming Language
安装Ecshop首页出现报错:Only variables should be passed by referen
出现下面这就话:
|
1 2 3 |
<span style="color: #ed1c24;">Strict Standards: Only variables should be passed by reference in D:\wamp\ecshop\includes\cls_template.php on line 406</span> <wbr /> 第406行:<span style="color: #fd1856;">$tag_sel = array_shift(explode(' ', $tag));</span> |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
<span style="color: #0a07ff;">解决办法 1 </span> 5.3以上版本的问题,应该也和配置有关 只要406行把这一句拆成两句就没有问题了 $tag_sel = array_shift(explode(' ', $tag)); 改成: $tag_arr = explode(' ', $tag); $tag_sel = array_shift($tag_arr); <wbr /> <span style="color: #ed1c24;">(实验过,绝对可行) </span>因为array_shift的参数是引用传递的,5.3以上默认只能传递具体的变量,而不能通过函数返回值 <span style="color: #0a07ff;">解决办法 2 :</span> 或则如果这样配置的话: error_reporting = E_ALL | E_STRICT from:<a href="http://blog.sina.com.cn/s/blog_7dc986fc01013acp.html">http://blog.sina.com.cn/s/blog_7dc986fc01013acp.html</a> |
Log4Net使用指南
声明:本文内容主要译自Nauman Leghari的Using log4net,亦加入了个人的一点心得(节3.1.4)。 请在这里下载示例代码 1 简介 1.1 Log4net的优点: 几乎所有的大型应用都会有自己的用于跟踪调试的API。因为一旦程序被部署以后,就不太可能再利用专门的调试工具了。然而一个管理员可能需要有一套强大的日志系统来诊断和修复配置上的问题。 经验表明,日志记录往往是软件开发周期中的重要组成部分。它具有以下几个优点:它可以提供应用程序运行时的精确环境,可供开发人员尽快找到应用程序中的Bug;一旦在程序中加入了Log 输出代码,程序运行过程中就能生成并输出日志信息而无需人工干预。另外,日志信息可以输出到不同的地方(控制台,文件等)以备以后研究之用。 Log4net就是为这样一个目的设计的,用于.NET开发环境的日志记录包。 1.2 Log4net的安装: 用户可以从http://logging.apache.org/log4net/下载log4net的源代码。解压软件包后,在解压的src目录下将log4net.sln载入Visual Studio .NET,编译后可以得到log4net.dll。用户要在自己的程序里加入日志功能,只需将log4net.dll引入工程即可。 2 Log4net的结构 log4net 有四种主要的组件,分别是Logger(记录器), Repository(库), Appender(附着器)以及 Layout(布局). 2.1 Logger 2.1.1 Logger接口 Logger是应用程序需要交互的主要组件,它用来产生日志消息。产生的日志消息并不直接显示,还要预先经过Layout的格式化处理后才会输出。 Logger提供了多种方式来记录一个日志消息,你可以在你的应用程序里创建多个Logger,每个实例化的Logger对象都被log4net框架作为命名实体(named entity)来维护。这意味着为了重用Logger对象,你不必将它在不同的类或对象间传递,只需要用它的名字为参数调用就可以了。log4net框架使用继承体系,继承体系类似于.NET中的名字空间。也就是说,如果有两个logger,分别被定义为a.b.c和a.b,那么我们说a.b是a.b.c的祖先。每一个logger都继承了祖先的属性 Log4net框架定义了一个ILog接口,所有的logger类都必须实现这个接口。如果你想实现一个自定义的logger,你必须首先实现这个接口。你可以参考在/extension目录下的几个例子。 ILog接口的定义如下: public interface ILog { void Debug(object message); void Info(object message); void Warn(object message); void Error(object message); void Fatal(object message); //以上的每一个方法都有一个重载的方法,用来支持异常处理。 //每一个重载方法都如下所示,有一个异常类型的附加参数。 void Debug(object message, Exception ex); // … //Boolean 属性用来检查Logger的日志级别 //(我们马上会在后面看到日志级别) bool isDebugEnabled; bool isInfoEnabled; //… 其他方法对应的Boolean属性 } Log4net框架定义了一个叫做LogManager的类,用来管理所有的logger对象。它有一个GetLogger()静态方法,用我们提供的名字参数来检索已经存在的Logger对象。如果框架里不存在该Logger对象,它也会为我们创建一个Logger对象。代码如下所示: log4net.ILog log = log4net.LogManager.GetLogger("logger-name"); 通常来说,我们会以类(class)的类型(type)为参数来调用GetLogger(),以便跟踪我们正在进行日志记录的类。传递的类(class)的类型(type)可以用typeof(Classname)方法来获得,或者可以用如下的反射方法来获得: System.Reflection.MethodBase.GetCurrentMethod().DeclaringType 尽管符号长了一些,但是后者可以用于一些场合,比如获取调用方法的类(class)的类型(type)。 2.1.2 日志的级别 正如你在ILog的接口中看到的一样,有五种不同的方法可以跟踪一个应用程序。事实上,这五种方法是运作在Logger对象设置的不同日志优先级别上。这几种不同的级别是作为常量定义在log4net.spi.Level类中。你可以在程序中使用任何一种方法。但是在最后的发布中你也许不想让所有的代码来浪费你的CPU周期,因此,框架提供了7种级别和相应的Boolean属性来控制日志记录的类型。 Level有以下几种取值 级别 允许的方法 Boolean属性 优先级别 OFF Highest FATAL void Fatal(…); bool […]
View Detailslog4net使用详解
说明:本程序演示如何利用log4net记录程序日志信息。log4net是一个功能著名的开源日志记录组件。利用log4net可以方便地将日志信息记录到文件、控制台、Windows事件日志和数据库(包括MS SQL Server, Access, Oracle9i,Oracle8i,DB2,SQLite)中。并且我们还可以记载控制要记载的日志级别,可以记载的日志类别包括:FATAL(致命错误)、ERROR(一般错误)、WARN(警告)、INFO(一般信息)、DEBUG(调试信息)。要想获取最新版本的log4net组件库,可以到官方网站http://logging.apache.org/log4net/下载。现在的最新版本是1.2.10。 下面的例子展示了如何利用log4net记录日志 。 首先从官方网站下载最近版本的log4net组件,现在的最新版本是1.2.10。在程序中我们只需要log4net.dll文件就行了,添加对log4net.dll的引用,就可以在程序中使用了。 接着我们配置相关的配置文件(WinForm对应的是*.exe.config,WebForm对应的是*.config),本实例中是控制台应用程序,配置如下(附各配置的说明):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 |
<?xml version="1.0" encoding="utf-8" ?> <configuration> <configSections> <section name="log4net" type="System.Configuration.IgnoreSectionHandler"/> </configSections> <appSettings> </appSettings> <log4net> <!--定义输出到文件中--> <appender name="LogFileAppender" type="log4net.Appender.FileAppender"> <!--定义文件存放位置--> <file value="D:/log4netfile.txt" /> <appendToFile value="true" /> <rollingStyle value="Date" /> <datePattern value="yyyyMMdd-HH:mm:ss" /> <layout type="log4net.Layout.PatternLayout"> <!--每条日志末尾的文字说明--> <footer value="by 周公" /> <!--输出格式--> <!--样例:2008-03-26 13:42:32,111 [10] INFO Log4NetDemo.MainClass [(null)] – info--> <conversionPattern value="记录时间:%date 线程ID:[%thread] 日志级别:%-5level 出错类:%logger property:[%property{NDC}] – 错误描述:%message%newline" /> </layout> </appender> <!--定义输出到控制台命令行中--> <appender name="ConsoleAppender" type="log4net.Appender.ConsoleAppender"> <layout type="log4net.Layout.PatternLayout"> <conversionPattern value="%date [%thread] %-5level %logger [%property{NDC}] – %message%newline" /> </layout> </appender> <!--定义输出到windows事件中--> <appender name="EventLogAppender" type="log4net.Appender.EventLogAppender"> <layout type="log4net.Layout.PatternLayout"> <conversionPattern value="%date [%thread] %-5level %logger [%property{NDC}] – %message%newline" /> </layout> </appender> <!--定义输出到数据库中,这里举例输出到Access数据库中,数据库为C盘的log4net.mdb--> <appender name="AdoNetAppender_Access" type="log4net.Appender.AdoNetAppender"> <connectionString value="Provider=Microsoft.Jet.OLEDB.4.0;Data Source=C:log4net.mdb" /> <commandText value="INSERT INTO LogDetails ([LogDate],[Thread],[Level],[Logger],[Message]) VALUES (@logDate, @thread, @logLevel, @logger,@message)" /> <!--定义各个参数--> <parameter> <parameterName value="@logDate" /> <dbType value="String" /> <size value="240" /> <layout type="log4net.Layout.PatternLayout"> <conversionPattern value="%date" /> </layout> </parameter> <parameter> <parameterName value="@thread" /> <dbType value="String" /> <size value="240" /> <layout type="log4net.Layout.PatternLayout"> <conversionPattern value="%thread" /> </layout> </parameter> <parameter> <parameterName value="@logLevel" /> <dbType value="String" /> <size value="240" /> <layout type="log4net.Layout.PatternLayout"> <conversionPattern value="%level" /> </layout> </parameter> <parameter> <parameterName value="@logger" /> <dbType value="String" /> <size value="240" /> <layout type="log4net.Layout.PatternLayout"> <conversionPattern value="%logger" /> </layout> </parameter> <parameter> <parameterName value="@message" /> <dbType value="String" /> <size value="240" /> <layout type="log4net.Layout.PatternLayout"> <conversionPattern value="%message" /> </layout> </parameter> </appender> <!--定义日志的输出媒介,下面定义日志以四种方式输出。也可以下面的按照一种类型或其他类型输出。--> <root> <!--文件形式记录日志--> <appender-ref ref="LogFileAppender" /> <!--控制台控制显示日志--> <appender-ref ref="ConsoleAppender" /> <!--Windows事件日志--> <appender-ref ref="EventLogAppender" /> <!-- 如果不启用相应的日志记录,可以通过这种方式注释掉 <appender-ref ref="AdoNetAppender_Access" /> --> </root> </log4net> </configuration> |
程序文件:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
using System; using System.Collections.Generic; using System.Text; using System.Windows.Forms; using System.Reflection; using log4net; //注意下面的语句一定要加上,指定log4net使用.config文件来读取配置信息 //如果是WinForm(假定程序为MyDemo.exe,则需要一个MyDemo.exe.config文件) //如果是WebForm,则从web.config中读取相关信息 [assembly: log4net.Config.XmlConfigurator(Watch = true)] namespace Log4NetDemo { /// <summary> /// 说明:本程序演示如何利用log4net记录程序日志信息。log4net是一个功能著名的开源日志记录组件。 /// 利用log4net可以方便地将日志信息记录到文件、控制台、Windows事件日志和数据库中(包括MS SQL Server, Access, Oracle9i,Oracle8i,DB2,SQLite)。 /// 下面的例子展示了如何利用log4net记录日志 /// 作者:周公 /// 时间:2008-3-26 /// 首发地址:http://blog.csdn.net/zhoufoxcn/archive/2008/03/26/2220533.aspx /// </summary> public class MainClass { public static void Main(string[] args) { //Application.Run(new MainForm()); //创建日志记录组件实例 ILog log = log4net.LogManager.GetLogger(MethodBase.GetCurrentMethod().DeclaringType); //记录错误日志 log.Error("error", new Exception("发生了一个异常")); //记录严重错误 log.Fatal("fatal", new Exception("发生了一个致命错误")); //记录一般信息 log.Info("info"); //记录调试信息 log.Debug("debug"); //记录警告信息 log.Warn("warn"); Console.WriteLine("日志记录完毕。"); Console.Read(); } } } |
全局配置 在AssemblyInfo.cs中添加
|
1 |
[assembly: log4net.Config.XmlConfigurator(ConfigFile = @"Configs\log4net.config", Watch = true)] |
运行结果: 控制台上的输出 日志文件内容 在这里需要特别说明一下,注意上面的代码中有这么一句:[assembly: log4net.Config.XmlConfigurator(Watch = true)](在需要使用log4net的类的namespace处),如果没有这句就会在调试时得到如下留言中所说的“程序调试起来时isDebugEnable"的情况,希望大家注意。 关于未尽之处,请看周公对下面读者的一些问题的答复《Log4Net使用详解(续)》。 from:http://blog.csdn.net/zhoufoxcn/article/details/2220533
View Details
细说ASP.NET Windows身份认证
我谈到了一些关于ASP.NET Forms身份认证方面的话题,这次的博客将主要介绍ASP.NET Windows身份认证。 Forms身份认证虽然使用广泛,不过,如果是在 Windows Active Directory 的环境中使用ASP.NET, 那么使用Windows身份认证也会比较方便。 方便性表现为:我们不用再设计登录页面,不用编写登录验证逻辑。而且使用Windows身份认证会有更好的安全保障。 回到顶部 认识ASP.NET Windows身份认证 要使用Windows身份认证模式,需要在web.config设置:
|
1 |
<authentication mode="Windows" /> |
Windows身份认证做为ASP.NET的默认认证方式,与Forms身份认证在许多基础方面是一样的。 上篇博客我说过:我认为ASP.NET的身份认证的最核心部分其实就是HttpContext.User这个属性所指向的对象。 在接下来的部分,我将着重分析这个对象在二种身份认证中有什么差别。 在ASP.NET身份认证过程中,IPrincipal和IIdentity这二个接口有着非常重要的作用。 前者定义用户对象的基本功能,后者定义标识对象的基本功能, 不同的身份认证方式得到的这二个接口的实例也是不同的。 ASP.NET Windows身份认证是由WindowsAuthenticationModule实现的。 WindowsAuthenticationModule在ASP.NET管线的AuthenticateRequest事件中, 使用从IIS传递到ASP.NET的Windows访问令牌(Token)创建一个WindowsIdentity对象,Token通过调用context.WorkerRequest.GetUserToken()获得, 然后再根据WindowsIdentity 对象创建WindowsPrincipal对象, 然后把它赋值给HttpContext.User。 在Forms身份认证中,我们需要创建登录页面,让用户提交用户名和密码,然后检查用户名和密码的正确性, 接下来创建一个包含FormsAuthenticationTicket对象的登录Cookie供后续请求使用。 FormsAuthenticationModule在ASP.NET管线的AuthenticateRequest事件中, 解析登录Cookie并创建一个包含FormsIdentity的GenericPrincipal对象, 然后把它赋值给HttpContext.User。 上面二段话简单了概括了二种身份认证方式的工作方式。 我们可以发现它们存在以下差别: 1. Forms身份认证需要Cookie表示登录状态,Windows身份认证则依赖于IIS 2. Windows身份认证不需要我们设计登录页面,不用编写登录验证逻辑,因此更容易使用。 在授权阶段,UrlAuthorizationModule仍然会根据当前用户检查将要访问的资源是否得到许可。 接下来,FileAuthorizationModule检查 HttpContext.User.Identity 属性中的 IIdentity 对象是否是 WindowsIdentity 类的一个实例。 如果 IIdentity 对象不是 WindowsIdentity 类的一个实例,则 FileAuthorizationModule 类停止处理。 如果存在 WindowsIdentity 类的一个实例,则 FileAuthorizationModule 类调用 AccessCheck Win32 函数(通过 P/Invoke) 来确定是否授权经过身份验证的客户端访问请求的文件。 如果该文件的安全描述符的随机访问控制列表 (DACL) 中至少包含一个 Read 访问控制项 (ACE),则允许该请求继续。 否则,FileAuthorizationModule 类调用 HttpApplication.CompleteRequest 方法并将状态码 401 返回到客户端。 在Windows身份认证中,验证工作主要是由IIS实现的,WindowsAuthenticationModule其实只是负责创建WindowsPrincipal和WindowsIdentity而已。 顺便介绍一下:Windows 身份验证又分为“NTLM 身份验证”和“Kerberos v5 身份验证”二种, 关于这二种Windows身份认证的更多说明可查看MSDN技术文章:解释:ASP.NET 2.0 中的 Windows 身份验证。 在我看来,IIS最终使用哪种Windows身份认证方式并不影响我们的开发过程,因此本文不会讨论这个话题。 根据我的实际经验来看,使用Windows身份认证时,主要的开发工作将是根据登录名从Active Directory获取用户信息。 […]
View Details用Stopwatch显示执行时间
.net自带有性能分析功能,其中的代码段执行时间就是一个比较好用的方法,首先引入命名空间: using System.Diagnostics; //在代码开始计时 Stopwatch sw = new Stopwatch(); //实例化一个对象 sw.Start(); //开始计算 //要执行的代码 //如果有多段需要计时,也可以用sw.Reset(); 再次初始化时间戳 //sw.Start(); 重新开始计时 sw.Stop(); //计算结束 sw.ElapsedMilliseconds就是耗费的时间,单位是毫秒。
View DetailsASP.NET缓存全解析7:第三方分布式缓存解决方案 Memcached和Cacheman
Memcached — 分布式缓存系统 1.Memcached是什么? Memcached是高性能的,分布式的内存对象缓存系统,用于在动态应用中减少数据库负载,提升访问速度。Memcached通过在内存里维护一个统一的巨大的hash表,它能够用来存储各种格式的数据,包括图像、视频、文件以及数据库检索的结果等。Memcached由Danga Interactive最初为了加速 LiveJournal网站访问速度而开发的,后来被很多大型的网站采用。起初作者编写它可能是为了提高动态网页应用,为了减轻数据库检索的压力,来做的这个缓存系统。它的缓存是一种分布式的,也就是可以允许不同主机上的多个用户同时访问这个缓存系统,这种方法不仅解决了共享内存只能是单机的弊端, 同时也解决了数据库检索的压力,最大的优点是提高了访问获取数据的速度!基于memcached作者对分布式cache的理解和解决方案。memcached完全可以用到其他地方 比如分布式数据库,分布式计算等领域。Memcached将数据库负载大幅度降低,更好的分配资源,更快速访问。 2.Memcached工作机制 通过在内存中开辟一块区域来维持一个大的hash表来加快页面访问速度,和数据库是独立的。但是目前主要用来缓存数据库的数据。允许多个server通过网络形成一个大的hash,用户不必关心数据存放在哪,只调用相关接口就可。存放在内存的数据通过LRU算法进行淘汰出内存。同时可以通过删除和设置失效时间来淘汰存放在内存的数据。 现在一些.NET开发人员开始放弃ASP.NET内置的缓存机制,转而使用Memcached——一种分布式的内存缓存系统。当运行在单独的Web服务器上,你可以很容易地清除一个已经确认被改变了的缓存。可惜,ASP.NET没有一个很好的方法来支持多服务器。每个服务器上的缓存都对其他缓存的改变一无所知。 ASP.NET允许通过基于文件系统和数据库表的触发器来作废一个缓存。然而,这也存在问题,比如数据库触发器需要使用昂贵的轮询,以及触发器本身冗长的编程。但是,我们还是有其他的选择的。 不像ASP.NET内置的缓存机制,Memcached是一个分布式的缓存系统。任何Web服务器都能更新或删除一个缓存项,并且所有其他的服务器都能在下次访问这些缓存项的时候自动获取到更新的内容。这是通过把这些缓存项存储在一个或者多个缓存服务器上来实现的。每一个缓存项都根据它的关键字的哈希值来分配到一个服务器上。 表面看来,Memcached针对ASP.NET的API就像和内置的API一样。这让开发人员很容易地转换到Memcached上,仅仅通过在代码中查找和替换即可实现。 一个被推荐的解决方案是不根据缓存项的关键字来生成哈希键值。这将允许开发人员能够让一个给定页面中需要的所有缓存项,尽量存放在同一个服务器上。可惜,基于数据保存的地方而不是基于缓存项自身的关键字来生成哈希键,很容易产生错误,需要仔细来实现(这个算法)。 Memcached是基于Linux运行的,你可以在BSD的许可协议下使用Memcached。他也提供了针对C#的客户端以及Perl、Python、PHP、Java和其他语言的API:http://www.danga.com/memcached/apis.bml。还有一个Win32的移植版本(http://jehiah.cz/projects/memcached-win32/),可以让Memcached运行在非Linux的机器上。 Cacheman — .NET架构下的分布式缓存项目 Cacheman据说是由微软旗下的 Popfly 项目组成员 Sriram Krishnan 的作品。是他用业余时间开发的。最新的情况是,微软的 Popfly 网站已经“悄悄地”的做了更新,就是采用了 Krishnan 的 Cacheman,更新了缓存机制。该项缓存技术更新带来的性能提升非常显著,根据Popfly团队中的 John Montgomery 的说法:加载一个已有的Mashup应用时,可以带来2到6倍的性能提升。 这些说法也得到了 Krishnan 本人的确认。他提到这是Cacheman 的第一次的实际应用,并自豪的说 Cacheman 不费吹灰之力就拿下了 Popfly 的全部访问量。 简单介绍一下 Cacheman 这个项目。资料主要来源于 Krishnan的博客对Cacheman的介绍。 Cacheman是一个基于Windows平台的快速分布式哈希表。是由纯托管代码实现。中间搁置了有几个月,直到最近才开始重新上马这个项目,极可能就是因为Popfly项目需要的缘故才开始着手的。 Krishnan本人对 memcached 很感兴趣,于是创建了 Cacheman。Cacheman上有很多 memcached 的影子,比如与memcached相似的文本通讯协议。Cacheman的通讯协议公开,任何人可以根据自己偏爱的语言环境写客户端。 Krishnan 在自己家用电脑(2.4GHz Intel Core 2 带2GB内存)上进入测试,达到了每秒16000次左右的请求,并且还是服务器与客户端都是在同一台服务器下完成的。 现这款产品还不太完善,作者自身也提到:在Cacheman做指定key的GET/SET/DELETE操作时,客户端需要弄清需要与哪一台Cacheman服务器通讯,为此要对该key做一个快速FNV哈希然后求余得到应该和几台服务器中的哪台服务器通讯。但该法的缺点在于新增或删除一个服务器节点时,缓存节点需要大规模迁移。修复该问题需要一致性的哈希算法,作者表示还没有时间解决此事。作者提出了采用中心架构的“主缓存服务器”的解决办法,让客户端轮询主缓存服务器来获取应该与那个缓存服务器通讯,但他也觉的这样做增加了复杂性,会带来些新问题。 可以感觉到,由于 Cacheman 这个个人项目已经介入到 Popfly 这个正式产品中,可能很快就会被微软吸纳为正式产品,因此如果有人采用这个产品做自己缓存的解决方案的话,应该不必太担心后续的产品升级及文档支持服务,它的未来前途值的期待。说不定 Krishnan 会从 Popfly 项目脱身出来专职负责这个 Cacheman 项目。 目前最新的版本是0.0.2版 :http://www.sriramkrishnan.com/code/。 from:http://kb.cnblogs.com/page/69728/
View DetailsASP.NET缓存全解析3:页面局部缓存
有时缓存整个页面是不现实的,因为页的某些部分可能在每次请求时都需要变化。在这些情况下,只能缓存页的一部分。顾名思义,页面部分缓存是将页面部分内容保存在内存中以便响应用户请求,而页面其他部分内容则为动态内容。页面部分缓存的实现包括两种方式:控件缓存和替换后缓存。 1. 控件缓存(也称为片段缓存) 这种方式允许将需要缓存的信息包含在一个用户控件内,然后,将该用户控件标记为可缓存的,以此来缓存页面输出的部分内容。该选项允许缓存页面中的特定内容,而没有缓存整个页面,因此,每次都需重新创建整个页。例如,如果要创建一个显示大量动态内容(如股票信息)的页,其中有些部分为静态内容(如每周总结),这时可以将静态部分放在用户控件中,并允许缓存这些内容。 在ASP.NET中,提供了UserControl这种用户控件的功能。一个页面可以通过多个UserControl来组成。只需要在某个或某几个UserControl里设置缓存。 例如: 那么可以在WebUserControl1.ascx的页头代码中添加声明语句: <%@ Control Language="C#" AutoEventWireup="true" CodeBehind="WebUserControl1.ascx.cs" Inherits="CacheWebApp._16_4_5.WebUserControl1" %> <%@ OutputCache Duration="60" VaryByParam="none" %> <%=DateTime.Now %> 调用该控件的页面WebForm1.aspx代码: <%@ Page Language="C#" AutoEventWireup="true" CodeBehind="WebForm1.aspx.cs" Inherits="CacheWebApp._16_4_5.WebForm1" %> <%@ Register src="WebUserControl1.ascx" tagname="WebUserControl1" tagprefix="uc1" %> <html xmlns="http://www.w3.org/1999/xhtml" > <head runat="server"> <title>控件缓存</title> </head> <body> <form id="form1" runat="server"> <div> 页面的:<%=DateTime.Now %> </div> <div> 控件的:<uc1:WebUserControl1 ID="WebUserControl11" runat="server" /> </div> </form> </body> </html> 这时候刷新WebForm1.aspx页面时,页面的时间每次刷新都变化,而用户控件中的时间数据却是60秒才变化一次,说明对页面的“局部”控件实现了缓存,而整个页面不受影响。 2. 缓存后替换 与控件缓存正好相反。它对整个页面进行缓存,但是页中的某些片段是动态的,因此不会缓存这些片段。ASP.NET页面中既包含静态内容,又包含基于数据库数据的动态内容。静态内容通常不会发生变化。因此,对静态内容实现数据缓存是非常必要的。然而,那些基于数据的动态内容,则不同。数据库中的数据可能每时每刻都发生变化,因此,如果对动态内容也实现缓存,可能造成数据不能及时更新的问题。对此问题如果使用前文所述的控件缓存方法,显然不切实际,而且实现起来很繁琐,易于发生错误。 如何实现缓存页面的大部分内容,而不缓存页面中的局部某些片段。ASP.NET 2.0提供了缓存后替换功能。实现该项功能可通过以下三种方法: 一是以声明方式使用Substitution控件。 二是以编程方式使用Substitution控件API。 三是以隐式方式使用控件。 前两种方法的核心是Substitution控件,本节将重点介绍该控件,第三种方法仅专注于控件内置支持的缓存后替换功能,本节仅做简要说明。 (1) Substitution控件应用 为提高应用程序性能,可能会缓存整个ASP.NET页面,同时,可能需要根据每个请求来更新页面上特定的部分。例如,可能要缓存页面的很大一部分,需要动态更新该页上与时间或者用户高度相关的信息。在这种情况下,推荐使用Substitution控件。Substitution控件能够指定页面输出缓存中需要以动态内容替换该控件的部分,即允许对整页面进行输出缓存,然后,使用Substitution控件指定页中免于缓存的部分。需要缓存的区域只执行一次,然后从缓存读取,直至该缓存项到期或被清除。动态区域,也就是Substitution控件指定的部分,在每次请求页面时都执行。Substitution控件提供了一种缓存部分页面的简化解决方案。 <%@ Page Language="C#" AutoEventWireup="true" CodeBehind="WebForm2.aspx.cs" Inherits="CacheWebApp._16_4_5.WebForm2" %> <%@ OutputCache Duration="60" VaryByParam="none" %> <html xmlns="http://www.w3.org/1999/xhtml" > <head […]
View Details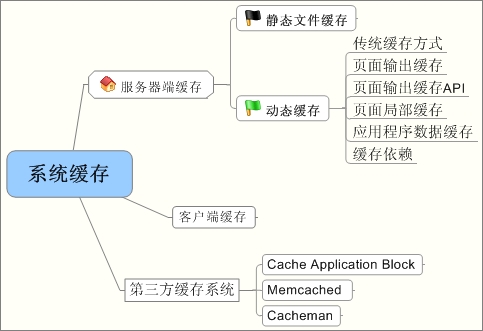
ASP.NET缓存全解析1:缓存的概述
有时候总听到网友说网站运行好慢,不知如何是好;有时候也总见到一些朋友写的网站功能看起来非常好,但访问性能却极其的差。没有“勤俭节约”的意识,势必会造成“铺张浪费”。如何应对这种情况,充分利用系统缓存则是首要之道。 系统缓存有什么好处呢?举个简单的例子,你想通过网页查询某些数据,而这些数据并非实时变化,或者变化的时间是有期限的。例如查询一些历史数据。那么每个用户每次查的数据都是一样的。如果不设置缓存,ASP.NET也会根据每个用户的请求重复查询n次,这就增加了不必要的开销。所以,可能的情况下尽量使用缓存,从内存中返回数据的速度始终比去数据库查的速度快,因而可以大大提供应用程序的性能。毕竟现在内存非常便宜,用空间换取时间效率应该是非常划算的。尤其是对耗时比较长的、需要建立网络链接的数据库查询操作等。 缓存功能是大型网站设计一个很重要的部分。由数据库驱动的Web应用程序,如果需要改善其性能,最好的方法是使用缓存功能。 缓存的分类 从分布上来看,我们可以概括为客户端缓存和服务器端缓存。 客户端缓存——这点大家都有直观的印象。比如你去一个新的网站,第一次可能要花一阵子时间才能载入整个页面。而以后再去呢,时间就会大大的缩短,原因就在于这个客户端缓存。现在的浏览器都比较智能,它会在客户机器的硬盘上保留许多静态的文件,比如各种gif,jpeg文件等等。等以后再去的时候,它会尽量使用本地缓存里面的文件。只有服务器端的文件更新了,或是缓存里面的文件过期了,它才会再次从服务器端下载这些东西。很多时候是IE替我们做了这件事情。 服务器端缓存——有些东西没法或是不宜在客户端缓存,那么我们只好在服务器端想想办法了。服务器端缓存从性质上看,又可以分为两种。 (1)、静态文件缓存 好多页面是静态的,很少改动,那么这种文件最适于作静态缓存。现在的IIS 6.0这部分内容是直接存放在Kernel的内存中,由HTTP.SYS直接管理。由于它在Kernel Space,所以它的性能非常的高。用户的请求如果在缓存里面,那么HTTP.SYS直接将内容发送到network driver上去,不需要像以前那样从IIS的User space的内存copy到Kernel中,然后再发送到TCP/IP stack上。Kernel level cache几乎是现在高性能Web server的一个必不可少的特性。 (2)、动态缓存 动态缓存是比较有难度的。因为你在缓存的时候要时刻注意一个问题,那就是缓存的内容是不是已经过时了。因为内容过时了可能会有很严重的后果。比如网上买卖股票的网站。你给别人提供的价格是过时的,那人家非砍了你不可。缓存如何发现自己是不是过时就是一个非常复杂的问题。 在ASP.NET中,常见的动态缓存主要有以下几种手段: Ø 传统缓存方式 Ø 页面输出缓存。 Ø 页面局部缓存。 Ø 利用.NET提供的System.Web.Caching 缓存。 Ø 缓存依赖。 传统缓存方式 比如将可重复利用的东西放到Application或是Session中去保存。 Session["Style"] = val; Application["Count"] = 0; from:http://kb.cnblogs.com/page/69483/
View DetailsASP.NET缓存全解析2:页面输出缓存
页面输出缓存是最为简单的缓存机制,该机制将整个ASP.NET页面内容保存在服务器内存中。当用户请求该页面时,系统从内存中输出相关数据,直到缓存数据过期。在这个过程中,缓存内容直接发送给用户,而不必再次经过页面处理生命周期。通常情况下,页面输出缓存对于那些包含不需要经常修改内容的,但需要大量处理才能编译完成的页面特别有用。需要读者注意的是,页面输出缓存是将页面全部内容都保存在内存中,并用于完成客户端请求。 在ASP.NET中页面缓存的使用方法非常的简单,只需要在aspx页的顶部加这样一句声明即可: <%@ OutputCache Duration="60" VaryByParam="none" %> Duration:缓存的时间(秒),这是必选属性。如果未包含该属性,将出现分析器错误。 <%@ Page Language="C#" AutoEventWireup="true" CodeBehind="WebForm1.aspx.cs" Inherits="CacheWebApp._16_4_3.WebForm1" %> <%@ OutputCache Duration="60" VaryByParam="none" %> <html xmlns="http://www.w3.org/1999/xhtml" > <head runat="server"> <title>页面缓存示例</title> </head> <body> <form id="form1" runat="server"> <div> <asp:Label ID="Label1" runat="server" Text="Label"></asp:Label> </div> </form> </body> </html> 后台代码: protected void Page_Load(object sender, EventArgs e) { if (!IsPostBack) { Label1.Text = DateTime.Now.ToString(); } } 如果不加<%@ OutputCache Duration="60" VaryByParam="none" %>,每次刷新页面上的时间每次都是在变。而加了缓存声明以后,每次刷新页面的时间并不变化,60秒后才变化一次,说明数据被缓存了60秒。 VaryByParam:是指页面根据使用 POST 或 GET 发送的名称/值对(参数)来更新缓存的内容,多个参数用分号隔开。如果不希望根据任何参数来改变缓存内容,请将值设置为 none。如果希望通过所有的参数值改变都更新缓存,请将属性设置为星号 (*)。 例如: http://localhost:1165/16-4-3/WebForm1.aspx?p=1 则可以在WebForm1.aspx页面头部声明缓存:<%@ OutputCache Duration="60" VaryByParam="p" %> 以上代码设置页面缓存时间是60秒,并根据p参数的值来更新缓存,即p的值发生变化才更新缓存。 如果一直是WebForm1.aspx?p=1访问该页,则页面会缓存当前数据,当p=2时又会执行后台代码更新缓存内容。 如果有多个参数时,如:http://localhost:1165/16-4-3/WebForm1.aspx?p=1&n=1 可以这样声明:<%@ OutputCache Duration="60" VaryByParam="p;n" %> 除此之外,@OutputCache 还有一些其他的属性。@OutputCache指令中的属性参数描述如下: <%@ OutputCache […]
View DetailsASP.NET如何获取来访者的IP、OS、浏览器及系统语言
try { string userAgent = Request.UserAgent == null ? "无" : Request.UserAgent; LblOS.Text=this.GetOSNameByUserAgent(userAgent);——通过下面的代码来获得用户的OS类型 LblIP.Text = Request.UserHostAddress; //获取IP LblBrs.Text = Request.Browser.Browser + Request.Browser.Version; //获取浏览器的类型及版本号 LblLanguage.Text = Request.UserLanguages[0]; //获取用户操作系统的语言 } catch (Exception ex) { Response.Write(ex.Message); } FROM:http://www.cnblogs.com/zhukezhuke/archive/2010/07/10/1774735.html
View Details