Category Archives: Backend
细说ASP.NET Windows身份认证
我谈到了一些关于ASP.NET Forms身份认证方面的话题,这次的博客将主要介绍ASP.NET Windows身份认证。 Forms身份认证虽然使用广泛,不过,如果是在 Windows Active Directory 的环境中使用ASP.NET, 那么使用Windows身份认证也会比较方便。 方便性表现为:我们不用再设计登录页面,不用编写登录验证逻辑。而且使用Windows身份认证会有更好的安全保障。 回到顶部 认识ASP.NET Windows身份认证 要使用Windows身份认证模式,需要在web.config设置:
|
1 |
<authentication mode="Windows" /> |
Windows身份认证做为ASP.NET的默认认证方式,与Forms身份认证在许多基础方面是一样的。 上篇博客我说过:我认为ASP.NET的身份认证的最核心部分其实就是HttpContext.User这个属性所指向的对象。 在接下来的部分,我将着重分析这个对象在二种身份认证中有什么差别。 在ASP.NET身份认证过程中,IPrincipal和IIdentity这二个接口有着非常重要的作用。 前者定义用户对象的基本功能,后者定义标识对象的基本功能, 不同的身份认证方式得到的这二个接口的实例也是不同的。 ASP.NET Windows身份认证是由WindowsAuthenticationModule实现的。 WindowsAuthenticationModule在ASP.NET管线的AuthenticateRequest事件中, 使用从IIS传递到ASP.NET的Windows访问令牌(Token)创建一个WindowsIdentity对象,Token通过调用context.WorkerRequest.GetUserToken()获得, 然后再根据WindowsIdentity 对象创建WindowsPrincipal对象, 然后把它赋值给HttpContext.User。 在Forms身份认证中,我们需要创建登录页面,让用户提交用户名和密码,然后检查用户名和密码的正确性, 接下来创建一个包含FormsAuthenticationTicket对象的登录Cookie供后续请求使用。 FormsAuthenticationModule在ASP.NET管线的AuthenticateRequest事件中, 解析登录Cookie并创建一个包含FormsIdentity的GenericPrincipal对象, 然后把它赋值给HttpContext.User。 上面二段话简单了概括了二种身份认证方式的工作方式。 我们可以发现它们存在以下差别: 1. Forms身份认证需要Cookie表示登录状态,Windows身份认证则依赖于IIS 2. Windows身份认证不需要我们设计登录页面,不用编写登录验证逻辑,因此更容易使用。 在授权阶段,UrlAuthorizationModule仍然会根据当前用户检查将要访问的资源是否得到许可。 接下来,FileAuthorizationModule检查 HttpContext.User.Identity 属性中的 IIdentity 对象是否是 WindowsIdentity 类的一个实例。 如果 IIdentity 对象不是 WindowsIdentity 类的一个实例,则 FileAuthorizationModule 类停止处理。 如果存在 WindowsIdentity 类的一个实例,则 FileAuthorizationModule 类调用 AccessCheck Win32 函数(通过 P/Invoke) 来确定是否授权经过身份验证的客户端访问请求的文件。 如果该文件的安全描述符的随机访问控制列表 (DACL) 中至少包含一个 Read 访问控制项 (ACE),则允许该请求继续。 否则,FileAuthorizationModule 类调用 HttpApplication.CompleteRequest 方法并将状态码 401 返回到客户端。 在Windows身份认证中,验证工作主要是由IIS实现的,WindowsAuthenticationModule其实只是负责创建WindowsPrincipal和WindowsIdentity而已。 顺便介绍一下:Windows 身份验证又分为“NTLM 身份验证”和“Kerberos v5 身份验证”二种, 关于这二种Windows身份认证的更多说明可查看MSDN技术文章:解释:ASP.NET 2.0 中的 Windows 身份验证。 在我看来,IIS最终使用哪种Windows身份认证方式并不影响我们的开发过程,因此本文不会讨论这个话题。 根据我的实际经验来看,使用Windows身份认证时,主要的开发工作将是根据登录名从Active Directory获取用户信息。 […]
View Details
12 个最好的免费网站速度和性能测试工具
如果你是位个人站长,就能理解网站速度的重要性。自从 Google 算法开始使用网页加载时间作为搜索排序参数之后,网站速度对 SEO 的影响非常大。而且,很慢的加载速度会对网站访问者产生消极的影响。如果你的网站加载速度很慢,需要等待一段时间才能加载,那么用户很有可能不会再次访问 这个网站。 所以,为了解决以上说到的问题,我们收集整理了一个最好的免费网站速度测试和分析工具列表。接下来介绍的工具都是免费,而且会提供非常详细的数据报告给用户,帮助用户做些必要的补救措施。希望大家都能在下面的列表中找到对自己有帮助的,使自己的网站访问速度越来越快! 1. Google PageSpeed Insights Google PageSpeed Insights 允许用户分析网站页面的内容,并且会提供加快网站访问速度的建议。 2. GT Matrix GTmetrix 可以帮助用户开发一个快速,高效,能全面改善用户体验的网站。它会为网站性能打分,然后提供可行性的建议来改善已发现的问题。 3. Neustar Free Load Testing & Performance Test neustar 这个工具是个简单快速生成网站性能分析数据的工具。它能忽略掉大小和地理位置来检测和负载测试网站,非常容易得出网站的性能分析,帮助用户加快网站加载速度。 4. Web Page Analyzer Web Page Analyzer 是个非常强大的速度测试工具,提供详细的网站分析数据并且会提供提高网站性能的建议。它提供大量的 web 页面速度报告,global report,外部文件计算,加载时间,网站分析数据和改善建议。 5. Pingdom Pingdom 是个非常杰出的工具,帮助用户生成大量网站的报告(页面大小,浏览器缓存,性能等级等),确定网站的加载时间,而且允许用户跟踪性能的历史记录,能在不同位置进行网站测试。 6. Load Impact Load Impact 允许用户做些 web 应用的负载和性能测试。它不断增加网站流量来测量网站性能。Load Impact 会选择一个全球负载区,测试模拟客户,带宽,接收数据和每秒请求等。越来越多客户变活跃,这个工具会用个漂亮的图表来展示测量的加载时间。 7. WebPage Test 用户可以使用 WebPage Test 来进行简单的测试,又或者是进行高级的测试,比如多步事物处理,视频采集,内容屏蔽等。测试结果会提供丰富的诊断信息,包括资源加载瀑布图表,页面速度优化检测和改善建议等。 8. Octa Gate Site Timer Octa Gate Site Timer 工具允许用户检测每个用户加载一个或多个页面的时间。当页面加载的时候,SiteTimer 存储每个项目加载的数据和用户接收的数据,这些数据会用一个网格来显示。 9. Which Loads Faster Which Loads Faster 是用来测试 web 性能问题的工具,可以在每个用户的浏览器测试。whichloadsfaster 是开源的,使用 HTML 和 JavaScript 编写的测试工具,完全在客户端运行。 10. Yslow YSlow 能分析 web 页面,基于一系列 web 页面高性能规则提供改进网页性能的建议。 11. Show Slow […]
View Details用Stopwatch显示执行时间
.net自带有性能分析功能,其中的代码段执行时间就是一个比较好用的方法,首先引入命名空间: using System.Diagnostics; //在代码开始计时 Stopwatch sw = new Stopwatch(); //实例化一个对象 sw.Start(); //开始计算 //要执行的代码 //如果有多段需要计时,也可以用sw.Reset(); 再次初始化时间戳 //sw.Start(); 重新开始计时 sw.Stop(); //计算结束 sw.ElapsedMilliseconds就是耗费的时间,单位是毫秒。
View Details
程序员的回归式进化
头一年 第二年 第三年 第五年 第十年 [英文原文:The Evolution of a Software Engineer ] from:http://www.oschina.net/news/50011/the-evolution-of-a-software-engineer
View Details
编程语言拟人化:Java、C++、Python、Ruby、PHP、C#、JS
Java 犹如宫泽贤治的《不畏风雨》中出现的、性格木讷的女孩子。从小就由于迟钝和大食量等特征被别人当作笨蛋,从小学入学开始进入田径部、坚持跑步,在中长跑中经常取得好成绩,给人以活泼的印象。是十分努力的女孩子。 她的家境并不算好。父亲Sun是有才能的艺术家,但不擅长理财,在她14岁的时候因为苦于借债积劳成疾而去世。她被Oracle叔叔收养,那时还与Google叔叔之间因为对她的扶养权问题而引起争端并闹上法庭。 在周围的人都担心,正值青春期时她在这样的处境下会不会一蹶不振的时候,她却处变不惊、继续着每天练习跑步的生活。 朴素的、认真的、难说是聪明的她,进入高中后不知是不是稍稍开始对异情在意,被人看到她偷偷地学着别的女孩子的时尚穿着在街上行走。虽然会受到“虽然很努力,也许稍微有点过时”、“那衣服与Java的印象不合”之类的否定评价,但感到“意外地很萌?”的好意的人也很多。 喜欢喝咖啡,只喝印度尼西亚产的。其本人曾说过“喜欢咖啡胜过三顿饭”,不禁让人稍稍担心“这样对健康没问题吗?” C++ 苗条的双腿和协调的五官。被许多人称作“IT界首屈一指的美女”的她,也因为拥有插花、茶道、钢琴和小提琴、柔道、剑道、合气道等等才能而出名。 她的粉丝大多很狂热,还存在着“黑暗军团”这样的粉丝俱乐部。黑暗军团的是规模仅次于共济会(Freemason)的巨型团体,一般人无法入会。据说如果能回答出对她非常狂热的问题,就会有察觉到的军团成员来询问“你愿意进入黑暗军团吗?” 与她同父异母的姐妹Objective-C一心专注于弹钢琴,她的专注被IT界的天才史蒂夫乔布斯(也被一部分人称为紫色蔷薇)相中,而一跃成为明星,而C++则是由于其美貌和才能被人关注,长年坐稳业界明星的宝座。姐妹二人真可谓是对比鲜明。 她根据心情不同频繁地变换发型和服装这一点也很出名。昨天还是和服配黑发,今天却是红发哥特系登场之类的,因为她的变身而使轻度的粉丝惊奇道“啊嘞?今天是C++小姐吗?”的事也常有发生。远离业界时私下经常穿HYSTERIC GLAMOUR的服装。 关于她的出身年月日其事务所并不公开。虽然也有出身于1983年一说,本文采用的是在一部分粉丝中流传甚广的1985年10月14日说。其间也流传 有“她自己也许也记不清自己的生日……”这样煞有介事的传言。与其说“C++小姐的话记不清自己的生日也不是什么不可思议的事情”,倒不如看作是她天真烂 漫的性格的表现。 Python 由Guido父上养大的深闺中的大小姐。她出身于荷兰的阿姆斯特丹,但在小时候就搬到了美国,父亲也在家里使用英语,所以不怎么会说荷兰语。 她个性随和。最出名的是她听C++宣布“想出去旅行一趟改变一下形象。200x年回来哦”出门旅行后(结果回来的时候已经2011年了……),放言说“我也稍稍出门旅行一下,公元3000年再回来哦”后出门数年未归。 虽然有着这样冒失的行动,但多亏抱着“养成大家都喜爱的孩子”的心愿的Guido父上大人的教育,实际上和她接触后会觉得她非常容易亲近。 前些天,她来到作者的朋友的公司打工(她现在似乎在边上大学边打工),被人们评价为“能充分融入工作、八面玲珑、给我们帮了大忙”。她不怎么说多余的话,彬彬有礼的样子,被评价为是在“天真烂漫、自由第一”的人众多的业界中与众不同的存在。 据说她擅长的科目是数学,经常看到她轻松地解决各种统计相关的难题。喜欢穿白色的连衣裙或浅粉色的开衫这样清新的服装。 实际上她还喜欢爬行动物,据说在家里还有养蛇。粉丝们经常讨论“她会给宠物们起什么样的名字呢?”这样的话题。大多得出的都是“肯定是Monty 吧”这样的结论。会不会飞就不得而知了。(估计指的是英国的六人喜剧团体Monty Python的作品The Flying Circus,译者注) Ruby 由松本爸爸养大的日本的女孩子。因为生日在圣诞节,人生最大的烦恼是生日礼物和圣诞节礼物变成一份了。出生地是岛根县松江市,除了旅游和工作以外没有到过其它的县。 由于受的教育是自由奔放式的,她性格好动、好奇心旺盛。平时是一个率真的好孩子,但偶尔也会看到她喜欢恶作剧的一面,这让周围的人十分困扰。看到她的身影时经常会想起IT业的“Just For Fun !”这句话。 小时候过着一个人在荒山野岭到处跑的生活,10岁的时候与一个叫Rails的女孩成为朋友,生活开始变化。两个人玩耍时停在了演艺事务所门前,谈起 可以两个人结对进行演艺活动。以“Ruby与Rails”的艺名出道、主要从事杂志模特,也有拍过电视广告,所以很多人都听过她们名字。 人们想着她在这多愁善感的年龄段体验各种演艺活动、性格多少会产生一些变化吧,但在前些天与她久违的谈话中,却惊讶地发现她仍是与从事演艺活动之前一样行动自由奔放。虽然行为举止多多少少显得更加稳重,其喜欢恶作剧、活泼的本性却和以前一样没有变化。 想着已经是高中生了差不多也要开始穿一些成熟一点的服装的她,对于洋装却和小时候一样穿着Mickey Mouse。虽然她个子小又是娃娃脸与这样的衣服很配,不过这样真像一个女高中生吗? 她的粉丝也分为想要她一直保持现在的样子,和想要看到她更成熟的样子的两派。 PHP 以强化Web世界为目的制作出来的女性机器人。竖着的头发是用作天线来随时接收主人的命令的。 为了有与人类相近的触感,使用了硅树脂来制作其皮肤。内部是类似于刀片服务器的构造,常常使用多台服务器进行复用。因此体重比人类更重一些。 在她最初登场的时候,还能看到她关节可动部分的骨架,行动也很僵硬,与人类的形象差别很大。然而经过了18年间6次的大版本升级之后,其行为和言语已经渐渐变得像人了。最近更是达到了像初音未来这样(比起人类仍然有少许违和感但已经十分自然了)的级别。 虽然笨笨的、工作时也磕磕绊绊的,但由于她遵循机器人三原则、服从主人的命令,也有很多人成为她的粉丝。她的粉丝俱乐部官网“PHPer!”无需入会费便可简单入会,是会员数在IT界首屈一指的大团体。 对于她持拒绝态度的人也很多,常有“她的行为在生理上有些难以接受”、“如果再聪明点就好了”、“与她稍有过接触但觉得还是与人类差别很大”这样的评论。 平常穿从Forever12和志村买来的衣服。想着穿便宜的快速时尚(fast fashion)衣服便可以将省下的钱花在机器开销上。可以说是标准的机器人的效率优先的花钱方式。或许会有她也在意流行、为样子烦恼的那一天吧? C# 在著名的微软公司接受精英教育、11岁时便跳级进入大学学习、倍受人们关注的少女。也被称为“IT界的最强幼女”。 因为与C++的名字很像,一段时间内盛传“难道是私生子吗?”的流言,实际上两人没有直接的血缘关系。也有报道称两人是远房亲戚,但实际情况如何则不得而知。 似乎喜欢成熟的行为、讨厌像小孩子一样玩耍。有生日的时候收到父母送的名为安迪的毛绒玩具时说道“这是啥。没sense。不要”的传闻。 然而对于食物的兴趣却仍停留在小孩的阶段,多次目击到她在学校食堂点儿童套餐的样子。不喜欢喝咖啡,就算是甜味的罐装咖啡也会令她皱眉头。 虽然偶尔会见到她意外地孩子气的一面,多数情况下见到的还是她说话、待人接物彬彬有礼的样子。是一个既有成熟的一面又有稚气的一面的孩子。由于还在成长期,见到她时常有“又长高了啊”、“有些像大人的样子了”这样的感慨。一直会期待着下见到她时会长成什么样子。 常穿秀兰邓波的洋装。据说都是她本人挑选的,与她自己非常相配。她的可爱让人们无论男女都会成为她的粉丝。 她的志向是在大学毕业后不仅在养育她生长的微软公司的旗下工作、还要活跃于整个IT界。虽然没有问到更详细的计划,但据说是要做出能让苹果和企鹅等也能和睦相处的东西。到底会做出怎样的东西来呢? JavaScript 在争议地区长大的17岁的女孩子。常常面无表情、谈话时总给人以一定的距离感。 虽然与Java的名字很像,两个人之间却没有血缘关系。在当时Java这样的名字很流行,所以父母也给她起了类似的名字。她本人似乎对自己的名字并不在意,有时也以“ECMA”的笔名进行活动。偶尔也会被叫“JS”的外号,对此则更不在意,甚至对这种称法公然无视。 她的生涯非常不幸。刚一出生祖国便爆发战争。懂事之前便母亲去世、离开了父亲。在大人们任性的争斗中,她学会了将自己藏在壳中、保护自己周围的生存 之术。同年龄的女孩子随着年龄的变化都在挑战各种风格的时候,她却不顾周围的话语、一个人继续闭锁在壳中。当时就是非得这样才能生存的艰难环境。 由于有了这样的儿童时期,她的说话、思考、待人接物的方式与其它的孩子都稍显不同。有很多人在与她说话时都会烦恼该怎样说才好。不过,也有人对她持有简单的一根筋的思考方式“容易接触”、“某种程度上来说,很好理解”的印象。 现在,她的国家正向努力解决纷争、开拓新的居住土地的方向前进着。大人们虽然仍旧任性地互相斗争,至少在这几年里,已经没有发生像以前那样互相憎恨、互相残杀的战争了。 在开始复兴的祖国里,她如今应该能幸福地生活着吧?什么时候才能看到她像同龄的女孩一样欢笑呢? 原文链接: rikunabi 翻译: 伯乐在线 – 団子 译文链接: http://blog.jobbole.com/63311/
View DetailsASP.NET缓存全解析7:第三方分布式缓存解决方案 Memcached和Cacheman
Memcached — 分布式缓存系统 1.Memcached是什么? Memcached是高性能的,分布式的内存对象缓存系统,用于在动态应用中减少数据库负载,提升访问速度。Memcached通过在内存里维护一个统一的巨大的hash表,它能够用来存储各种格式的数据,包括图像、视频、文件以及数据库检索的结果等。Memcached由Danga Interactive最初为了加速 LiveJournal网站访问速度而开发的,后来被很多大型的网站采用。起初作者编写它可能是为了提高动态网页应用,为了减轻数据库检索的压力,来做的这个缓存系统。它的缓存是一种分布式的,也就是可以允许不同主机上的多个用户同时访问这个缓存系统,这种方法不仅解决了共享内存只能是单机的弊端, 同时也解决了数据库检索的压力,最大的优点是提高了访问获取数据的速度!基于memcached作者对分布式cache的理解和解决方案。memcached完全可以用到其他地方 比如分布式数据库,分布式计算等领域。Memcached将数据库负载大幅度降低,更好的分配资源,更快速访问。 2.Memcached工作机制 通过在内存中开辟一块区域来维持一个大的hash表来加快页面访问速度,和数据库是独立的。但是目前主要用来缓存数据库的数据。允许多个server通过网络形成一个大的hash,用户不必关心数据存放在哪,只调用相关接口就可。存放在内存的数据通过LRU算法进行淘汰出内存。同时可以通过删除和设置失效时间来淘汰存放在内存的数据。 现在一些.NET开发人员开始放弃ASP.NET内置的缓存机制,转而使用Memcached——一种分布式的内存缓存系统。当运行在单独的Web服务器上,你可以很容易地清除一个已经确认被改变了的缓存。可惜,ASP.NET没有一个很好的方法来支持多服务器。每个服务器上的缓存都对其他缓存的改变一无所知。 ASP.NET允许通过基于文件系统和数据库表的触发器来作废一个缓存。然而,这也存在问题,比如数据库触发器需要使用昂贵的轮询,以及触发器本身冗长的编程。但是,我们还是有其他的选择的。 不像ASP.NET内置的缓存机制,Memcached是一个分布式的缓存系统。任何Web服务器都能更新或删除一个缓存项,并且所有其他的服务器都能在下次访问这些缓存项的时候自动获取到更新的内容。这是通过把这些缓存项存储在一个或者多个缓存服务器上来实现的。每一个缓存项都根据它的关键字的哈希值来分配到一个服务器上。 表面看来,Memcached针对ASP.NET的API就像和内置的API一样。这让开发人员很容易地转换到Memcached上,仅仅通过在代码中查找和替换即可实现。 一个被推荐的解决方案是不根据缓存项的关键字来生成哈希键值。这将允许开发人员能够让一个给定页面中需要的所有缓存项,尽量存放在同一个服务器上。可惜,基于数据保存的地方而不是基于缓存项自身的关键字来生成哈希键,很容易产生错误,需要仔细来实现(这个算法)。 Memcached是基于Linux运行的,你可以在BSD的许可协议下使用Memcached。他也提供了针对C#的客户端以及Perl、Python、PHP、Java和其他语言的API:http://www.danga.com/memcached/apis.bml。还有一个Win32的移植版本(http://jehiah.cz/projects/memcached-win32/),可以让Memcached运行在非Linux的机器上。 Cacheman — .NET架构下的分布式缓存项目 Cacheman据说是由微软旗下的 Popfly 项目组成员 Sriram Krishnan 的作品。是他用业余时间开发的。最新的情况是,微软的 Popfly 网站已经“悄悄地”的做了更新,就是采用了 Krishnan 的 Cacheman,更新了缓存机制。该项缓存技术更新带来的性能提升非常显著,根据Popfly团队中的 John Montgomery 的说法:加载一个已有的Mashup应用时,可以带来2到6倍的性能提升。 这些说法也得到了 Krishnan 本人的确认。他提到这是Cacheman 的第一次的实际应用,并自豪的说 Cacheman 不费吹灰之力就拿下了 Popfly 的全部访问量。 简单介绍一下 Cacheman 这个项目。资料主要来源于 Krishnan的博客对Cacheman的介绍。 Cacheman是一个基于Windows平台的快速分布式哈希表。是由纯托管代码实现。中间搁置了有几个月,直到最近才开始重新上马这个项目,极可能就是因为Popfly项目需要的缘故才开始着手的。 Krishnan本人对 memcached 很感兴趣,于是创建了 Cacheman。Cacheman上有很多 memcached 的影子,比如与memcached相似的文本通讯协议。Cacheman的通讯协议公开,任何人可以根据自己偏爱的语言环境写客户端。 Krishnan 在自己家用电脑(2.4GHz Intel Core 2 带2GB内存)上进入测试,达到了每秒16000次左右的请求,并且还是服务器与客户端都是在同一台服务器下完成的。 现这款产品还不太完善,作者自身也提到:在Cacheman做指定key的GET/SET/DELETE操作时,客户端需要弄清需要与哪一台Cacheman服务器通讯,为此要对该key做一个快速FNV哈希然后求余得到应该和几台服务器中的哪台服务器通讯。但该法的缺点在于新增或删除一个服务器节点时,缓存节点需要大规模迁移。修复该问题需要一致性的哈希算法,作者表示还没有时间解决此事。作者提出了采用中心架构的“主缓存服务器”的解决办法,让客户端轮询主缓存服务器来获取应该与那个缓存服务器通讯,但他也觉的这样做增加了复杂性,会带来些新问题。 可以感觉到,由于 Cacheman 这个个人项目已经介入到 Popfly 这个正式产品中,可能很快就会被微软吸纳为正式产品,因此如果有人采用这个产品做自己缓存的解决方案的话,应该不必太担心后续的产品升级及文档支持服务,它的未来前途值的期待。说不定 Krishnan 会从 Popfly 项目脱身出来专职负责这个 Cacheman 项目。 目前最新的版本是0.0.2版 :http://www.sriramkrishnan.com/code/。 from:http://kb.cnblogs.com/page/69728/
View DetailsASP.NET缓存全解析3:页面局部缓存
有时缓存整个页面是不现实的,因为页的某些部分可能在每次请求时都需要变化。在这些情况下,只能缓存页的一部分。顾名思义,页面部分缓存是将页面部分内容保存在内存中以便响应用户请求,而页面其他部分内容则为动态内容。页面部分缓存的实现包括两种方式:控件缓存和替换后缓存。 1. 控件缓存(也称为片段缓存) 这种方式允许将需要缓存的信息包含在一个用户控件内,然后,将该用户控件标记为可缓存的,以此来缓存页面输出的部分内容。该选项允许缓存页面中的特定内容,而没有缓存整个页面,因此,每次都需重新创建整个页。例如,如果要创建一个显示大量动态内容(如股票信息)的页,其中有些部分为静态内容(如每周总结),这时可以将静态部分放在用户控件中,并允许缓存这些内容。 在ASP.NET中,提供了UserControl这种用户控件的功能。一个页面可以通过多个UserControl来组成。只需要在某个或某几个UserControl里设置缓存。 例如: 那么可以在WebUserControl1.ascx的页头代码中添加声明语句: <%@ Control Language="C#" AutoEventWireup="true" CodeBehind="WebUserControl1.ascx.cs" Inherits="CacheWebApp._16_4_5.WebUserControl1" %> <%@ OutputCache Duration="60" VaryByParam="none" %> <%=DateTime.Now %> 调用该控件的页面WebForm1.aspx代码: <%@ Page Language="C#" AutoEventWireup="true" CodeBehind="WebForm1.aspx.cs" Inherits="CacheWebApp._16_4_5.WebForm1" %> <%@ Register src="WebUserControl1.ascx" tagname="WebUserControl1" tagprefix="uc1" %> <html xmlns="http://www.w3.org/1999/xhtml" > <head runat="server"> <title>控件缓存</title> </head> <body> <form id="form1" runat="server"> <div> 页面的:<%=DateTime.Now %> </div> <div> 控件的:<uc1:WebUserControl1 ID="WebUserControl11" runat="server" /> </div> </form> </body> </html> 这时候刷新WebForm1.aspx页面时,页面的时间每次刷新都变化,而用户控件中的时间数据却是60秒才变化一次,说明对页面的“局部”控件实现了缓存,而整个页面不受影响。 2. 缓存后替换 与控件缓存正好相反。它对整个页面进行缓存,但是页中的某些片段是动态的,因此不会缓存这些片段。ASP.NET页面中既包含静态内容,又包含基于数据库数据的动态内容。静态内容通常不会发生变化。因此,对静态内容实现数据缓存是非常必要的。然而,那些基于数据的动态内容,则不同。数据库中的数据可能每时每刻都发生变化,因此,如果对动态内容也实现缓存,可能造成数据不能及时更新的问题。对此问题如果使用前文所述的控件缓存方法,显然不切实际,而且实现起来很繁琐,易于发生错误。 如何实现缓存页面的大部分内容,而不缓存页面中的局部某些片段。ASP.NET 2.0提供了缓存后替换功能。实现该项功能可通过以下三种方法: 一是以声明方式使用Substitution控件。 二是以编程方式使用Substitution控件API。 三是以隐式方式使用控件。 前两种方法的核心是Substitution控件,本节将重点介绍该控件,第三种方法仅专注于控件内置支持的缓存后替换功能,本节仅做简要说明。 (1) Substitution控件应用 为提高应用程序性能,可能会缓存整个ASP.NET页面,同时,可能需要根据每个请求来更新页面上特定的部分。例如,可能要缓存页面的很大一部分,需要动态更新该页上与时间或者用户高度相关的信息。在这种情况下,推荐使用Substitution控件。Substitution控件能够指定页面输出缓存中需要以动态内容替换该控件的部分,即允许对整页面进行输出缓存,然后,使用Substitution控件指定页中免于缓存的部分。需要缓存的区域只执行一次,然后从缓存读取,直至该缓存项到期或被清除。动态区域,也就是Substitution控件指定的部分,在每次请求页面时都执行。Substitution控件提供了一种缓存部分页面的简化解决方案。 <%@ Page Language="C#" AutoEventWireup="true" CodeBehind="WebForm2.aspx.cs" Inherits="CacheWebApp._16_4_5.WebForm2" %> <%@ OutputCache Duration="60" VaryByParam="none" %> <html xmlns="http://www.w3.org/1999/xhtml" > <head […]
View Details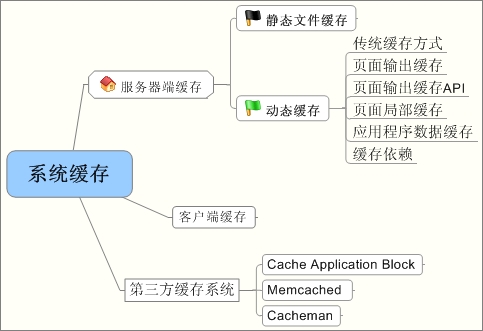
ASP.NET缓存全解析1:缓存的概述
有时候总听到网友说网站运行好慢,不知如何是好;有时候也总见到一些朋友写的网站功能看起来非常好,但访问性能却极其的差。没有“勤俭节约”的意识,势必会造成“铺张浪费”。如何应对这种情况,充分利用系统缓存则是首要之道。 系统缓存有什么好处呢?举个简单的例子,你想通过网页查询某些数据,而这些数据并非实时变化,或者变化的时间是有期限的。例如查询一些历史数据。那么每个用户每次查的数据都是一样的。如果不设置缓存,ASP.NET也会根据每个用户的请求重复查询n次,这就增加了不必要的开销。所以,可能的情况下尽量使用缓存,从内存中返回数据的速度始终比去数据库查的速度快,因而可以大大提供应用程序的性能。毕竟现在内存非常便宜,用空间换取时间效率应该是非常划算的。尤其是对耗时比较长的、需要建立网络链接的数据库查询操作等。 缓存功能是大型网站设计一个很重要的部分。由数据库驱动的Web应用程序,如果需要改善其性能,最好的方法是使用缓存功能。 缓存的分类 从分布上来看,我们可以概括为客户端缓存和服务器端缓存。 客户端缓存——这点大家都有直观的印象。比如你去一个新的网站,第一次可能要花一阵子时间才能载入整个页面。而以后再去呢,时间就会大大的缩短,原因就在于这个客户端缓存。现在的浏览器都比较智能,它会在客户机器的硬盘上保留许多静态的文件,比如各种gif,jpeg文件等等。等以后再去的时候,它会尽量使用本地缓存里面的文件。只有服务器端的文件更新了,或是缓存里面的文件过期了,它才会再次从服务器端下载这些东西。很多时候是IE替我们做了这件事情。 服务器端缓存——有些东西没法或是不宜在客户端缓存,那么我们只好在服务器端想想办法了。服务器端缓存从性质上看,又可以分为两种。 (1)、静态文件缓存 好多页面是静态的,很少改动,那么这种文件最适于作静态缓存。现在的IIS 6.0这部分内容是直接存放在Kernel的内存中,由HTTP.SYS直接管理。由于它在Kernel Space,所以它的性能非常的高。用户的请求如果在缓存里面,那么HTTP.SYS直接将内容发送到network driver上去,不需要像以前那样从IIS的User space的内存copy到Kernel中,然后再发送到TCP/IP stack上。Kernel level cache几乎是现在高性能Web server的一个必不可少的特性。 (2)、动态缓存 动态缓存是比较有难度的。因为你在缓存的时候要时刻注意一个问题,那就是缓存的内容是不是已经过时了。因为内容过时了可能会有很严重的后果。比如网上买卖股票的网站。你给别人提供的价格是过时的,那人家非砍了你不可。缓存如何发现自己是不是过时就是一个非常复杂的问题。 在ASP.NET中,常见的动态缓存主要有以下几种手段: Ø 传统缓存方式 Ø 页面输出缓存。 Ø 页面局部缓存。 Ø 利用.NET提供的System.Web.Caching 缓存。 Ø 缓存依赖。 传统缓存方式 比如将可重复利用的东西放到Application或是Session中去保存。 Session["Style"] = val; Application["Count"] = 0; from:http://kb.cnblogs.com/page/69483/
View DetailsASP.NET缓存全解析2:页面输出缓存
页面输出缓存是最为简单的缓存机制,该机制将整个ASP.NET页面内容保存在服务器内存中。当用户请求该页面时,系统从内存中输出相关数据,直到缓存数据过期。在这个过程中,缓存内容直接发送给用户,而不必再次经过页面处理生命周期。通常情况下,页面输出缓存对于那些包含不需要经常修改内容的,但需要大量处理才能编译完成的页面特别有用。需要读者注意的是,页面输出缓存是将页面全部内容都保存在内存中,并用于完成客户端请求。 在ASP.NET中页面缓存的使用方法非常的简单,只需要在aspx页的顶部加这样一句声明即可: <%@ OutputCache Duration="60" VaryByParam="none" %> Duration:缓存的时间(秒),这是必选属性。如果未包含该属性,将出现分析器错误。 <%@ Page Language="C#" AutoEventWireup="true" CodeBehind="WebForm1.aspx.cs" Inherits="CacheWebApp._16_4_3.WebForm1" %> <%@ OutputCache Duration="60" VaryByParam="none" %> <html xmlns="http://www.w3.org/1999/xhtml" > <head runat="server"> <title>页面缓存示例</title> </head> <body> <form id="form1" runat="server"> <div> <asp:Label ID="Label1" runat="server" Text="Label"></asp:Label> </div> </form> </body> </html> 后台代码: protected void Page_Load(object sender, EventArgs e) { if (!IsPostBack) { Label1.Text = DateTime.Now.ToString(); } } 如果不加<%@ OutputCache Duration="60" VaryByParam="none" %>,每次刷新页面上的时间每次都是在变。而加了缓存声明以后,每次刷新页面的时间并不变化,60秒后才变化一次,说明数据被缓存了60秒。 VaryByParam:是指页面根据使用 POST 或 GET 发送的名称/值对(参数)来更新缓存的内容,多个参数用分号隔开。如果不希望根据任何参数来改变缓存内容,请将值设置为 none。如果希望通过所有的参数值改变都更新缓存,请将属性设置为星号 (*)。 例如: http://localhost:1165/16-4-3/WebForm1.aspx?p=1 则可以在WebForm1.aspx页面头部声明缓存:<%@ OutputCache Duration="60" VaryByParam="p" %> 以上代码设置页面缓存时间是60秒,并根据p参数的值来更新缓存,即p的值发生变化才更新缓存。 如果一直是WebForm1.aspx?p=1访问该页,则页面会缓存当前数据,当p=2时又会执行后台代码更新缓存内容。 如果有多个参数时,如:http://localhost:1165/16-4-3/WebForm1.aspx?p=1&n=1 可以这样声明:<%@ OutputCache Duration="60" VaryByParam="p;n" %> 除此之外,@OutputCache 还有一些其他的属性。@OutputCache指令中的属性参数描述如下: <%@ OutputCache […]
View Details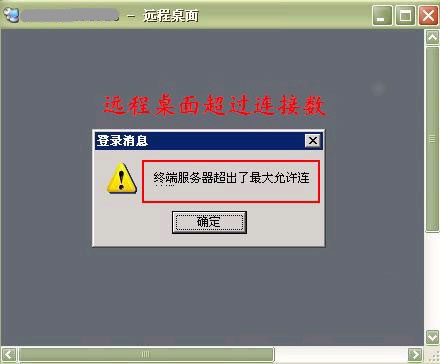
修改远程桌面连接数
今天管理一台服务器,远程连接时帐号密码都输入完后,点连接后弹出一个“终端服务器超出最大允许连接数”的提示窗口。 终端服务器超出最大允许连接数 上网查了一下归结一下出现这种情况的原因和解决办法。 原因:用远程桌面链接登录到终端服务器时经常会遇到“终端服务器超出最大允许链接数”诸如此类错误导致无法正常登录终端服务器,引起该问题的原因在于终端服务的缺省链接数为2个链接,并且当登录远程桌面后如果不是采用注销方式退出,而是直接关闭远程桌面窗口,那么实际上会话并没有释放掉,而是继续保留在服务器端, 这样就会占用总的链接数,当这个数量达到最大允许值时就会出现上面的提示。 如何避免? 一、用注销来退出远程桌面而不是直接关闭窗口 二、限制已断开链接的会话存在时间 1、从终端服务配置中修改 运行-Tscc.msc(终端服务配置)-连接-双击RDP-Tcp或右击-属性-会话-选中第一个的替代用户设置(O)-结束已断开的会话[将默认值“从不”改为一个适当的时间,比如30分钟] 2、从组策略修改 开始-运行-gpedit.msc-计算机配置-管理模板-windows组件-终端服务-会话 右边窗口选择 为断开的会话设置时间限制 -选择已启用,选择一个时间 三、增加最多链接数 1、 从终端服务配置中修改:运行-Tscc.msc(终端服务配置)-连接-双击RDP-Tcp或右击-属性,选择“网卡”选项卡-修改“最大连接数”改成你所需的值,当然这个值不也能太大,否则会占用较多的系统资源。不过这里修改的值好像不起作用,设置成无限制时照样还是会出现本文所说的情况。 2、组策略级别要高于终端服务配置,当启用组策略后终端服务配置中的相应选项会变成灰色不可修改。 运行-gpedit.msc-计算机配置-管理模板-Windows组件-终端服务 双击右边的“限制连接数量”-选择“已启用”-填入允许的最大连接数 四、改变远程终端模式 打开“控制面板”,双击“添加删除程序”,单击“添加删除Windows组件”,“组件”,在Windows组件向导对话框中选中“终端服务” , “下一步”,“应用服务器”,“下一步”,然后按照提示即可改变终端服务的模式。 Windows 2000终端服务有2种运行模式:远程管理模式和应用程序服务器模式。远程管理模式允许系统管理员远程管理服务器,而且只允许2个终端会话同时登录终端服务器。应用程序服务器模式允许用户 运行一个以上应用程序,允许多个用户从终端登录访问服务器。但是,应用终端服务的用户必须有终端服务授权,即必须在90天之内在这个域或工作组中设置终端 服务授权服务器,否则用户需删除应用程序,然后再重新安装。 五、修改本地安全策略 控制面板>>管理工具>>本地安全策略>>本地策略>>安全选项>> 1、先找到>>Microsoft网络服务器:在挂起会话之前所需的空闲时间 默认为:15分钟,改为自己所需要的时间(就是登陆后无动作空闲超过多少时间后自动断开) 2、然后找到>>网络安全:在超过登录时间后强制注销。默认为:已禁用,一定要改为:已启用 六、踢出已经断开的连接用户 1、首先通过各种方法连接到服务器上(telnet); 2、上去后,查看登陆用户列表。输入命令:query user; 这样你就可以看出有何不同来啦,可以根据你的具体情况而定。ID为0的用户就是本地登陆的,而在State中看提示,当提示为已断开,则说明用户已经断开还占用着系统资源和通道,这样就可以把该用户踢掉。输入logoff ID,即踢除相应ID的用户。 七、限制用户会话数 对Terminal Services进行限制,使得一个用户仅仅能够连接一次。对于Windows Server 2003,请在Terminal Services Configuration(Terminal Services配置)中将“限制每位用户只有拥有一个会话”(Restrict each user to one session)设置为“是”(Yes)。此外,您可以将“限制终端服务用户使用单个远程会话”组策略设置为“启用”。 —————————————————————————————————————————————————————- 安装了windows server 2008 R2,现在要远程连接,开启了服务器上的远程桌面连接,使用管理员远程登录。默认情况下windows server 2008只允许一个连接。默认一个账号最大2个连接。 因需要两台电脑连接。在windows server 2008 调整下默认配置。 开启远程桌面连接: 计算机—属性—远程设置—勾选"允许运行任意版本远程桌面的计算机连接(较不安全)" 有的时候我们windows server 2008服务器需要多个管理员同时登录的,这时我们就需要修改远程桌面的连接数了,具体修改方法如下: windows server 2008设置远程桌面连接最大数量 系统默认远程桌面连接的数量为1。控制面板—类别选择"小图标"—管理工具—远程桌面服务—远程桌面会话主机设置—把"限制每个用户只能进行一个会话"勾选去掉, 然后双击连接中的RDP-Tcp—网络适配器--最大连接数 修改为2 此时的同时远程桌面连接的数量即设置为2。 如果“最大连接数”选项已选中并且灰显,则“限制连接数”组策略设置已启用并且应用于 RD 会话主机服务器。 通过应用“限制连接数”组策略设置,还可以为 RD 会话主机服务器设置允许的最大同时连接数。此组策略设置位于“计算机配置\策略\管理模板\Windows 组件\远程桌面服务\远程桌面会话主机\连接”中,可以使用本地组策略编辑器或组策略管理控制台 (GPMC) 进行配置。请注意,此组策略设置将优先于远程桌面会话主机配置中配置的设置。 […]
View Details