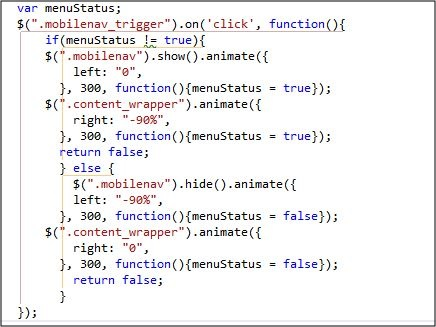


相信很多人都不习惯这个操作,因为一贯的传统和一直以来的版本都是双击打开项目中的文件。
既然以前是这样,现在改了那么一定有设置的地方,作为微软这样人性化设计的公司一定有回旋和适应的操作。没错,花了几分钟确实找到了:

from:http://hi.baidu.com/jiang_yy_jiang/item/d960411afb71bc3ab83180f1
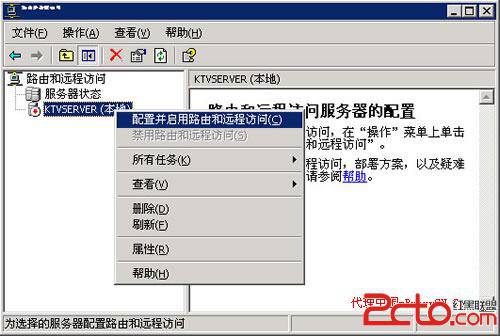
Windows Server 2003单网卡搭建VPN 1.打开[控制面板] --> [管理工具] --> [路由和远程访问] 2.鼠标右击你要管理的电脑 在弹出式菜单中选中[配置并启用路由和远程访问] 3.选中[自定义],因为你只有一块网卡嘛,所以选中第一项或第三项的话,你会得到一个“必须两块网卡”的提示 4.下一步就是选中[VPN访问],然后系统会问你“要不要启动服务” 当然要启动了。 5.启动成功后,会得到如下图所示的情形,鼠标右击 要管理的电脑(这里的[KTVSERVER(本地)]),然后在弹出式菜单中选中[属性] 6.在弹出的控制面板中选中[IP] --> [静态地址池] --> [添加] 然后输入个起始IP [192.168.1.1] 结束IP [192.168.1.254],这个IP段,是给拔入你的VPN服务器的客户端分配的虚拟IP 7.完成后如下图 8.然后鼠标右击[静态路由]--> [新建静态路由] 9. [接口]选“本地连接”,目标[0.0.0.0],网络掩码[0.0.0.0],网关输入你的网卡上TCP/IP协议里的那个网关(由于本人服务器是使用公网IP,所以使用的是电信局端网关),这一步很重要,不然你的VPN服务器客户拔入后,只能访问你的服务器,不然再访问其它网络。QQ之类的就不能用了 10.然后删除[DHCP 中继代理程序] 中的[内部] 11.然后鼠标右击[DHCP 中继代理程序] 在弹出式菜单中[新增接口] 12.选中[本地连接] 13.完成以上后,鼠标右击[常规] --> [新增路由协议] 14.选中[NAT/基本防火墙] 15.加完后,你就会在左例表中看到[NAT/基本防火墙],鼠标右击[NAT/基本防火墙],选中弹出式菜单中[新增接口] 16.选中[本地连接] 17.在面板中选择 [公用接口连接到 Internet] --> [在此接口上启用NAT] ,如果你WINDOWS 2003中使用了系统自带的防火墙的话,请在[服务和端口],中要使用的服务打上勾,如果你不太清楚的话,那就全打上勾. 18.全部完成,然后使用 VPN拔号软件 连入就行了 from:http://www.2cto.com/os/201307/228278.html
View Details可以使用ctrl + shift + f 来格式化代码; 可以使用安装插件wordwrap来实现代码的自动换行:Help ->Install new Software->work with,点击Add,输入 name:wordwrap url:http://ahtik.com/eclipse-update/ 安装成功后重启eclipse from:http://liangfangli86.blog.163.com/blog/static/9684863120116183727729/
View Details今天,Windows XP系统的用户将收到来自微软的最后一次补丁,微软撒手之后留下的,是各种安全厂商和黑客的天堂。根据市场调查公司Net Application数据,2月XP系统的市场份额为29.53%。而根据Gartner的预测,到今天,仍然将有15%的企业用户至少在10%的PC上运营着XP系统。而一份微软官方认可的文件中认为,在中国仍然有着两亿XP用户。 真实用户的感受会延后 虽然媒体、安全厂商、微软以及各类活动都在讲述这4月8日这一天的意义,但对于普通用户来说,感受并不明显。 联想中国区总裁陈旭东表示,“这个问题很奇怪,目前只有不相关的第三方大范围在问我们,但目前我没有接到一个来自我们用户的诉求,比如说,家里电脑应该没有更新怎么怎么了。” 要 理解这句话首先要弄清的客观事实有:首先,PC厂商很多年已经不再生产预装XP系统的电脑了;其次,如果将电脑买回家后自行安装XP系统,如果出现问题, 消费者更多选择重装系统,而不是找PC厂商。对于还在使用XP的人群来说,只有当自己电脑受到漏洞的问题造成影响后,对于XP漏洞的问题才会更警惕。 但是需要说明的,是XP系统多年来漏洞层出不穷的客观现实。从打印机接口到Outlook,从IE6到U盘接口,使用XP系统但同时微软不负责补丁更新之后,用户的风险直接存在着。 一份外媒的报道称,相信有很多黑客积攒着手上的一些漏洞,将等到4月8日后一个个放出,从而获取最大的利益。而对于这样的攻击,有安全专家认为,最好的办法就是远离互联网。 安全厂商的盛宴 在每一个软件产品推出时,厂商都有一个被称为技术支持周期的日期,而Windows XP是微软一直以来服务时间最长的操作系统。而在微软转身之后,最积极的是安全软件厂商。 包 括360、金山、瑞星、腾讯等一系列厂商是2014年以来最积极传播此事的企业,而它们所争夺的正是代替微软提供XP系统的安全补丁。在推广手法上,各家 无所不用其极,在通过这样的方式占领用户的电脑后,通过装机量做入口、流量等业务已经是一个成熟的商业模式,而微软撇下的XP用户正是这个模式最好的运营 空间。不过从另一个角度来说,由于各家的竞争激烈,对安全保证的质量上或许会有所提高,因为任何一家出现问题则会被对方发现并放大。 除了安全厂商外,另一种最热烈的声音来自对国产操作系统的呼吁,XP的更新再一次将国内PC对微软的依赖放在显微镜下,倡导发展国产操作系统、鼓励自主研发的声音也是最为响亮的时候。 给一个普通XP用户的建议 一家黑客网站给出了对普通XP用户最简单的建议,内容如下: 1、安装所有微软提供的补丁,包括4月8日更新的最后一个。 2、从IE6升级至IE8,能解决一半以上的威胁。 3、选一家安全软件。对国内的不信任,还有国际的赛门铁克等。 4、内网部署杀毒软件,只启用必须的系统服务,不需要使用的服务全部用安全策略禁止启动。 5、对于没有接入互联网但又使用WindowsXP的生产系统,可以禁用或限制使用USB设备。 from:http://www.oschina.net/news/50539/microsoft-abort-windows-xp-today
View Details假如要Google Play上做一个最失败的案例,那最好的秘诀就是界面奇慢无比、耗电、耗内存。接下来就会得到用户的消极评论,最后名声也就臭了。即使你的应用设计精良、创意无限也没用。 耗电或者内存占用等影响产品效率的每一个问题都会影响App的成功。这就是为什么在开发中确保最优化、运行流畅而且不会使Android系统出问题 是至关重要的了。这里不需要讨论高效编程,因为我们不会关心你写的代码是否能够经得起测试。即使高效的代码也是需要时间来运行。今天这篇文章我们就讲讲怎 么尽可能地缩短运行时间,以及如何开发用户喜欢的App。 高效地利用线程 建议一:怎么在后台取消一些线程中的动作 我们知道App运行过程中所有的操作都默认在主线程(UI线程)中进行的,这样App的响应速度就会受到影响。会导致程序陷入卡顿、死掉甚至会发生系统错误。 为了加快响应速度,需要把费时的操作(比如网络请求、数据库操作或者复杂的计算)从主线程移动到一个单独的线程中。最高效的方式就是在类这一级完成 这项操作,可以使用AsyncTask或者IntentService来创建后台操作。如果选择使用IntentService,它会在需要的时候启动起 来,然后通过一个工作线程来处理请求(Intent)。 使用IntentService时需要注意以下几点限制: 这个类不要给UI传递信息,如果要向用户展示处理结果信息请用Activity; 每次只能处理一个请求; 每一个处理请求过程都不能中断; 建议二:怎么保持响应不发生ANR 从UI线程中移除费时操作这个方式还可以防止用户操作出现系统不响应(ANR)对话框。需要做的就是继承AsyncTask来创建一个后台工作线程,并实现doInBackground()方法。 还有一种方式就是自己创建一个Thread类或者HandlerThread类。需要注意这样也会使App变慢,因为默认的线程优先级和主线程的优先级是一样的,除非你明确设定线程的优先级。 建议三:怎么在线程中初始化查询操作 当查询操作正在后台处理时,展示数据也不是即时的,但是你可以使用CursorLoader对象来加快速度,这个操作可以使Activity和用户之间的互动不受影响。 使用这个对象后,你的App会为ContentProvider初始化一个独立的后台线程进行查询,当查询结束后就会给调用查询的Activity返回结果。 建议四:其它需要注意的方面 使用StrictMode来检查UI线程中可能潜在的费时操作; 使用一些特殊的工具如Systrace或者Traceview来寻找在你的应用中的瓶颈; 用进度条向用户展示操作进度; 如果初始化操作很费时,请展示一个欢迎界面。 优化设备的电池寿命 如果应用很费电,请不要责怪用户卸载了你的应用。对于电池使用来说,主要费电情况如下: 更新数据时经常唤醒程序; 用EDGE或者3G来传递数据; 文本数据转换,进行非JIT正则表达式操作。 建议五:怎么优化网络 如果没有网络连接,请让你的应用跳过网络操作;只在有网络连接并且无漫游的情况下更新数据; 选择兼容的数据格式,把含有文本数据和二进制数据的请求全部转化成二进制数据格式请求; 使用高效的转换工具,多考虑使用流式转换工具,少用树形的转换工具; 为了更快的用户体验,请减少重复访问服务器的操作; 如果可以的话,请使用framework的GZIP库来压缩文本数据以高效使用CPU资源。 建议六:怎么优化应用在前端的工作 如果考虑使用wakelocks,尽量设置为最小的级别; 为了防止潜在的bug导致的电量消耗,请明确指定超时时间; 启用 android:keepScreenOn属性; 除了系统的GC操作,多考虑手动回收Java对象,比如XmlPullParserFactory和BitmapFactory。还有正则表达式的Matcher.reset(newString)操作、StringBuilder.setLength(0)操作; 要注意同步的问题,尽管在主线程中是安全的; 在Listview中要多采用重复利用策略; 如果允许的话多使用粗略的网络定位而不用GPS,对比一下GPS需要1mAh(25s * 140 mA),而一般网络只用0.1mAh(2s * 180mA); 确保注销GPS的位置更新操作,因为这个更新操作在onPause()中也是会继续的。当所有的应用都注销了这个操作,用户可以在系统设置中重新启用GPS而不浪费电量; 请考虑在大量数理运算中使用低精度变量并在用DisplayMetrics进行DPI任务时缓存变量值; 建议七:怎么优化工作在前台的应用 请确保service生命周期都是短暂的,因为每个进程都需要2MB的内存,而在前台程序需要内存时也会重新启动; 保持内存的使用量不要太大; 如果要应用每30分钟更新一次,请在设备处于唤醒状态下进行; Service在pull或者sleep状态都是不好的,这就是为什么在服务结束时要使用AlarmManager或者配置属性stopSelf()的原因。 建议八:其它注意事项 在进行整体更新之前检查电池的状态和网络状态,等待最好的状态在进行大幅度装换操作; 让用户看到用电情况,比如更新周期,后台操作的时候; 实现低内存占用UI 建议九:怎么找到布局显示问题 当我们为布局单独创建UI的时候,就是在创建滥用内存的App,它在UI中会出现可恶的延时。要实现一个流畅的、低内存占用的UI,第一步就是搜索 你的应用找出潜在的瓶颈布局。使用Android SDK/tools/中自带的Hierarchy Viewer Tool工具。 还有一个很好的工具就是Lint,它会扫描应用的源码去寻找可能存在的bug,并为控件结果进行优化。 建议十:如何解决问题 如果布局显示结果发现了问题,你可以考虑简化布局结构。可以把LinearLayout类型转化成RelativeLayout类型,降低布局的层级结构。 做到更加完美并不断优化 尽管以上的每条建议看起来都是很小的改进,但是如果它能成为你日常代码的一部分,那么你就会看到意想不到的结果。要让Google Play看到更多杰出的、流畅的、更快速、更省电的应用,向Android走向完美的目标迈进一步。 原文链接: azoft 翻译: 伯乐在线 – chris 译文链接: http://blog.jobbole.com/64279/ from:http://www.oschina.net/news/50413/android-application-development-tips
View DetailsMarkdown 是 2004 年由 John Gruberis 设计和开发的纯文本格式的语法,所以通过同一个名字它可以使用工具来转换成 HTML。readme 文件,在线论坛编写消息和快速创建富文本文档的文本编辑器都非常流行使用 Markdown 格式。 在这篇文章中,我们会介绍 Windows 和 Mac OSx 下的一些有用的 Markdown 编辑器和工具。下面列表的工具会帮助您无障碍的去轻松编写和格式化文本,转换和预览标记语言。如果您觉得有哪些非常好的 Markdown 工具被我们忽略了,在评论中与大家交流吧:) 编辑器 1. StackEdit StackEdit 是个免费开源的 Markdown 编辑器,是基于 PageDown (Stack Overflow 使用的库)的。此编辑器可以传教和管理存储在本地的多个文档,同时也可以从 Google Drive 或者 Dropbox 导出或者导入,可以保存文档为 HTML 格式。 2. EpicEditor EpicEditor 是个嵌入式 JavaScript Markdown 编辑器,带有独立全屏编辑,在线预览,自动草稿保存,支持离线等功能。对于开发者来说,它提供一个强健的 API,容易进行自定义;允许通过绑定的 Markdown 解析器转换任何想转换的东西。EpicEditor 设置成可以允许用户使用任意的百年祭起,接受和返回一个字符串。这也说明用户可以使用任何风格的 Markdown, process Textile,甚至是创建一个简单的 HTML 编辑器/预览器 。同时,EpicEditor 的主题也非常容易自定义。 3. Markable Markable 是个卓越的 Markdown 编辑器,提供 Markdown 语法高亮,自动缩进和解除缩进,高亮当前行功能;提供行号,提供一个明亮和暗淡的主题;提供自动保存功能。当转换 HTML 到 Markdown 格式时,无论在什么设备,再次启动时都会恢复到最后编辑的状态。更厉害的是,它可以上传文件到其他设备,也可以从其他设备导入文件。 4. Dillinger Dillinger 是 cloud-enabled 的 HTML5 Markdown 编辑器,基于 Bootstrap 和 Node.js 5. Markdown Pad Markdown Pad 是 Windows 下的全功能 Markdown 编辑器。用户可以通过方便的键盘快捷键和工具栏按钮来使用或者移除 Markdown 格式。当你创建的时候,可以实时看到 HTML […]
View Details相信很多人都不习惯这个操作,因为一贯的传统和一直以来的版本都是双击打开项目中的文件。
既然以前是这样,现在改了那么一定有设置的地方,作为微软这样人性化设计的公司一定有回旋和适应的操作。没错,花了几分钟确实找到了:
from:http://hi.baidu.com/jiang_yy_jiang/item/d960411afb71bc3ab83180f1
|
1 2 3 4 5 |
1.打开注册表 [HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Terminal Server\Wds\rdpwd\Tds\tcp],修改右边PortNamber的值,其默认值是3389,修改成所希望的端口即可,例如3309; 2.再打开注册表 [HKEY_LOCAL_MACHINE\SYSTEM\CurrentContro1Set\Control\Tenninal Server\WinStations\RDP-Tcp],修改右边PortNamber的值,其默认值是3389,修改成所希望的端口即可,例如3309 注意:修改完后需要重启生效,别忘记在防火墙里加例外。 |
出现下面这就话:
|
1 2 3 |
<span style="color: #ed1c24;">Strict Standards: Only variables should be passed by reference in D:\wamp\ecshop\includes\cls_template.php on line 406</span> <wbr /> 第406行:<span style="color: #fd1856;">$tag_sel = array_shift(explode(' ', $tag));</span> |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
<span style="color: #0a07ff;">解决办法 1 </span> 5.3以上版本的问题,应该也和配置有关 只要406行把这一句拆成两句就没有问题了 $tag_sel = array_shift(explode(' ', $tag)); 改成: $tag_arr = explode(' ', $tag); $tag_sel = array_shift($tag_arr); <wbr /> <span style="color: #ed1c24;">(实验过,绝对可行) </span>因为array_shift的参数是引用传递的,5.3以上默认只能传递具体的变量,而不能通过函数返回值 <span style="color: #0a07ff;">解决办法 2 :</span> 或则如果这样配置的话: error_reporting = E_ALL | E_STRICT from:<a href="http://blog.sina.com.cn/s/blog_7dc986fc01013acp.html">http://blog.sina.com.cn/s/blog_7dc986fc01013acp.html</a> |
干了将近7年的软件开发,我开发实现了很多有趣的东西。最近,我开始投身销售,研究营销技术——为了我的新应用。 我感到发现客户并理解他们的消费行为是一件非常有挑战性的事情,同时也有很多的乐趣。程序员对销售的典型态度要么认为它不重要——这是最好的情况,最坏的 情况是根本不知道何为销售。在这里我要讲的是非常不同的另一面,希望能带来一些能让大家兴奋的建议。如果你喜欢这些建议,我将会再写一篇。 下面的这些忠告都是来自我经营一个B2B服务软件的经验。也许并不是每个人都能接受,但至少从趣味性和知识性方面还是值得一读的。 销售很重要。现在就拥抱它,从长期看,掌握它会带给你好处多多,你会理解销售有多难。 如果你不愿意投入时间、投入精力去理解销售,你又如何能期望别人去施展销售技术。 掌握一些统计学知识 你已经掌握了计算机、编程、软件工程等方面的众多知识,为什么不学点新玩意? 量化所有东西。这方面我还会说到好几次。 理解你的客户,因为你是在为他们做软件。 你做的所有事情都是为客户服务,即使有些东西他们是看不到的。 犹豫的客户是已经感兴趣的客户。 接上条,犹豫的客户在你上前提供帮助时不会觉得你讨厌。 接上条,你需要做的是,帮助他们明白这款产品很适合他。 产品的价值是体现在客户眼里的。 如果你不确信你的产品是否值这个价格,要么不要卖,要么换个价格。 和人们打交道进行营销是一个终极的分布式系统。 程序员做销售有优势,因为你对产品的理解有特殊的方式。 程序员做销售有优势,因为你能穿透表象看到数据。 程序员做销售有劣势,因为你对软件的理解是一种特殊的方式。 程序员做销售有劣势,因为你能穿透表象看到数据。 用数据分析出谁应该是你交流的对象。 多交流。 多打电话。 真的,多打电话。 站在客户的立场上想问题。 用数据说话。 用图表,95%的数据都要有图表。 目前有多少试用用户?你应该知道。 有多少客户到了他们试用的最后一天?你应该知道。 明白我的意思吗?你需要十分了解你的试用用户。尽可能多的了解。 你的软件的试用期是多久?为什么是这么久? 定价非常难,你至少会能弄错一次。 听取客户对价格的议论,但对产品的价值你必须有信心。 便宜没好货。 有很多关于销售的学问,学一点。 Bruce Hardie很出色。学学他。 你的竞争对手是如何买产品的? 尝试别人的试用产品,看看别人是如何做的。 下次如果接到销售的电话,多说说。学学电话的另一端是如何工作的。 包年价效果很好,有机会就提供这样的套餐。 争取一个新客户的开销是多少? 一个新客户能给你带来多少收入? 一个客户能给你带来的经常性收入是多少? 销售很有趣。喜欢上它。 [英文原文:Sales For Engineers, 1-50 ] from:http://www.oschina.net/news/50074/sales-for-engineers
View Details对于那些不知道程序员/开发者的时间都去哪了的人,本文可能会提供一些线索。我记录了这份日志不仅是为了看看时间都花费在哪了,也是为了看看我都做了些什么,检视下自己是否偷懒了。当回顾之后,我发现花这些时间都是值得的。 作为开始,下面是我在前一阶段追踪的bug,(假设)你应该可以看到其中的错误。仅仅拿出这10行JavaScript并找到错误在哪里并不难,但要在茫茫的代码中定位这10行并证明那些就是bug,这就有一定的难度了。 如此宁静的一天。通常情况下,有三个人可能打断我工作的连贯性,因为11:30之前,我要不时的与他们通过语音或文字信息交流和讨论。把这些过程以log记录下来,实际上是对我工作的推进是有帮助的。这使得我能端坐在键盘前专注于我的工作,以免被别的问题分心。 09:50 收到了一封来自团队成员的邮件,内容是关于一些可能会产生问题的代码。我看了一下,并把目前解决不了部分整理起来。 10:10 继续昨天IE7虚拟机的下载(4gb)。 10:15 由于IE7下载的时间比较长,我趁着下载的时候,申请了TestingBot的账号。 10:20 与一名开发者Skype语音,讨论关于他新添加的功能。 10:21 由于设计师没有正确的把图片上传到网站,产生了大量的报错邮件。我花费了两天的时间让设计师掌握源代码控制软件。由于有些设计师没有Visual Studio,我也建立了一些用来存储特定内容的文件夹,这些文件夹可以自动发布问题给这些设计师。我有没有提到,无论是在测试中,镜像模拟阶段还是已发 布的产品中出现的每一个错误我都会记录下来。我认为这些设计师都应该看一看。 10:22 一名开发者要与我进行Skype语音。为了防止下载软件占据网速,而影响通信,我不得不暂停下载IE7。 10:45 完成与那名开发者的语音通信。 10:50 由于持续的退信错误,250个报错邮件不能够正常工作。我继续了IE7的下载。放弃删除报错邮件,手动连接Azune并刷新那些设计师之前没有正确上传的图片。 10:55 通过网络服务器继续测试IE7浏览器。查看日志中IE7报错的部分并找到错误发生的原因。 11:00 测试位置出现了新的错误。我发现是由于某一名开发者的原因,如果他能修复错误,测试将会继续进行。我发现缺失图片错误的原因是设计师仍然没有图片添加 到源码中。由于仍然报出大量的错误,Will不得不提醒那名设计师。查看进度服务器(设计师的乐园)上的图片,我发现设计师还是没有上传。我为设计师收集 了一份错误列表,其内容是由于缺少图片而产生的错误。我提取了这些错误,记录在一份Excel中,这里提取的仅仅是关于图片的报告。我创建了一个支持工单 (译者注:support ticket 支持工单系统),并发邮件给设计师。 11:11 回到IE7的错误上。通过查看日志,我找到了错误的原因。 11:16 在日志中找到IE7的错误并下载下来。由于文件比较大,下载花费了一点时间。 11:21 从日志中提取50个IE7的JavaScript代码错误。追踪Excel中的错误并试图减少这50行代码的错误。 11:23 发现错误出现在日志的起始处,而不是最近的记录。我对日志进行时间倒序排序并找到更多的错误。 11:26 不再查找Excel中新加入的错误,仅仅查看现在已经记录下来的。 11:30 第一个错误是无法加载谷歌的网站分析服务。原来又是那可恶的百度搜索引擎。 11:31 在开发过程中修复了下一个错误。 11:32 下一个问题发生在Mac中的FireFox浏览器。我想在上Mac需要建立一个完全单独的测试计划,因此我创建了一个支持工单。 11:35 余下的50个错误都是由于同一个Mac系统的问题,我不得不去找一些较早时间发生的错误。 11:37 在错误搜索中,用“或”取代“与”,并试着取消搜索过程,但无反应。 11:42 一封报错邮件提醒我,测试位置发现字体缺失的问题,我将此问题发邮件给设计师。 11:43 之前的搜索过程被取消,开始重新搜索。 11:45 设计师回邮件说,那些文件出现缺失并非偶然,现在问题已经解决了。 11:46 在等待下一批错误的时候,已发布产品又出现了一个不可思议的IE7错误。我用支持工单记录下了这个错误。如果当初我能有时间(5分钟),我绝不会去考虑其他错误细节。 11:50 最后,通过使用textingbot.com网站去查看IE7的错误,我现在知道为什么IE7不得不被淘汰了。除了提示一个模糊的行数、字符位置信息 和“期望一个标识符,字符串或数字”这类日志中已经有的信息,再也没有什么可用的开发工具可以帮助提供更多的错误信息了。 11:52 借助IE7测试浏览器的“查看源码(View source)”功能和之前记录错误的行数,我发现少了几行。再试一次,提示超时。我想我并没有少了那几行,因为IE7报告有一行没有 JavaScript代码,这个功能一定被行数和空白符(空格、Tab和回车)干扰了。 11:57 我刚注意到某页的中间几段JavaScript时,再次被设计师打断。通过查看这段代码,我发现它们主要负责处理移动端显示的问题。我试着直接在测试服务器上编辑这段代码,看看能不能注释掉这些错误。 12:04 不能直接编辑。由于测试服务器需要密码,网络蜘蛛程序禁止我建立索引。这意味着测试浏览器服务无法进入测试服务器。 12:06 哦!!!我进入测试服务器发现错误还在那里。哦不,测试服务器崩溃了。 12:08 重启IE7的测试并再次执行测试,日志上没有出现任何JavaScript错误。 12:09 删除那些可能有问题的代码的注释,我发现错误再次出现在日志中。接下来要缩小范围查找错误。 12:10 测试服务器又开始无反应,无法刷新页面。启动另一个服务器,并登入,我发现依然会出现错误。注释掉一些代码后,我发现错误是由于最后10行代码。为了 确定,我们将这10行代码页注释掉,发现可以运行了。我们再缩小一下范围,加一些alert函数。IE7再次崩溃。 12:26 一些尝试之后,我重启了IE7测试服务器,我发现了错误的原因。由于一段脚本代码使得IE7崩溃,我想这段代码也可以造成其他浏览器崩溃。这些代码不 算很糟糕,我也不会(太)责备设计师。但是,这些代码本来不应该在任何浏览器上运行,更确切的说,进入到产品运行的环境中。它被嵌入到那页代码的中间部 分。这属于JavaScript代码的问题,设计师用它们做一些黑客行为的事情,比如隐藏移动设备的菜单,而且这些JavaScript代码被藏在一页中 的中间部分。这些代码附近并没有放置测试代码,没人会在最初的快速浏览中发现它们。但它们带来的后果显而易见。 12:30 我在源代码中修复了这个bug,并记录下这个过程。接着,我开始解决其他IE7的bug。它们是。。。 12:34 我意识到,我必须将这段经历告诉开发团队,因为他们都可能会写上面那种代码(除了IE7,哪里都可以运行),而且仍然有相当多的用户在使用着这个功能。 […]
View Details