本人之前很少使用单元测试,总觉得平时的工作写得代码够多了,单元测试还要再编码,增加大量工作量,相信不少程序猿也是这么认为吧。
但是我认为,在必要的时候正确运用单元测试,可以大大缩短代码的调试时间,正所谓磨刀不误砍柴工,在此建议仍不会单元测试的,还是学一下吧。当然本人在单元测试方面还是菜鸟,无论是鸡蛋鲜花都欢迎。
最近公司请微软的人做了一些关于使用VS2012进行单元测试的小培训,小生微做笔记,结合朦胧的记忆,在此自行总结,并分享之。废话少说,先上笔记:
1.先写单元测试(依我愚见,应该是接口先行,如果有的话) -> 测试失败 -> 以最小的改动(即编写实际代码)使测试通过(而在VS2012中已经不能通过现有项目直接生成测试项目了,我觉得这个功能还是应该保留,微软总是这副德行,强迫用户适应他们的产品,但是又不得不适应);
2.不因单元测试而追加功能(代码),即逻辑不受单元测试影响;
3.改变了代码的逻辑(增删改),应及时运行单元测试;
4.在测试方法声明Attribute —— TestCategory("分类或特征名");
5.在单元测试项目添加Fakes程序集分离外部依赖(如数据库访问,获取配置信息等);
6.初始化单元测试类中的成员等信息,可添加方法并声明Attribute[TestInitialize](方法需为public);
7.测试自动化。
以下我将通过自己编写代码来验证上述笔记中的部分要点。有些未涉及,以后再尝试了。
1.新建一个单元测试项目,并添加类XmlSerializationTest,代码如下:
|
|
[TestClass] <span style="color: #0000ff;">public</span> <span style="color: #0000ff;">class</span> XmlSerializationTest { [TestMethod] <span style="color: #0000ff;">public</span> <span style="color: #0000ff;">void</span> TestWriteXml() { UserInfo user = <span style="color: #0000ff;">new</span> UserInfo(); XmlSerialization serialization = <span style="color: #0000ff;">new</span> XmlSerialization(); <span style="color: #0000ff;">bool</span> flag = serialization.WriteXml<UserInifo>(user); Assert.IsTrue(flag); } } |
由于我这个项目是对Xml序列化进行测试,因而前提是项目中已存在了一个UserModel类,并且在单元测试项目中添加相应引用
|
|
<span style="color: #0000ff;">public</span> <span style="color: #0000ff;">class</span> UserModel { <span style="color: #0000ff;">public</span> <span style="color: #0000ff;">string</span> LoginName { <span style="color: #0000ff;">get</span>; <span style="color: #0000ff;">set</span>; } <span style="color: #0000ff;">public</span> <span style="color: #0000ff;">string</span> Password { <span style="color: #0000ff;">get</span>; <span style="color: #0000ff;">set</span>; } } |
接下来在编写实际的代码,微软讲师建议我们先在测试项目编写,待通过单元测试后再将代码移到相应的项目下面。
XmlSerialization
现在整个解决方案结构如下图所示
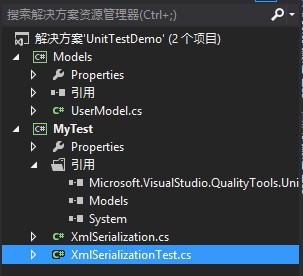
保证整个解决方案生成成功之后点击菜单“测试” -〉 “运行” -〉 “所有测试”,发现测试不通过,于是就按照第一点笔记,以最小改动使测试通过。
修改WriteXml方法为:
|
|
<span style="color: #0000ff;">public</span> <span style="color: #0000ff;">bool</span> WriteXml<T>(T model) { <span style="color: #0000ff;">return</span> <span style="color: #0000ff;">true</span>; } |
运行测试通过。对于返回值为bool的方法,个人建议进行至少两次Assert,也就是分别对返回true和false进行Assert,因而我们再对WriteXml方法添加一个测试方法,
|
|
[TestMethod] <span style="color: #0000ff;">public</span> <span style="color: #0000ff;">void</span> TestWriteXmlFalse() { Assert.IsFalse(<span style="color: #0000ff;">new</span> XmlSerialization().WriteXml<UserModel>(<span style="color: #0000ff;">null</span>)); } |
运行测试,不通过,所以我得要好好改我的代码了,在改动当中坚持执行我的第三点笔记,改动代码及时运行单元测试。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
<span style="color: #0000ff;">public</span> <span style="color: #0000ff;">class</span> XmlSerialization { <span style="color: #0000ff;">private</span> <span style="color: #0000ff;">string</span> filePath; <span style="color: #0000ff;">public</span> XmlSerialization(<span style="color: #0000ff;">string</span> filePath) { <span style="color: #0000ff;">this</span>.filePath = filePath; } <span style="color: #0000ff;">public</span> <span style="color: #0000ff;">bool</span> WriteXml<T>(T model, <span style="color: #0000ff;">string</span> filePath = <span style="color: #0000ff;">null</span>) <span style="color: #0000ff;">where</span> T : <span style="color: #0000ff;">class</span> { <span style="color: #0000ff;">bool</span> result = <span style="color: #0000ff;">false</span>; <span style="color: #0000ff;">if</span> (model == <span style="color: #0000ff;">null</span>) { <span style="color: #0000ff;">return</span> result; } <span style="color: #0000ff;">if</span> (<span style="color: #0000ff;">string</span>.IsNullOrEmpty(filePath)) { filePath = <span style="color: #0000ff;">this</span>.filePath; } XmlSerializer serializer = <span style="color: #0000ff;">new</span> XmlSerializer(<span style="color: #0000ff;">typeof</span>(T)); <span style="color: #0000ff;">using</span> (TextWriter tr = <span style="color: #0000ff;">new</span> StreamWriter(filePath)) { serializer.Serialize(tr, model); tr.Close(); result = <span style="color: #0000ff;">true</span>; } <span style="color: #0000ff;">return</span> result; } <span style="color: #0000ff;">public</span> T ReadXml<T>(<span style="color: #0000ff;">string</span> filePath = <span style="color: #0000ff;">null</span>) <span style="color: #0000ff;">where</span> T : <span style="color: #0000ff;">class</span> { T model = <span style="color: #0000ff;">null</span>; <span style="color: #0000ff;">if</span> (<span style="color: #0000ff;">string</span>.IsNullOrEmpty(filePath)) { filePath = <span style="color: #0000ff;">this</span>.filePath; } XmlSerializer serializer = <span style="color: #0000ff;">new</span> XmlSerializer(<span style="color: #0000ff;">typeof</span>(T)); TextReader tr = <span style="color: #0000ff;">null</span>; <span style="color: #0000ff;">try</span> { tr = <span style="color: #0000ff;">new</span> StreamReader(filePath); model = (T)serializer.Deserialize(tr); } <span style="color: #0000ff;">catch</span> { } <span style="color: #0000ff;">finally</span> { <span style="color: #0000ff;">if</span> (tr != <span style="color: #0000ff;">null</span>) { tr.Close(); tr.Dispose(); } } <span style="color: #0000ff;">return</span> model; } } |
我们发现这个类的构造函数多了一个参数,是对象序列化后保存的路径,且该类对应的测试类都需要用到,因而我希望在每次测试进行单元测试前先将对象的构建,这就是第六点笔记提供的“声明Attribute[TestInitialize]”(注意必须是public方法,我用private方法运行测试是不通过)。改造后的测试类如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
[TestClass] <span style="color: #0000ff;">public</span> <span style="color: #0000ff;">class</span> XmlSerializationTest { <span style="color: #0000ff;">private</span> XmlSerialization serialization; [TestInitialize] <span style="color: #0000ff;">public</span> <span style="color: #0000ff;">void</span> InitTest() { <span style="color: #0000ff;">this</span>.serialization = <span style="color: #0000ff;">new</span> XmlSerialization(<span style="color: #800000;">@"</span><span style="color: #800000;">F:\usermodel.seri</span><span style="color: #800000;">"</span>); } [TestMethod] <span style="color: #0000ff;">public</span> <span style="color: #0000ff;">void</span> TestWriteXml() { UserModel user = <span style="color: #0000ff;">new</span> UserModel(); <span style="color: #0000ff;">bool</span> flag = serialization.WriteXml<UserModel>(user); Assert.IsTrue(flag); Assert.IsFalse(serialization.WriteXml<UserModel>(<span style="color: #0000ff;">null</span>)); } [TestMethod] <span style="color: #0000ff;">public</span> <span style="color: #0000ff;">void</span> TestReadXml() { UserModel user = <span style="color: #0000ff;">new</span> UserModel(); user.LoginName = <span style="color: #800000;">"</span><span style="color: #800000;">aa</span><span style="color: #800000;">"</span>; serialization.WriteXml<UserModel>(user); UserModel model = serialization.ReadXml<UserModel>(); Assert.IsNotNull(model); Assert.AreEqual(user.LoginName, model.LoginName); <span style="color: #008000;">//</span><span style="color: #008000;">路径不存在,应返回null</span> UserModel modelnull = serialization.ReadXml<UserModel>(<span style="color: #800000;">@"</span><span style="color: #800000;">F:\notexists.seri</span><span style="color: #800000;">"</span>); Assert.IsNull(modelnull); } } |
还可以分析测试代码的覆盖率,如下图所示在测试资源管理器点击“运行”下的相应选项。
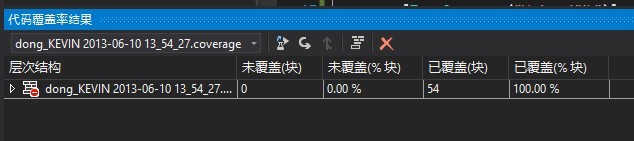
居然是100%,真不知道这个东西微软是怎么分析出来的。
把类XmlSerializationTest移到相应的项目,更改命名空间,在测试项目添加相应引用,测试通过。
将解决方案添加到TFS源码管理,我这边是用的是微软云TFS免费版。
收工。
VS提供了很多类型的测试,负载、UI等等测试,感觉还是蛮强大的。
from:http://www.cnblogs.com/FreeDong/archive/2013/06/10/3129625.html

