对比了最常见的几家开源OCR框架,我发现了最好的开源模型
为什么写这篇文章?
以前看我博客的老粉应该都知道,我从17年开始写技术博客,到今年因为各种原因停更很久,知乎上发的一些技术向文章、教程也是很久之前写的了。一是工作忙,二是我觉得写技术博客救不了年轻人,所以改做视频了。
最近还算有空,上一期视频又刚好用到了OCR的工具,出于一个写了三年博客的人的习惯,我还是决定记录一下这些使用记录,供大家参考。
OCR介绍
什么是OCR?OCR当前的常用技术?
说到OCR,我提个广告大家肯定都熟悉“小猿搜题,拍照搜题的利器”。这就是OCR在O2O教育领域的一个完美应用。

从严格定义来看,学字符识别(Optical Character Recognition, OCR)是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。亦即将图像中的文字进行识别,并以文本的形式返回。
OCR的基本流程可以简单分为以下几步:
1. 输入:不同的图像格式有不同的存储、压缩方式,目前有OpenCV、CxImage等。
2. 二值化:如今数码摄像头拍摄的图片大多是彩色图像,彩色图像所含信息量巨大,不适用于OCR技术。为了让计算机更快的、更好地进行OCR相关计算,我们需要先对彩色图进行处理,使图片只剩下前景信息与背景信息。二值化也可以简单地将其理解为“黑白化”。
3. 图像降噪:对于不同的图像根据噪点的特征进行去噪的过程称为降噪。
4. 倾斜校正:由于一般用户,在拍照文档时,难以拍摄得完全符合水平平齐与竖直平齐(我本人就经常拍的歪歪扭扭),因此拍照出来的图片不可避免的产生倾斜,这就需要图像处理软件进行校正。

5. 版面分析:将文档图片分段落,分行的过程称为版面分析

6. 字符切割:由于拍照、书写条件的限制,经常造成字符粘连、断笔,直接使用此类图像进行OCR分析将会极大限制OCR性能。因此需要进行字符切割,即:将不同字符之间分割开。

7. 字符识别:早期以模板匹配为主,后期以结合深度网络的特征提取为主。版面还原:将识别后的文字像原始文档图片那样排列,段落、位置、顺序不变地输出到Word文档、PDF文档等,这一过程称为版面还原。
8. 后期处理:根据特定的语言上下文的关系,对识别结果进行校正。
9. 输出:将识别出的字符以某一格式的文本输出。

以上9步也可以简单总结为

图像预处理和一般的cv流水线没太大差别,基本就是降噪矫正加强老三样。而目前OCR的常见算法模型则迭代的比较迅速,包括文字检测领域的2016 ECCV乔宇老师团队的CTPN,2017 CVPR的EAST和Seglink,感兴趣可以看论文继续了解。文字识别近两年则没有太大进展,有两种传统方法,一种是CNN+RNN+CTC,白翔老师团队的CRNN写的比较清楚,还有一种是CNN+RNN基于Attention的方法。
值得一提的是,OCR这块最近有个比较火的方向,直接把文字检测和识别放到一个网络里joint train,沈春华老师团队2017 ICCV的Towards End-to-end Text Spotting with Convolutional Recurrent Neural Networks这篇文章已经在水平文字上把检测识别end to end做的比较work,感觉这可能是未来一两年的一个热点。
说完算法,下面具体谈谈一些OCR的常用工具和平台。毕竟大多数使用者(包括我)90%的工作就是调包,比如
import paddleocr as ocr

不过调侃归调侃,除非是专门研究这个领域的科研同学,作为OCR使用者,其实大致了解即可,深入算法的性价比不高。与此相对的,如何选择一个可靠、易用的OCR框架则是我们要面临的主要问题。
这种选择本质上像是深度学习界的框架之争,但其实并没有哪个框架是绝对好的,各有优劣。所以,如何选择一个适合自己的OCR框架并深入应用,也是一门艺术。
为了完成自己的需求,我先后尝试了4种不同的OCR框架/Toolkit

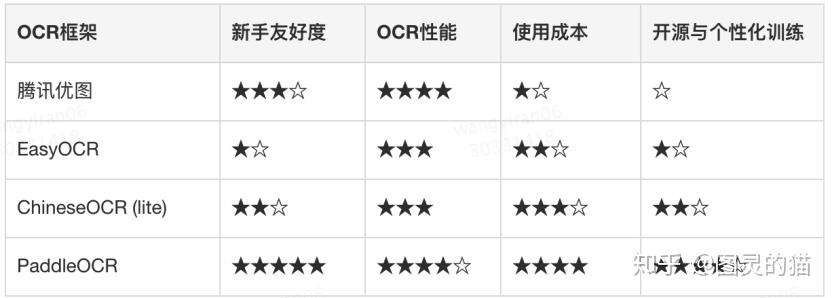
这里根据自己的使用经验,我把所有信息封装到以下4个方面:新手友好度、OCR性能、使用成本、个性化训练,做个简短比较,方便大家之后选择适合自己的OCR工具。
PS. 使用成本的★越多代表成本越低
1. 腾讯优图
先讲讲OCR这块做的最早,也是商业化最成功的平台之一,腾讯优图。
地址:https://cloud.tencent.com/product/ocr-catalog

新手友好度(★★★☆)
文档在官网就有,分成了两个部分:
一个是新手指引,教你怎么注册腾讯云,以及开通对应的OCR服务。这里有一点做的比其他几家要好,就是它将用户分为了四类来分别作引导,分别是无代码基础、开发初学者、开发工程师和客户端开发,每一类都有单独的文档链接供不同的用户浏览。
另一个是入门指引,也就是通过新手指引的不同分类中跳转到详细的分页。这里要吐槽一下,入门文档的前半部分和新手指引一字不差,复制粘贴还不如不加。

我因为有开发经验,只需要调用API,所以选了第二种引导。里面写的还是非常详细的,一步一步教我怎么开通、调用腾讯的API。FAQ写的也很全,总体来说对新手很友好。

OCR性能(★★★★)
优图这边采用全API调用,也就是没法用自己的测试集去直接离线跑模型的accuracy、recall这类指标。但是作为优图实验室出品的商业化OCR,模型指标和参数之类的肯定已经tune到极致了,这点没得说。

使用成本(★☆)
使用成本可以分为时间成本和金钱成本来看:
- 时间成本
有点我始终没想明白,为什么试用一下OCR功能还要实名认证,不仅要注册、手机验证码,还要身份证/人脸识别???这些步骤让我想起每去一个地方就要重新注册一个健康码的糟糕体验,建议腾讯优化一下这个劝退操作。
除了认证复杂,其他体验还不错。因为是调用API,所以开发的时间成本很低,照着demo代码改改就行。但是腾讯云必须要注册并实名认证之后才能使用,此外还要领免费包或者购买资源包,这点花了我不少时间。
根据OCR任务的不同(比如身份证识别、银行卡识别),用户需要修改发送的请求参数格式。格式的细节在文档里列的很清楚,倒也算方便。需要注意的是,返回的报文也有不同的参数模式,解析的时候也要改。
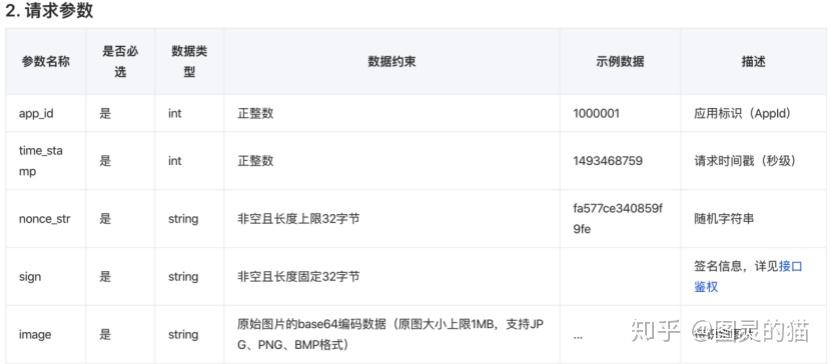
- 金钱成本
商业化的OCR肯定是要付费的,说实话价格不便宜。对于有大量高精度识别需求的企业来说自然不差这点钱,但是我等穷苦开发者,想想还是作罢。

开源与个性化训练(☆)
首先,优图OCR不开源,除了商业化的考量,应该也涉及到自己实验室的算法专利、隐私数据等,不开源属于情理之中。但是对于想要自己DIY或者训练精调模型的开发者来说就比较蛋疼了,除了调个API你什么都动不了,连内部的实现方法都看不到,所有识别也只能基于官方给出的8个固定类型,自由度很低。
总结:高精度、高价格、对非技术新手友好、不支持开发、注册流程复杂
综上,优图作为一个完善的商业化OCR平台,日常的功能基本都满足,OCR模型的准确度也非常高。但是因为我需要做一些OCR的定制化开发,而优图又只支持API调用,所以最后无奈放弃。
2. EasyOCR、Chineseocr、Chineseocr_lite
这三个OCR开源工具是Github里包含中文OCR功能的,排序相对靠前的两个项目,star也都很多。这里我把它们放在一块讲,一是因为这两个开源工具包都比较相似,二是EasyOCR是全语种的(包括70+门外语识别),不单单针对中文,所以它的官方文档自然也都是英文了。对于英文不好的小伙伴来说很不友好。所以这里主要还是基于Chineseocr_和Chineseocr_lite,会提及到EasyOCR
新手友好度(★★☆)
Github的文档可能非技术的同学看起来比较费劲,但是对开发同学来说一目了然。编译配置之类的信息,也都写的很清楚

FAQ的话直接在issue里找也基本能覆盖所有常见问题,如果实在找不到可以自己提一个,会有其他follow的用户一起讨论。
不过这种自发、开源的工具,就不要指望有腾讯那种事无巨细的产品文档了,细节不会写的非常清楚。比如我在安装过程中,一度出现了很多BUG,但找不到对应解决方案,只能自己摸索。

属实挺头疼的,建议新手找个有开源库编译经验的帮忙搭建环境。
OCR性能(★★★)
这里基于github上训练好的模型做测试,不进行二次训练,不过项目里有提供训练数据的百度网盘下载,有资源的同学可以自己跑跑看。
具体到模型本身的收敛速度、训练指标和鲁棒性等指标,都可以从官方文档中获取,这里只观察测试性能:

通过搜集来的几个不同OCR测试数据集(github上有很多现成的,包括生成数据集、现实数据集等)随机选1000张图片来测试。
模型指标(单字符):
推理性能:EasyOCR的测试速度较慢,lite的独特之处则在于它很轻快,不管是模型大小还是推理时需要的内存。因此可以把lite定义为一个轻量级中文OCR,支持竖排文字识别、NCNN推理,识别模型型仅17M(Psenet (8.5M) + crnn (6.3M) + anglenet (1.5M))
可以看到,200张图片测试稳定在1-1.5G左右的内存
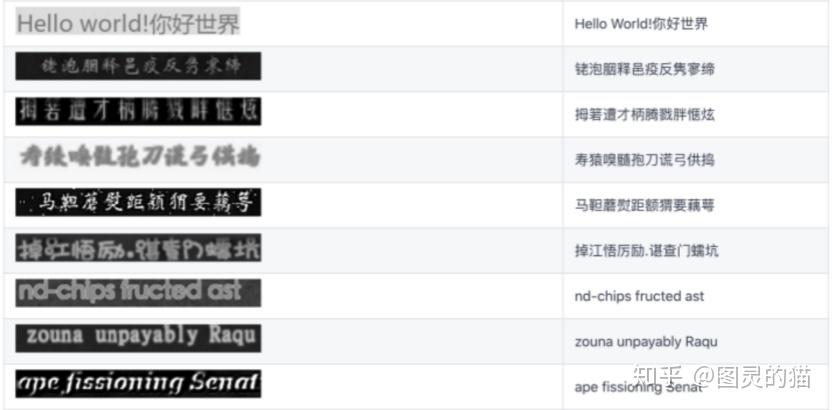
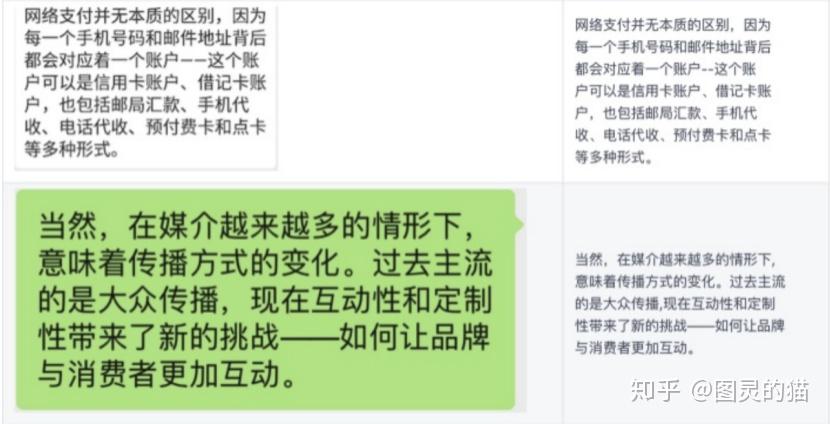
这里通过测试集里的结果可以看到两个模型的识别准确率还是挺高的。不过前提是图片数据都相对清晰,对比度也高。针对复杂场景,鲁棒性就不如其他OCR工具了。这里单独选几个不同场景的使用的图片做样例测试:


单字符识别的准确率的确挺高的。但是也会有一些badcase,主要出现在EasyOCR上,比如下面这个,可能是模型刚好对这几个字的识别率不高,总之不够泛化。


值得一提的是,lite可以比较方便的部署在web/app上,Easyocr则只能linux/windows下运行。此外还有个问题就是Chineseocr_lite虽然简单文字的识别准确率比Easyocr高,但是对于一些复杂的、不常见的字符,比如德语、法语中的é è à â ê û î ô这类字符会出现无法识别的问题,因此个别应用场景会有缺失。
使用成本(★★☆)
Chineseocr_lite不支持pip,因此对于不熟悉github的同学,时间成本相对会高点,因为还要git clone和熟悉仓库的用法。其他的成本则主要集中在开发上。
对于EasyOCR来说,本地环境下安装方便,直接pip就行。如果直接调用API则是复用老一套流程,不会很复杂。

对于有训练和开发需求的用户来说,采用开源版本的OCR框架,成本主要是环境搭建上,因为需要自己安装pytorch,web,GPU版本还需要安装正确版本的CUDA+cuDNN,这部分比较容易出BUG。众所周知debug很耗时间。
金钱成本则基本没有(除了电费),如果大批量的跑字符识别可能需要搭建GPU服务器,这个花费就因人而异了。如果只是几万量级的小规模使用,一般的本地环境都可以。
开源与个性化训练练(★★★★☆)
这两个框架本身都是开源的,算法出自哪个paper都写的很清楚,不管是看源码还是改接口,都可以找到对应的参考资料。
EasyOCR还专门给出了一个框架图来帮助理解。可以看到基本pipeline的流程还是基于常见的预处理、crnn识别等。
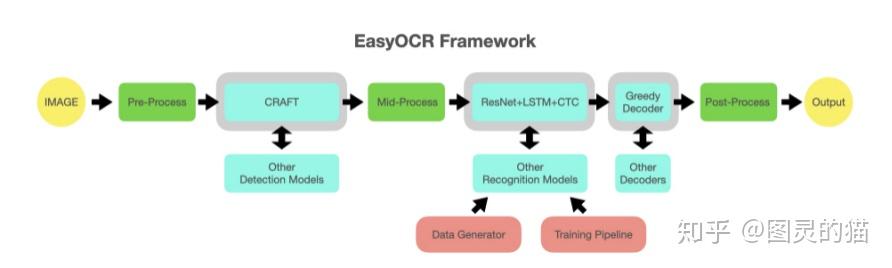
如果要做个性化的话,Chineseocr框架相对来说非常方便,只需要修改对应模块的函数就可以,因为本身这些模块其实就是可扩展的,比如后续pull request到项目里的lstm推理和ncnn核扩展

此外也可以看到lite的现有功能都是通过一次次的更新加上去的,虽然没有直接支持个性化训练,但不少功能也是用户自发contribute的。想要订制自己的轻量化ocr流水线,可以直接基于当前版本做扩展开发,如果自己测试结果无误,可以直接提pr,成为开源ocr项目的贡献者,岂不美哉?

总结:开源免费、不需要注册和认证流程、可扩展性强、识别率相对高;缺点则是对开发能力有一定要求,需要熟悉搭建环境和开发。这一点见仁见智吧。
综上,虽然easyocr和liteocr很好,但我觉得还是缺了点可靠性,毕竟都是从一个小demo发展起来的项目,背后没有实验室和开发团队背书,模型的更新和维护也只能靠自觉。所以在测试完后我并没有直接使用,留作备选。
3. PaddleOCR
再看看github上排第三的PaddleOCR。飞桨之前我是用过的,毕竟国内能拿的出手的机器学习框架就那么几个。出于这个原因我尝试了一下这个paddlepaddle框架下开源的高精度文字识别模型套件PaddleOCR。看到这大家可能就明白了,开源、高精度,这两点基本就是优图和EasyOCR的结合体了。
没人,比我,更懂,OCR(飞桨:正是在下)
新手友好度(★★★★★)
先看官方文档,首先要表扬一点,其他几个OCR工具都是默认用户知道OCR是什么以及具体的定义和应用,但是作为技术文档,应该有规范化、学术化的编写要求,连《同济线代》上来都会讲一下什么是行列式,前面几个ocr的文档等于直接教你怎么高斯消元,虽然学过线代的都能看懂,但观感上有点跳。建议其他厂商都学一下廖雪峰的文档结构,尽量把是什么先讲了,再说怎么做。
相较之下,PaddleOCR的文档倒让我想起我以前看过的机器学习类教材,从OCR的定义、场景、数据集加载、模型loading、预测、部署到实例demo,完完全全按照正常用户的pipeline流程来写,非常简明扼要,没有一句多余的话。比商用OCR的事无巨细模板式教程和开源OCR的不明就里跳跃式文档教程好很多。此外我的主观感受是文本的排版和图片的选择都比较符合我的审美,不会有阅读障碍。
此外所有的步骤,从定义数据到加载模型,只要涉及到代码,全都用Notebook的格式给了示例(包括所有输入和输出),连怎么pip安装都贴上来了。


有一说一,以前上机器学习理论课的时候,我们教授要是能这么仔细地手把手教,也不至于有人挂科了(狗头)
出于习惯我还是去翻了翻他们的Github,发现写的很简洁,估计是知道github用户就好这一口。内容上和ChineseOCR差不多,readme里只说明了pipeline和模型效果,具体的文档还是得跳转回官方网站。
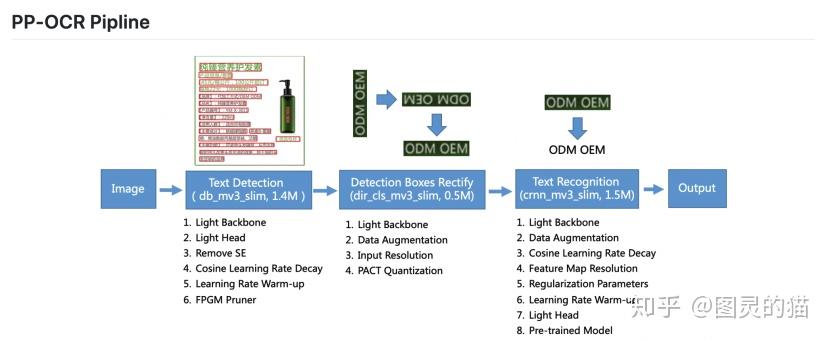
对于想深入算法细节的同学,文档里也给出了非常清晰的paper模型结构和算法细节。不过建议还是去读原论文:https://arxiv.org/abs/2009.09941
这里最有趣的是在B站,PaddleOCR有官方的教学直播和视频资料(直播现在结束了,之后应该还会有,毕竟最近又更新了一波),自然比一般的文字教程更好,看得出paddlepaddle是真心想推广自家的工具,思路上也更加年轻化。这一点比其他平台好很多。

OCR性能(★★★★☆)
先说一点,PaddleOCR开源的是经过产业实践考验的的超轻量中英文OCR模型,在arxiv也有具体的paper,详见论文PP-OCR,:

至于性能如何,可以参考下图:
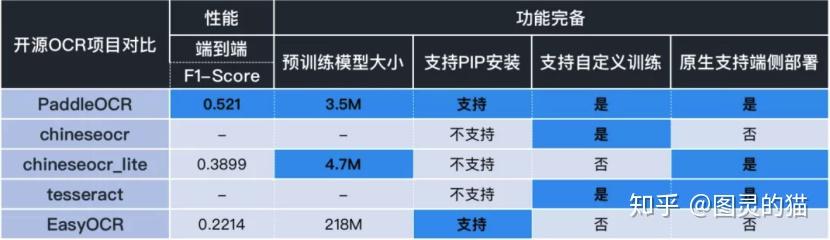
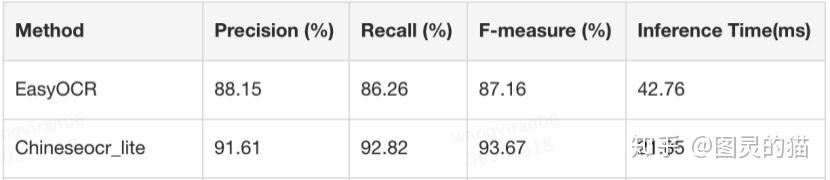
端到端的文本级F1-score比最好的开源工具高了13.11PP。保险起见我用之前的1000张测试图片又做char-wise的识别性能对比:
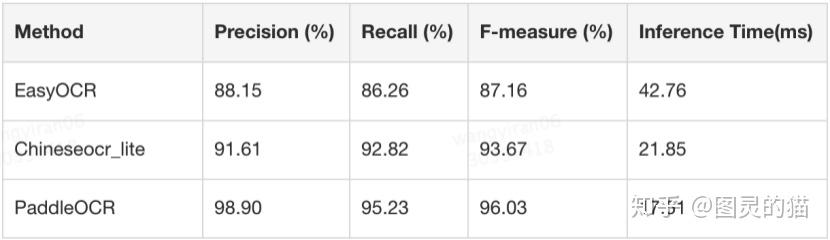
confidence卡0.99的情况下,可以看到PaddleOCR三个指标都赢的很明显。不过图片的类型、分布会影响指标,加上测试集文字单一、数据量小,因此只能说明在这个小数据集里PaddleOCR的效果最好,不具有广泛的参考意义。
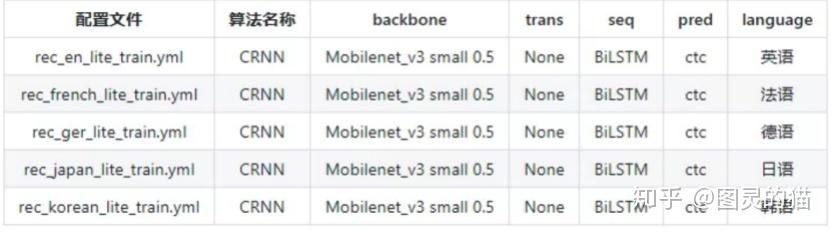
此外,就应用场景的泛化性能来看,语种识别上PaddleOCR目前包括中英文、英文、法语、德语、韩语、日语,要多于Chineseocr_lite,但明显少于EasyOCR,不过就常见的外语和特殊字符识别来说已经完全够用了。
对于普通场景来说,比如身份证识别、票据识别,其实大多数算法的准确率都不错,但特殊场景更考验模型的泛化性能。相较而言PaddleOCR至少在检测能力上比其他几个开源工具要好,但识别能力仍有待提升。当然,这是数据和算法层面的瓶颈,学术界暂时也没有特别好的解决方法。
既然之前用过chineseocr_lite,顺便也说说PaddleOCR的模型大小和推理性能。这块PaddleOCR的兄弟产品模型压缩套件PaddleSlim提供了强大的技术支持,为PaddleOCR超轻量化模型的提供依赖支撑。先看下效果:

整体的压缩流程就是集成模型剪枝、量化(包括量化训练和离线量化)、蒸馏和神经网络搜索等业界常用且领先的模型压缩功能。从超轻量模型8.1M直接压缩到3.5M,模型大小降低了56.79%,其中检测模型速度提升21%,而且整体模型精度还有一定提升。
啊这。。。一般写论文都是把模型堆的越大越好,指标越高越好,因为这俩往往是正相关的。但是同时优化了模型大小和指标,还优化了如此之多的,基本也接近best paper的水准了(GPT-3表示不服)。
话说回来,我原先以为OCR是个很简单的领域,检测识别撸一套就行了,看来是自己坐井观天了。

使用成本(★★★★)
我分别尝试了网页、API调用和服务端三种不同的OCR方式,基本都是几分钟搞定,不做敏捷开发的话完全没有使用成本,这主要得益于文档和代码的完整注释。金钱成本的话因为是开源所以免费。
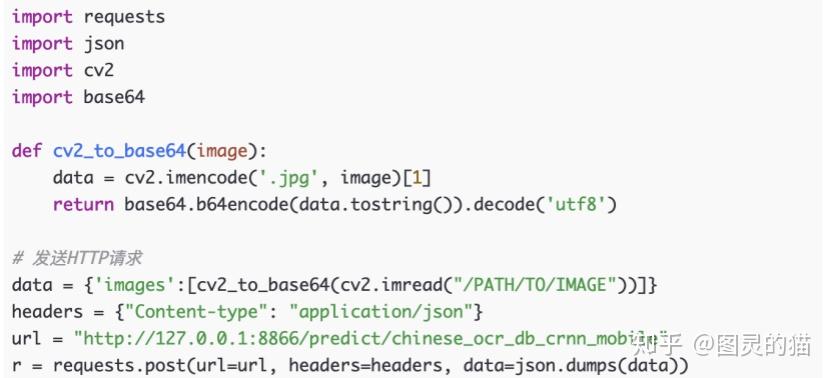
这里特别提一下,移动端部署PaddleOCR可以非常方便的同时支持移动端(iOS和安卓)和PC端,在手机平板上也可以很好的接入和使用。对比其他的开源OCR工具,它只需要一行代码:

然后在客户端通过http请求直接调用,只需要以下几行代码就能搞定
手机端部署效果如下(动图)

开源与个性化训练(★★★★☆)
这一点对我来说比较重要,这也是我只考虑开源框架的原因之一(另一个原因是没钱)。目前复杂的实际业务场景中,预训练模型往往不能满足需求,对于自定义训练和模型Finetuning,目前只有开源框架支持,但不管是EasyOCR还是chineseocr_lite,泛化性和稳定性都不尽如人意。无疑PaddleOCR是最合适的。
官方给到的训练集非常全,也有常用的合成、标注工具。基本满足个性化训练的场景应用,不需要再自己花时间找,一键下载就行。

这边关于自己开发预训练模型,官方也给了点有趣的思路。虽然当Porn和hub同时出现在一起,总会有种看错了的感觉。

如果使用自己的backbone做开发和训练,FAQ里也写的非常详细。并且给出了117个不同预训练模型的下载地址。

对于个性化训练中可能出现的bug和问题,这里也都给了答案
一般来说文本检测需要的数据相对较少,在PaddleOCR模型的基础上进行Fine-tune,1000张以内即可达到不错的效果。文本识别分英文和中文,一般英文场景需要几十万数据可达到不错的效果,中文则需要几百万甚至更多。所以对于有个性化开发需求的用户,还是会需要比较多的数据资源和算力资源。
评分汇总(使用成本★越少代表成本越高)
最后,对于一个开源工具库来说,及时、有效的更新反馈是非常难得的,包括EasyOCR,Chineseocr_lite和PaddleOCR在内,都是很多用户自发的contribute,整体项目的优化也来自算法的不断更新维护。这一点是开源社区最让人喜欢的原因之一。
至于商用,一般选择头部平台,如腾讯阿里百度等,效果和稳定是第一位,售后和客服也比较规范化。个人使用时则会面临成本过高的问题,这一点见仁见智吧。就目前已有的几个框架来说,有大厂背书,也有开源优势的PaddleOCR无疑会适用于更多场景需求,也更适合初学者入门。
在我看来,每个工具都各有所长,没有哪个真的一无是处,也没有哪个完美无缺,我理想中的工具应该是4个五星,显然这几个都不满足,不过我相信随着算法和工程体系的不断进步,以后一定会出现更好的OCR框架,毕竟从0到1的一步已经走过了。
参考文献
- Ding, Haisong, Kai Chen, and Qiang Huo. "Compressing CNN-DBLSTM models for OCR with teacher-student learning and Tucker decomposition." Pattern Recognition 96 (2019): 106957.
- Li, Hui, Peng Wang, and Chunhua Shen. "Towards end-to-end text spotting with convolutional recurrent neural networks." Proceedings of the IEEE International Conference on Computer Vision. 2017.
- Yuning Du, Chenxia Li, Ruoyu Guo, PP-OCR: A Practical Ultra Lightweight OCR System, arXiv:2009.09941
- https://github.com/JaidedAI/EasyOCR
- https://github.com/ouyanghuiyu/chineseocr_lite
- https://github.com/PaddlePaddle/PaddleOCR
- yolo3 https://github.com/pjreddie/darknet.git
- crnn https://github.com/meijieru/crnn.pytorch.git
- ctpn https://github.com/eragonruan/text-detection-ctpn
- CTPN https://github.com/tianzhi0549/CTPN
- keras yolo3 https://github.com/qqwweee/keras-yolo3.git
- https://www.cnblogs.com/shouhuxianjian/p/10567201.html
- 语言模型实现 https://github.com/lukhy/masr
- https://www.zhihu.com/question/20191727/answer/213710084
- https://zhuanlan.zhihu.com/p/150704536
- https://ai.qq.com/doc/ocrgeneralocr.shtml
- https://cloud.tencent.com/document/product/866/33526
- https://mp.weixin.qq.com/s/6yJU
from:https://zhuanlan.zhihu.com/p/265359676?utm_id=0