MySQL:创建高性能的索引
一、索引基础
定义
索引,也叫做“键(Key)”,是存储引擎用于快速查找记录的一种数据结构。索引对于良好的性能非常关键,索引是对查询性能优化最有效的手段。
索引类型
1.B-Tree索引
当人们谈论索引的时候,如果没有特别指明类型,那多半说的是B-Tree索引,它使用B-Tree数据结构来存储数据。B-Tree通常意味着所有的值是按顺序存储的,并且每一个叶子节点到根的距离相同。
B-Tree索引的几个匹配原则:
a.全值匹配:和索引中的所有列进行匹配。
b.匹配最左前缀:即索引的第一列。
c.匹配列前缀:即只匹配某一列的值的开头部分。
d.匹配范围值。
e.精确匹配某一列并范围匹配另外一列。
f.只访问索引的查询,即:覆盖索引。
B-Tree索引的几个限制(索引失效):
a.不是按照索引的最左列开始查找,则不能使用索引。
b.不能跳过索引中的列。
c.如果查询中有某个列的范围查询,则其右边所有列都无法使用索引。
2.哈希索引
哈希索引(hash index)基于哈希表实现,只有精确匹配索引所有列的查询才有效。在MySQL中只有Memory引擎显式支持哈希索引。我们在这里只作了解。
3.R-Tree索引
R-Tree索引(空间数据索引),可以用作地理数据存储。MySQL中目前仅MyISAM引擎支持。与B-Tree不同,此类型的索引无须前缀查询。必须使用MySQL的GIS相关函数来维护数据,但遗憾的是MySQL的GIS支持并不完善。
4.全文索引
全文索引是一种特殊类型的索引,它查找的是文本中关键词,而不是直接比较索引中的值。全文索引更类似于搜索引擎做的事情,而不是简单的WHERE条件匹配。
二、索引的优点
优点:
1.索引大大减少了服务器需要扫描的数据量。
2.索引可以帮助服务器避免排序和临时表。
3.索引可以将随机I/O变为顺序I/O。
什么样的表需要使用索引?简单的说应该遵循以下3条准则:
1.非常小的表:全表扫描更高效。
2.中到大型表:索引非常有效。
3.特大型的表:创建和使用索引的代价非常高。如果表有大量插入和更新,更新索引将是很大的一个开销。对于特大表,建议使用表分区技术,分区后再使用索引。
三、高性能的索引策略
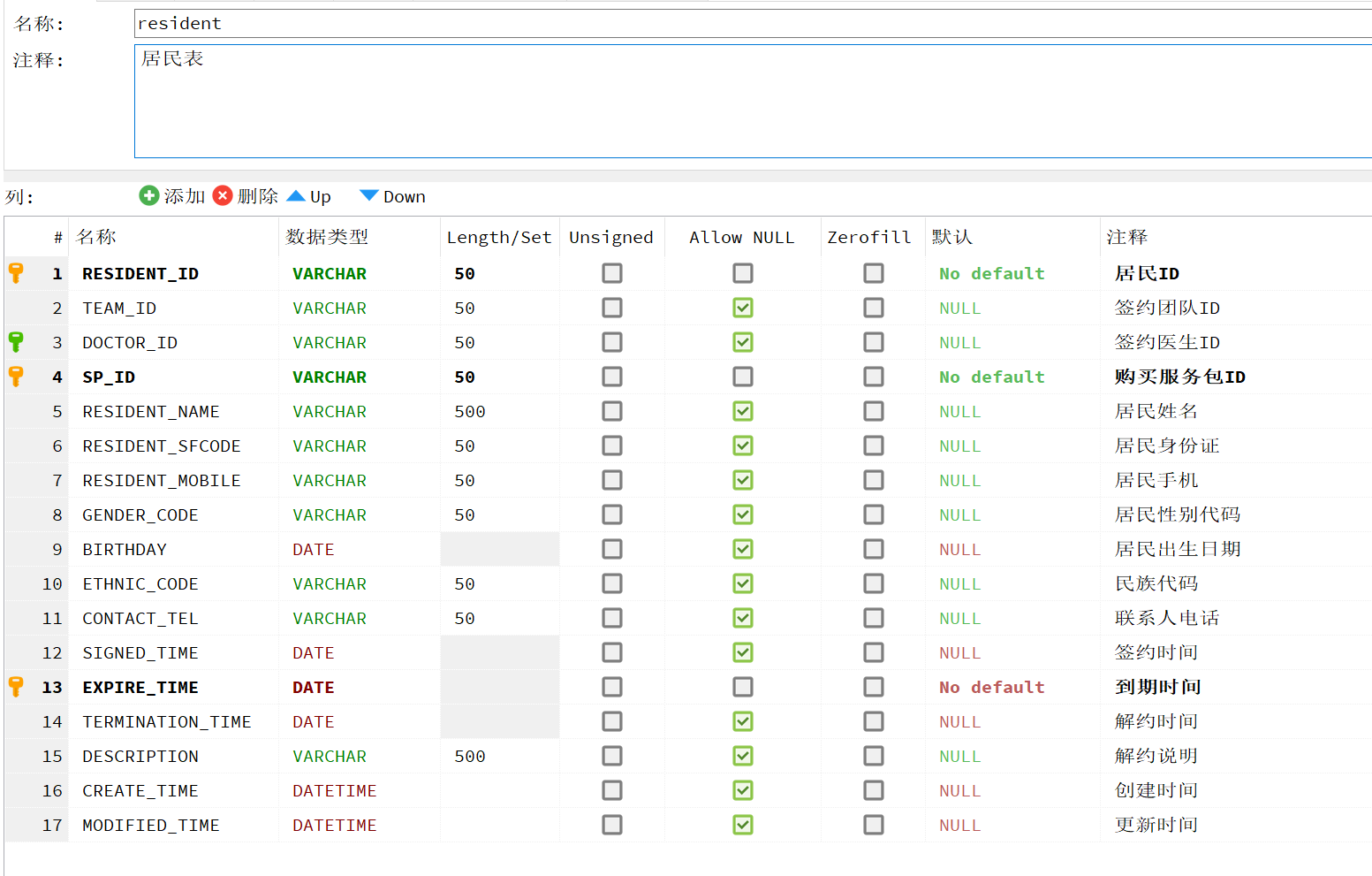
示例以【居民表:resident】为例,以下是此表的结构:
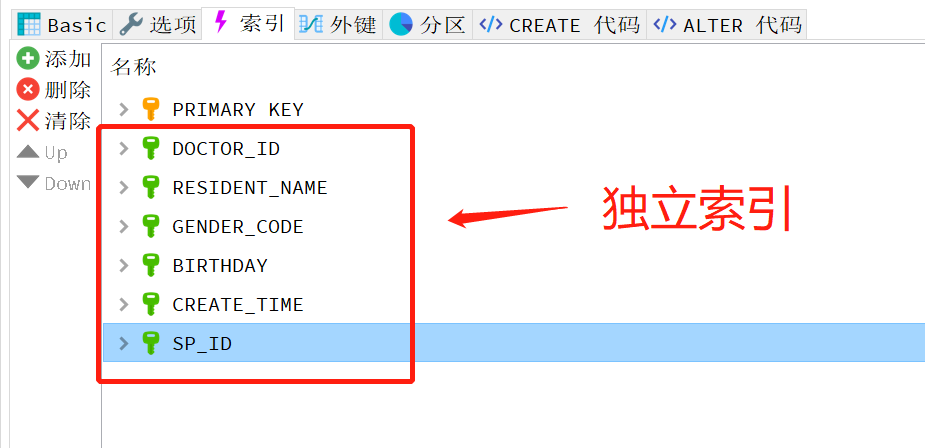
1.独立的列
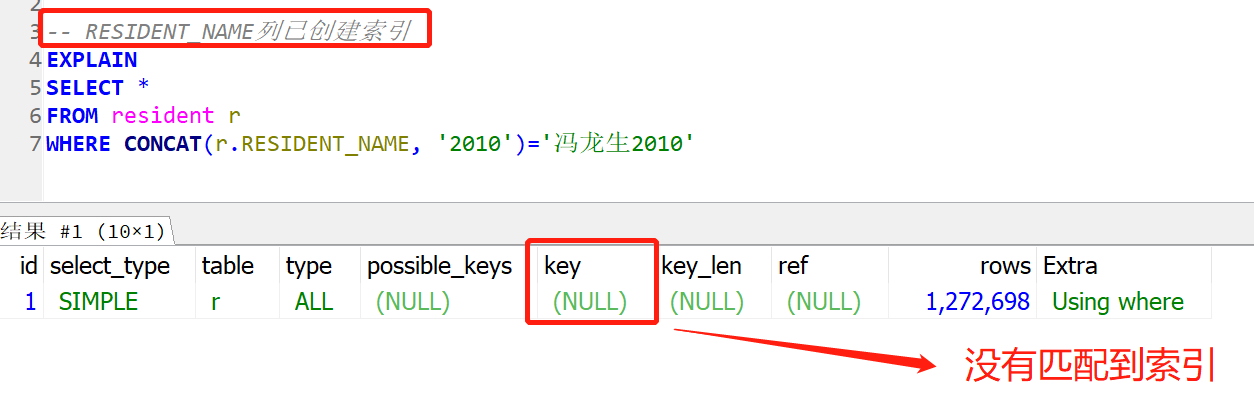
独立的列是指索引列不能是表达式的一部分,也不能是函数的参数。
反例:
2.前缀索引和索引选择性
前缀索引:如果需要索引的字符列很长,这会让索引变得大且慢。通常可以只索引此列开始的部分字符。这样可以大大节约索引空间,从而提高索引效率。
索引选择性:是指不重复的索引值和数据表的记录总数的比值。此值越高,索引效率越高。例如:唯一索引和主键的索引选择性是1,性能也是最好的。
索引选择性是创建前缀索引依据。
例子:给列RESIDENT_NAME加索引,varchar(500)显然太长了,我们用前缀做索引。
先计算完整列的选择性:0.4867
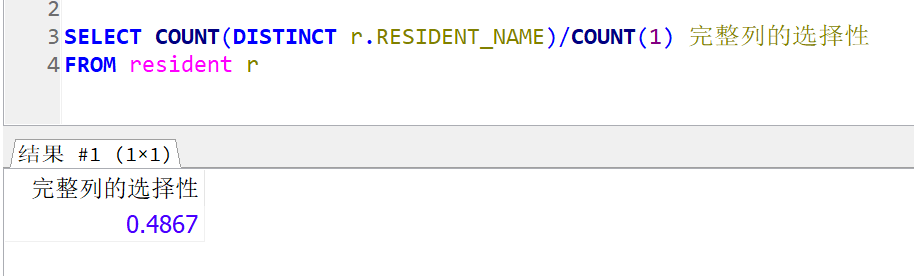
再计算最接近的前缀选择性,可以看到15个字符后,20个字符也是0.4867,因此15个字符作为前缀是最合适的。
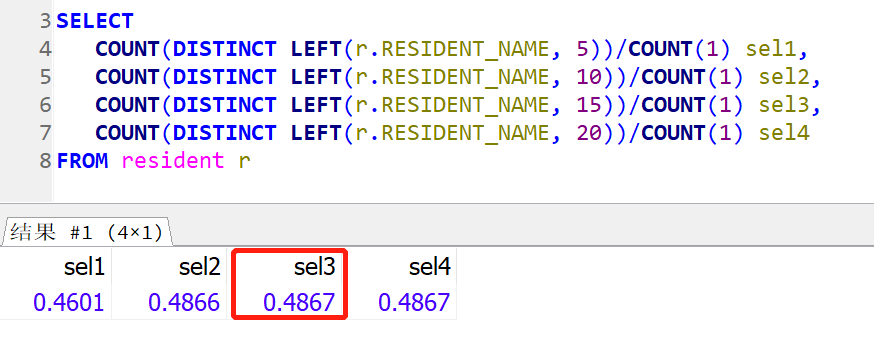
最后创建索引:

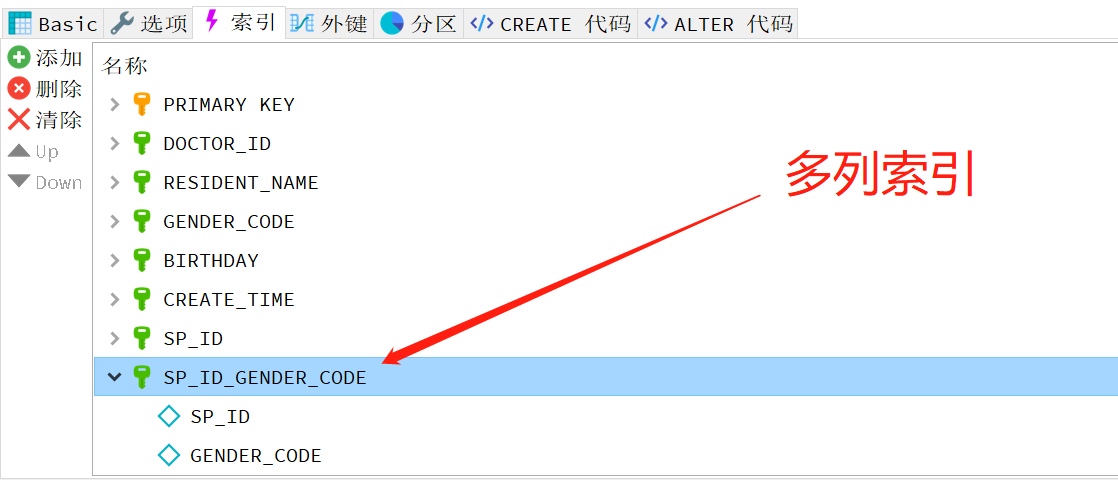
3.多列索引
很多人对多列索引的理解都不够。一个常见的错误是:为每个列都创建独立的索引;另一个是按照错误的顺序创建多列索引。
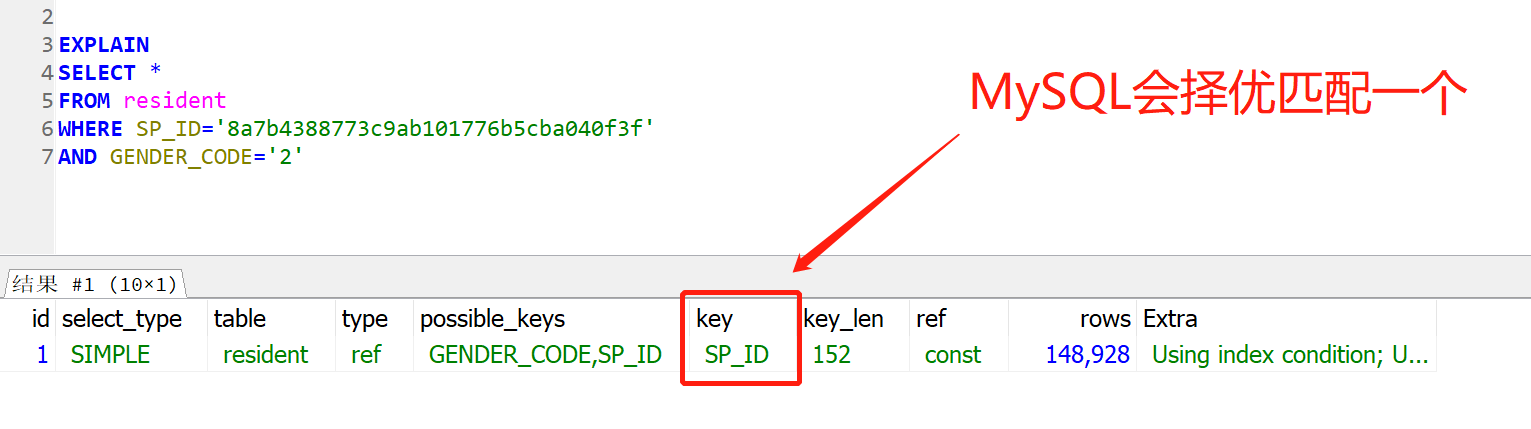
反例:独立索引对多条件查询的性能提升是很小的,一般只能匹配到一个索引,效率肯定要大打折扣的。
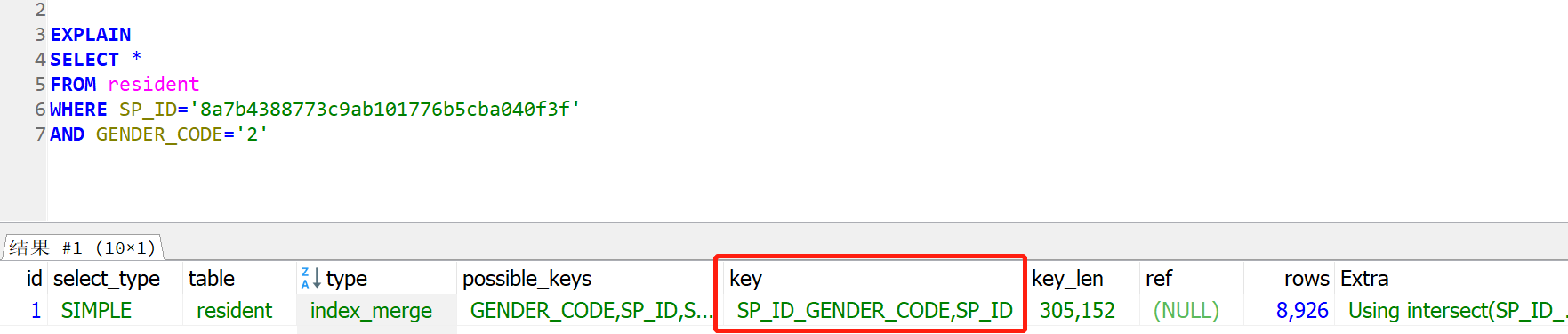
正例:创建一个多列索引,扫描的行数马上降了下来,快了十几倍,这还只是个简单的示例。
4.选择合适的列顺序
最让人困惑的问题莫过于索引列的顺序,正确的顺序依赖于使用该索引的查询。也要考虑到排序和分组的需要。
例子:是什么让我决定以SP_ID在前创建了上面的多列索引:SP_ID_GENDER_CODE ? 答案是:计算各列的选择性。
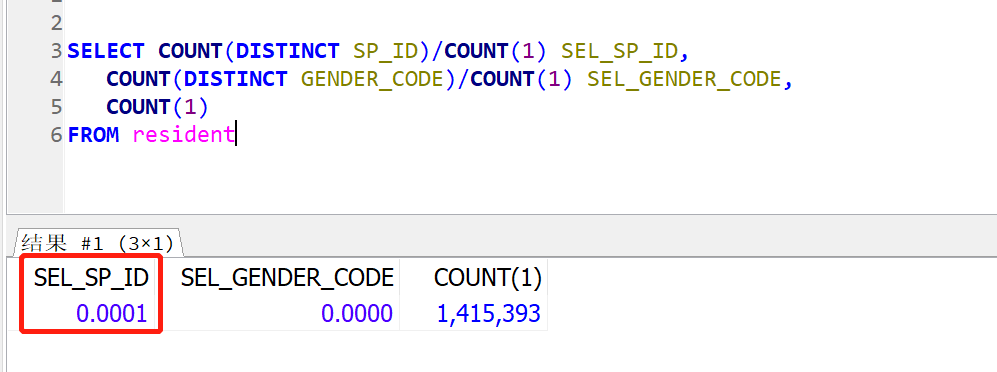
5.聚簇索引
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。InnoDB的聚簇索引实际上在同一个结构中保存了B-Tree索引和数据行。主键就是一个典型的聚簇索引。
6.覆盖索引
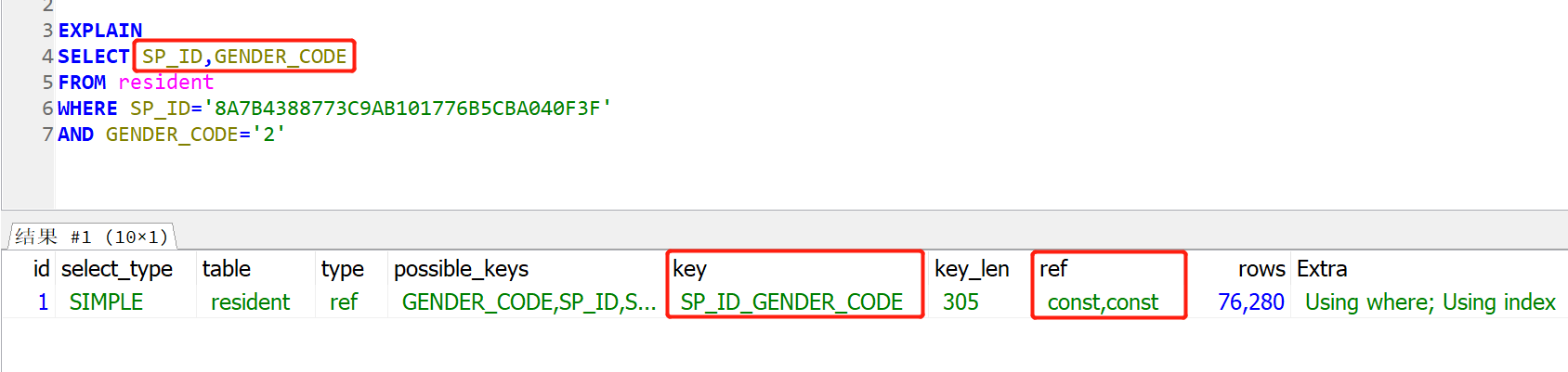
如果一个索引包含要查询的所有字段,不需要再去表里读取数据,这样的索引就叫做覆盖索引。覆盖索引能极大的提高查询性能。
例子:把查询中需要的字段改为索引中的字段时,这样一个覆盖索引就形成了。索引也只匹配到多列索引,ref也变为了常数。Extra也显示了Using index。
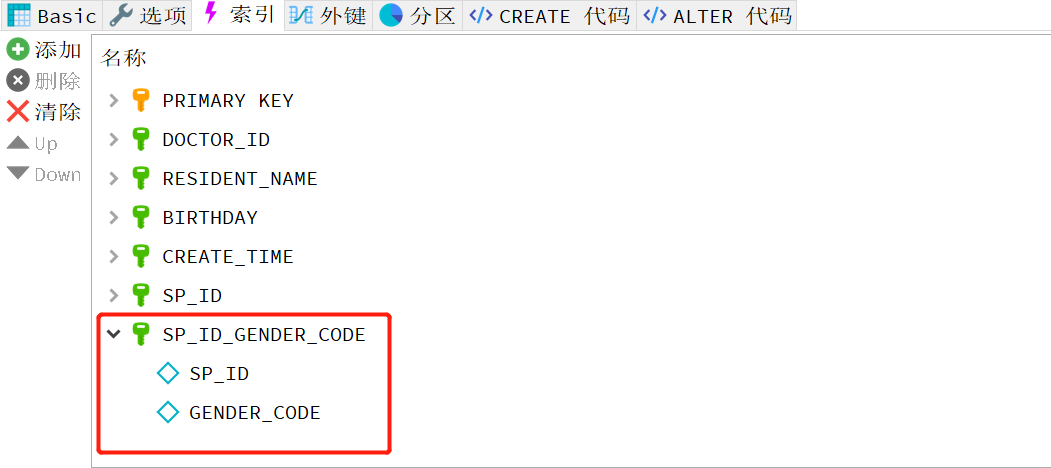
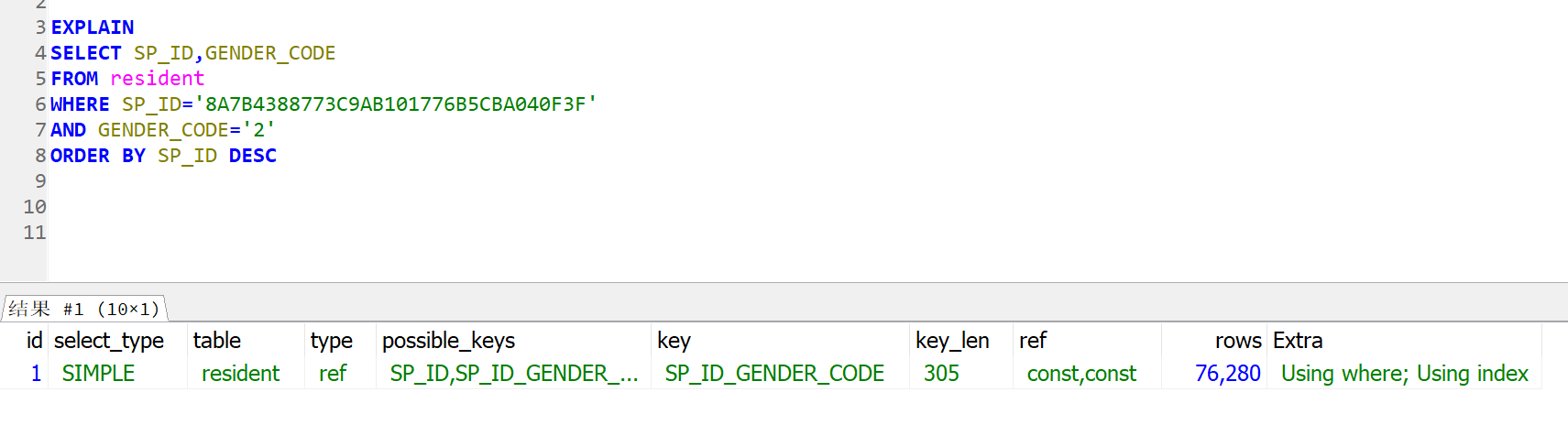
7.用索引做排序
可以用同一个索引既满足排序,又用于查询。这样的索引是最优的,历为我们日常工作中遇到查询一般都是要排序的。这里有个限制:如果查询涉及到多表联合,排序用的字段必须全部是第一个表的,才能使用索引做排序。
例子:
8.冗余和重复索引
重复索引:是指在相同的列上按照相同的顺序创建的相同类型的索引。避免出现这样的情况,发现要删除。
冗余索引:是指一个或多个列同步出现在多个索引中,各索引的列数、顺序不同。冗余索引也应避免。但有时查询写的不合理,可能出现单独为优化某个查询出现的冗余索引。
P.S 创建冗余索引时可能影响其他索引的匹配,从而导致以前的查询性能降低。
四、索引案例
索引 index(a, b, c)
| where 语句 | 索引是否被使用 |
|---|---|
| where a=3 | Y,使用到 a |
| where a=3 and b=5 | Y,使用到 a,b |
| where a=3 and b=5 and c=4 | Y,使用到 a,b,c |
| where b=3 或者 where b=3 and c=4 或者 where c=4 | N,没有 a |
| where a=5 and c=3 | Y,使用到 a,但是 c 不可以,中间 b 断了 |
| where a=3 and b>4 and c=5 | Y,使用到 a 和 b,但是 c 不可以,b 是范围 |
| where a=3 and b like 'kk%' and c=4 | Y,使用到 a,b,c |
| where a=3 and b like '%kk' and c=4 | Y,使用到 a |
| where a=3 and b like '%kk%' and c=4 | Y,使用到 a |
| where a=3 and b like 'k%kk%' and c=4 | Y,使用到 a,b,c |
五、总结
1.单行访问是很慢的。
2.按顺序访问范围数据是很快的。
3.索引覆盖查询是很快的。
4.查询中如果有多个范围查询,只有一个可以使用上索引。