ClustrixDB-高级架构概述
ClustrixDB是一种集群式RDBMS,可确保事务处理符合ACID特性,同时可轻松的提供可扩展性和容错能力。 ClustrixDB集群由三个或更多节点(联网的同构服务器)组成。
ClustrixDB使用无共享架构。集群中的每个节点可以执行任何读取或写入操作。如果要扩充数据库容量,只需添加更多节点即可。
ClustrixDB的主要组件有助于实现性能和规模:
1)全局事务管理器(GTM),协调给定事务的处理。
2)Rebalancer,它在集群中自动分配数据。
3) Sierra数据库引擎,确定最佳查询执行计划,然后在分布式数据节点上执行该计划。
下图显示了ClustrixDB如何处理典型的查询。
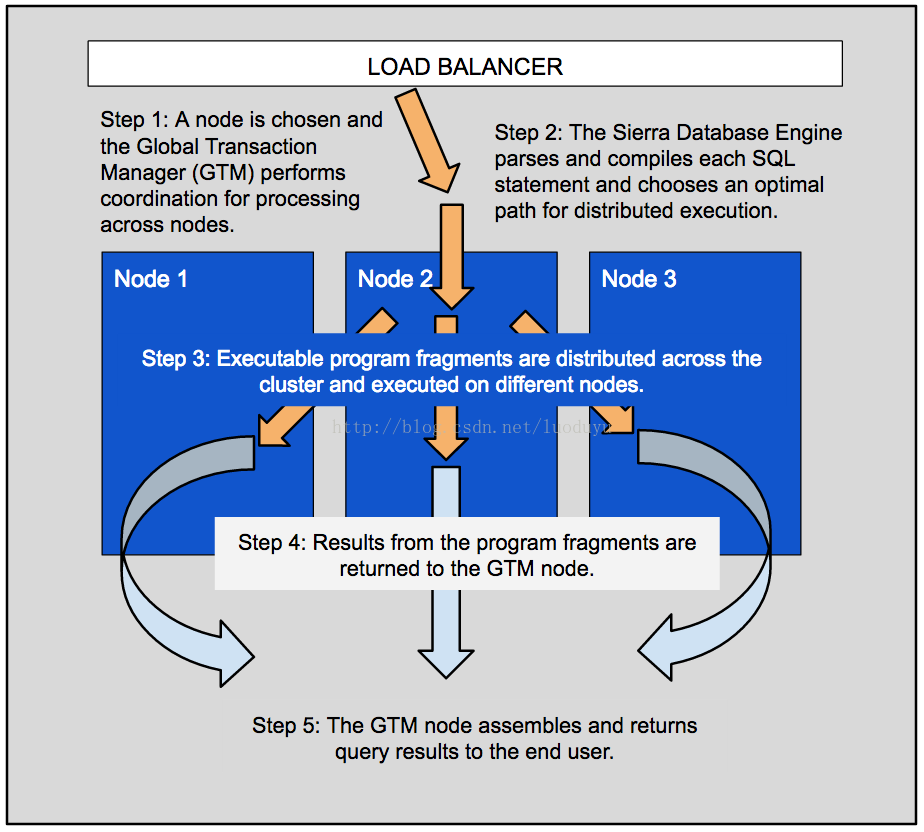
全局事务管理器
通常通过横跨集群上分布式连接的负载均衡器,选择集群中的一个节点作为全局事务管理器(GTM)来开始处理ClustrixDB中的查询。然后在返回结果给调用者之前,GTM通过控制执行查询的每个一步、确认每一步成功完成、收集和确定执行结果等来全面管理事务。
ClustrixDB将查询编译为可执行查询片段,GTM将其分发到适当的节点以供执行。当中间结果可用时,它们将返回给GTM。一旦所有查询片段都已成功执行,GTM就完成结果并将它们返回给客户端,应用程序或用户。
Rebalancer
如果ClustrixDB的数据以前未在整个集群中分布,则不可能进行分布式处理。为了实现这一点,ClustrixDB使用了由其Rebalancer管理的专利数据分配方法。Rebalancer在集群中编排数据,以确保读取和写入始终平衡。它还保证在整个集群中维护数据的多个副本(副本)以确保容错。如果节点由于意外故障而丢失,则不会丢失任何数据。Rebalancer将自动确保创建和维护冗余副本。它还通过在添加新节点时将数据重新平衡到新节点并且在数据库保持在线的同时将数据从标记为要移除的节点移开而适应集群集大小的改变。
Rebalancer使用一致的散列算法将每个表行分配给该表的给定“切片”,并提供所有切片到每个节点的映射。这允许ClustrixDB快速轻松地确定相关数据的位置。Rebalancer在后台连续运行,不会影响正在进行的数据处理。
虽然数据被切片并分发到集群的许多节点,但是数据库表将始终作为应用程序的单个逻辑单元出现。Clustrix使用简单的SQL接口,并且不需要特殊的应用程序编程来访问分布在整个ClustrixDB集群中的数据。
如果ClustrixDB的数据以前未在整个集群中分布,则不可能进行分布式处理。为了实现这一点,ClustrixDB使用由其Rebalancer管理的专利数据分配方法。Rebalancer在集群中安排数据,以确保读取和写入始终平衡。它还保证在整个集群中维护数据的多个副本(副本)以确保容错。如果节点由于意外故障而丢失,则不会丢失任何数据。重新平衡器将自动确保创建和维护冗余副本。它还通过在添加新节点时将数据重新平衡到新节点并且在数据库保持在线的同时将数据从标记为要移除的节点移开而适应群集的改变大小。
Rebalancer使用一致的散列算法将每个表行分配给该表的给定“切片”,并提供所有切片到每个节点的映射。这允许ClustrixDB快速轻松地确定相关数据的位置。再平衡器在后台连续运行,不会影响正在进行的生产加工。
下面这张图片展示了Rebalancer如何横跨各个节点的的’切片’和表复制。请注意表的复制是如何分散在整个集群中的,以确保容错。在不同节点上的每个表切片至少是按时及复制的。
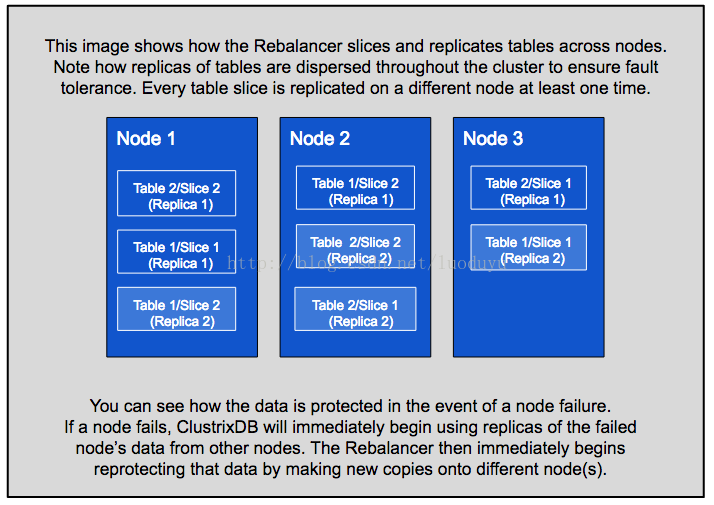
您可以看到在节点故障的情况下如何保护数据。如果节点故障,ClustrixDB将立即开始使用来自其他节点的故障节点数据的副本。然后Rebalancer立即开始通过将新副本复制到不同的节点上来重新定位该数据节点。
欲知详情请移步ClustrixDB’s
Rebalancer。
Sierra数据库引擎
Sierra是处理查询计划和执行的ClustrixDB的SQL引擎。它专门设计用于在分布式、无共享(shared nothing)环境中工作,同时尽可能高效地访问分布式数据。Sierra数据库引擎由两部分组成:
1)Sierra Parallel Planner 确定SQL语句的最佳执行计划。
2)Sierra分布式执行引擎 根据计划执行查询片段,并提供中间结果。
Sierra Parallel Planner是一种基于成本的优化器,它使用概率统计,数据量,索引和查询运算符的开销来确定最有效的查询计划。
ClustrixDB Planner 的一个关键区别功能是它确定此计划,同时考虑数据在集群中的分布。
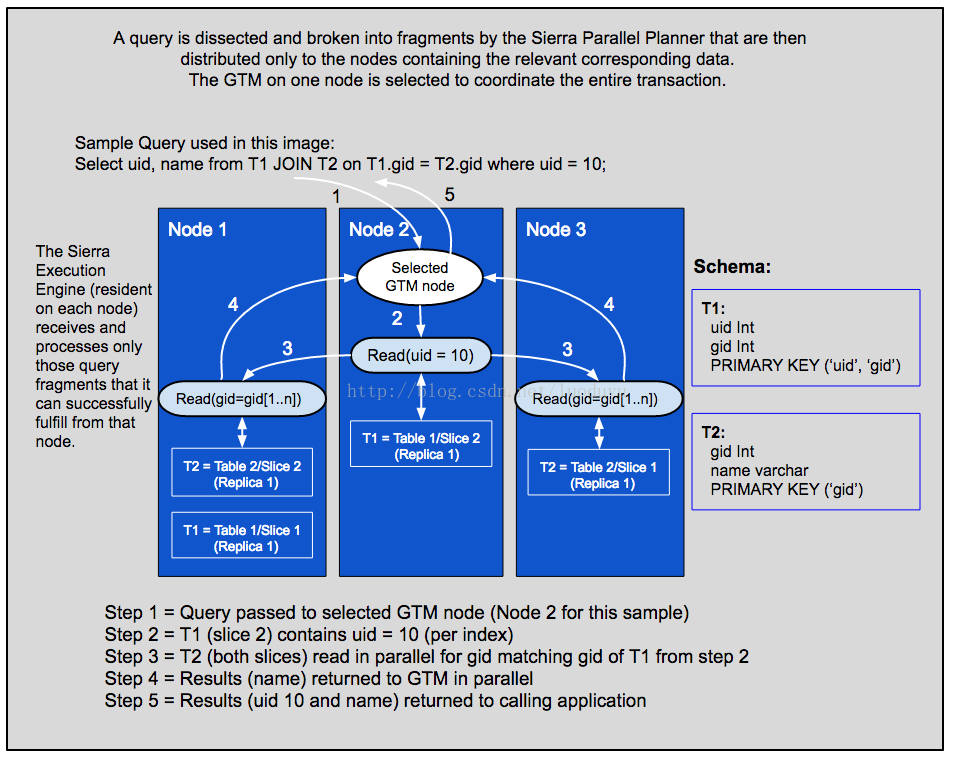
有关演示此查询分段如何工作的其他示例,请参阅ClustrixDB Sierra Database Engine.
Sierra分布式执行引擎
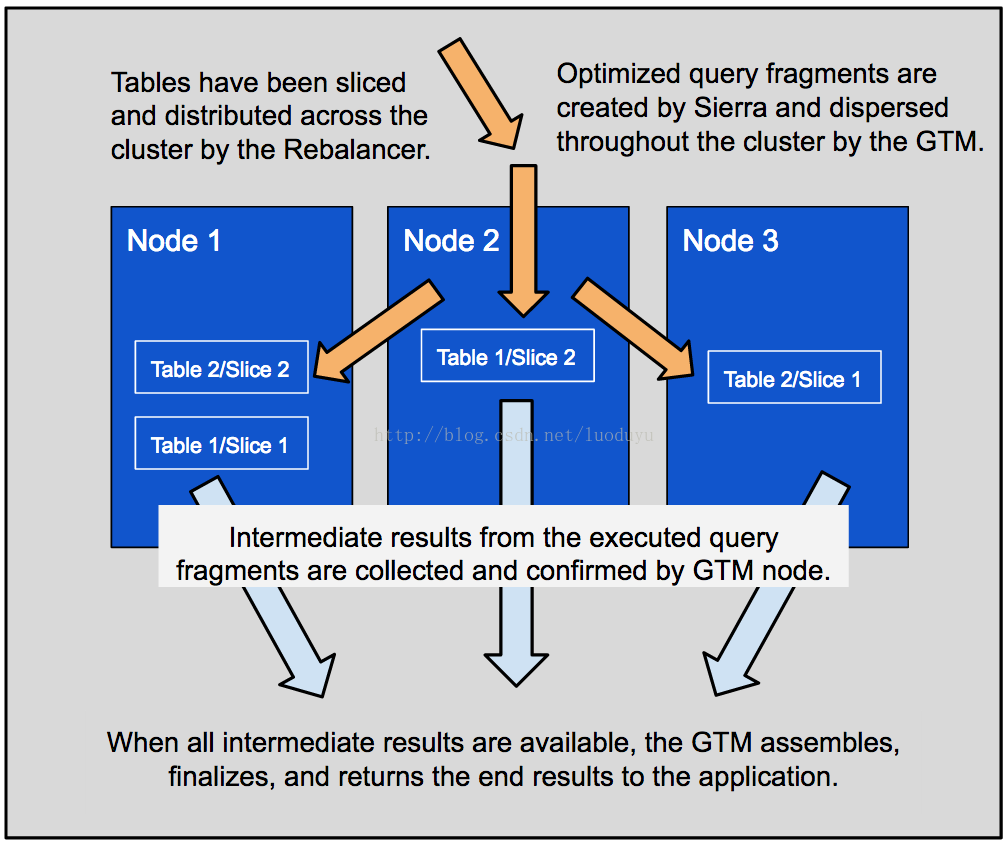
一旦Sierra Planner确定了查询的最佳计划,它就被编译成机器可执行的查询片段。然后,这些编译的查询片段在集群中的不同节点上执行,提供了效率和增加的执行并发性。一旦每个节点上的执行完成,结果就返回到GTM节点,GTM节点然后组合部分结果并将最终结果集返回给用户。
ClustrixDB如何能够独特地利用其分布式执行以实现更快的结果的一个示例是分布式聚合处理。除了首先对每个节点的分布式数据上的数据计算部分聚合(SUM,MAX,MIN,AVG等)之外,计算类似于其它查询被分段和分布。中间结果然后由GTM合并以产生最终结果。
最后再让我们来看下在ClustrixDB中的分布查询。
结论
ClustrixDB使用自动数据分发,复杂的查询计划器和分布式执行模型,以在符合ACID的RDBMS中提供可扩展性和并发性。为了实现这一点,ClustrixDB使用了许多与其他大规模并行处理(MPP)数据库使用的相同的技术:它使用Paxos进行分布式事务解析,并使用多版本并发控制(MVCC)来防止事务冲突。借助上述主要组件,ClustrixDB为这种分布式执行提供了一个简单的SQL接口,同时还提供了可扩展性,效率和容错能力。