如何在EF中直接运行SQL命令
相信不少使用EF的同志们已经知道如何在EF中运行SQL命令了。我在这里简单总结下,希望对大家学习EF有所帮助! 在 EF第一个版本(.NET 3.5 SP1)中,我们只能通过将ObjectContext.Connection转换为EntityConnection,再把 EntityConnection.StoreConnection转换为SqlConnection。有了这个SqlConnection,我们再创建 SqlCommand便能顺利运行SQL命令了。(个人觉得其实很烦,呵呵) 例如: EntityConnection entityConnection = (EntityConnection)ctx.Connection; DbConnection storeConnection = entityConnection.StoreConnection; DbCommand cmd = storeConnection.CreateCommand(); cmd.CommandType = System.Data.CommandType.StoredProcedure; cmd.CommandText = "[PRO_USER_DIGITALCARD_CHECK]"; 。。。。。。。 在EF4(.NET 4)中,我们有了全新的API:ObjectContext.ExecuteStoreCommand(…)和 ObjectContext.ExecuteStoreQuery<T>(…)。从函数名不难知道前者是为了执行某一并无返回集的SQL 命令,例如UPDATE,DELETE操作;后者是执行某一个查询,并可以将返回集转换为某一对象。 using (var ctx = new MyObjectContext()) { ctx.ExecuteStoreCommand("UPDATE Person SET Name = 'Michael' WHERE PersonID = 1"); } using (var ctx = new MyObjectContext()) { var peopleViews = ctx.ExecuteStoreQuery<PersonView>("SELECT PersonID, Name FROM Person"); } public class PersonView { public int PersonID { get; set; } public string Name { get; set; } } 现在有了EF4.1,API的名字又有了些许改变。如果说DbContext将ObjectContext做了包装,那么DbContext.Database就是对应于数据库端信息的封装。执行SQL命令也自然从Database类型开始。对应于ExecuteStoreCommand和ExecuteStoreQuery<T>的是Database.ExecuteSqlCommand和Database.SqlQuery<T>。 using (var ctx = new MyDbContext()) { ctx.Database.ExecuteSqlCommand("UPDATE Person SET Name = 'Michael' WHERE PersonID = 1"); } using (var ctx = new MyDbContext()) { var peopleViews = ctx.SqlQuery<PersonView>("SELECT PersonID, Name FROM Person").ToList(); } public class PersonView { public int PersonID { get; set; } public string Name { get; set; } } from:http://www.cnblogs.com/chengxiaohui/articles/2092001.html
View DetailsEntityFramework.BulkInsert扩展插入数据和EF本身插入数据比较
扩展下载地址:http://efbulkinsert.codeplex.com/ 注意同时安装依赖项目,不然会报错,还有,程序中有同一个dll的其他版本,那就可能一次安装不上,得一个一个安装依赖的dll Install-Package EntityFramework.MappingAPI -Version 6.0.0.7 Install-Package EntityFramework.BulkInsert-ef6 EntityFramework.BulkInsert插入数据和EF比较 初步猜测,它应该只是把多个sql合成一个,不管怎么优化,总该最后生成的是sql。 例如:20条数据,ef调试时看到的是一次连接,20次执行sql,这个批量,估计是一次连接,20个sql组合放到一个字符串提交,这样能减少时间。 再优化也不可能把sql给减少,同一sql在数据库中执行时间也不是EF能减少的。 实测(222数据库,表FinanceReceipts): 用Stopwatch监视执行时间(单位毫秒) 一次插入200条单据测试 EF插入耗时:11,086 BulkInsert插入耗时:740 一次插入10000条单据测试 EF插入耗时:510,640 BulkInsert插入耗时:3,200 通过看代码,和猜测的实现方式差不多,不过,代码中有表映射,为什么有这些功能? 因为 Insert 比数据库自带的 SqlBulkCopy 功能慢, EntityFramework.BulkInsert扩展在优化语句传输次数的同时,也采用了速度更快的 SqlBulkCopy 去将数据插入数据库,所以在插入大数据量时,比起EF本身的插入数据,可以说快得“离谱”。 不过,利用这个SqlBulkCopy快速插入数据,也就只能在插入上有改进,对于Update,Delete数据,速度上没有什么改进的 //批量插入测试代码 [csharp] view plain copy print? StringBuilder sb = new StringBuilder(); FinanceReceipts model = ReceiptsRepository.Entities.Include(o => o.FinanceReceiptDetail).Include(o => o.FinanceBillLog).First(o => o.ReceiptId == 214539); int createCount = 10000; model.ReceiptId = 0; model.ReceiptStatus = -1; model.ReceiptNo = ""; model.FinanceBillLog.OpenSafe().ToList().ForEach(m => m.ReceiptId = 0); model.FinanceReceiptDetail.OpenSafe().ToList().ForEach(m => m.ReceiptId = 0); model.ActualCreateTime = DateTime.Now; List<FinanceReceipts> entities = new List<FinanceReceipts>(); for (int i = 0; i < createCount; i++) { FinanceReceipts temp = model.DeepCopy(); model.ReceiptNo = "ef" + i; entities.Add(temp); } Stopwatch sw = new Stopwatch(); sw.Start(); ReceiptsRepository.Insert(entities); sw.Stop(); sb.AppendFormat("EF插入耗时:{0}\r\n", sw.ElapsedMilliseconds); model.ActualCreateTime = DateTime.Now; List<FinanceReceipts> entities2 = new List<FinanceReceipts>(); for (int i = 0; i < createCount; i++) { FinanceReceipts temp = model; model.ReceiptNo = "bi" + i; entities2.Add(temp); } sw.Restart(); var ctx = (this.UnitOfWork as UnitOfWorkContextBase).DbContext; using (var transactionScope = new TransactionScope()) { // some stuff in dbcontext ctx.BulkInsert(entities2); ctx.SaveChanges(); transactionScope.Complete(); } sw.Stop(); sb.AppendFormat("BulkInsert插入耗时:{0}\r\n", sw.ElapsedMilliseconds); string ret = sb.ToString(); 插入100条,每次插入一条,循环插入测试 第1次: EF插入耗时:9006 BulkInsert插入耗时:4173 第2次: EF插入耗时:8738 BulkInsert插入耗时:3806 第3次: EF插入耗时:8784 BulkInsert插入耗时:3727 BulkInsert还是比EF本身插入数据稍微快一点,总的来说: […]
View DetailsADO.NET ENTITY FRAMEWORK : (二十) 提升EF执行速度方法
这边分享一下,提升ADO.Net Entity Framework执行速度的几个方法, 技巧一 取得单一数据时,可利用【GetObjectByKey】 在预设中,ObjectContext 在查询数据的时候,并不会以快取对象作为优先查询, 会在每次查询时都向数据库要数据,对效能会产生一定的影响, 因此可以利用【GetObjectByKey】方法来对快取对象进行查询, 但如果使用【GetObejctByKey】方法进行查询,而快取对象又不存在时, 会发生 ObjectNotFoundException 例外, 要避免此问题可利用【TryGetObejctByKey】方法, 如果在快取对象中找不到数据时,会回传 false,
|
1 2 3 4 5 6 7 8 9 10 |
////示范一 TryGetObjectByKey using (TestEntities te = new TestEntities()) { object entity; EntityKey key = new EntityKey("TestEntities.User", "User_id", 1); te.TryGetObjectByKey(key, out entity); ////使用 entity 对象 ////.... } |
技巧二 重复执行相同查询语法,可利用已编译查询【CompiledQuery】 在我们每次下达 Linq to Entities 向数据库查询数据时, 会先编译成 Entity SQL Language ,再经由 Provider 转换成对应该数据库的语法, 如果我们在循环里,对同一个查询下达1000次的话,就要经过1000次的转换, 这是很浪费效能的, 因此 ADO.Net Entity Framework 提供了 CompiledQuery 类别, 可以进行查询的编译和快取以供重复使用, 这边简单看一个范例
|
1 2 3 4 5 |
/// <summary> /// 已编译查询 /// </summary> private static readonly Func<TestEntities, int ,User> CompiledQueryGetUserById = CompiledQuery.Compile<TestEntities, int, User>((te, id) => te.User.Where(a=>a.User_id == id).FirstOrDefault()); |
|
1 2 3 4 5 6 |
////示范二 CompiledQuery using (TestEntities te = new TestEntities()) { //// 利用 CompiledQuery 取得数据 User u = CompiledQueryGetUserById.Invoke(te, 1); } |
技巧三 只进行查询,而不异动数据时 可利用【MergeOption.NoTracking】 使用【MergeOption.NoTracking】时, 因为不会再 ObjectStateManager 中追踪对象异动状态, 因此查询时效能较好,(系统默认是使用【MergeOption.AppendOnly】) 范例
|
1 2 3 4 5 |
////示范三 MergeOption.NoTracking using (TestEntities te = new TestEntities()) { User u = te.User.Execute(MergeOption.NoTracking).Where(a => a.User_id == 1).FirstOrDefault(); } |
参考连结 CompiledQuery 类别 已编译的查询 (LINQ to Entities) MergeOption 列举型别 ObjectStateManager ObjectContext..::.TryGetObjectByKey 方法 from:http://it.zhaozhao.info/archives/16465
View DetailsEF批量操作之高性能篇
【摘要】 EF(Entity Framework)是一种ORM框架,它能把我们在编程时使用对象映射到底层的数据库结构。使用EF能较大地提升数据库应用的开发效率,与ADO.NET一样,EF在使用上也很灵活。但是同其他ORM框架一样,在批量更新和插入操作时,EF有很严重的性能问题,本文主要介绍使用ADO.NET中的批量插入功能来改善EF批量插入和更新的性能问题。 【正文】 一、插入功能 用EF原生的插入功能进行批量插入,使用SQL Server Profiler对数据库进行分析会发现,每一行数据都生成了一条insert语句,这样子插入的效率是很低的。 Profiler结果 而在ADO.NET中提供为SqlServer专门提供了SqlBulkCopy类用来处理大批量的数据插入问题,因此下面介绍一下在如何将其集成在我们的项目当中。 1、在代码中使用反射从EF获取对应的数据库字段,然后使用SqlBulkCopy映射后插入 2、如果连续三次插入失败,才认为此次操作失败 二、批量更新功能 用EF原生的功能进行批量操作的代码如下,使用SQL Server Profiler对数据库进行分析会发现和插入一样会为每一行数据都会生成一条Sql更新语句。 我们想要提高批量更新操作速度的思路就是先将数据批量插入到数据库当中,然后在数据库当中进行批量更新操作。 1、和批量插入一样,为了保证程序的健壮性,只有连续三次更新都失败时,才会认为更新失败 2、在代码中拼接sql语句,使用ADO.NET生成一个与待更新数据库结构一致的临时表,然后最后再拼接出更新用的语句,最后使用ADO.NET在数据库表之间做批量更新的操作。 使用100000条数据进行测试,使用原生的方法插入时,在两分钟内没有返回结果,修改后的方法只需要700ms。修改后的批量插入也能保证在1000ms内返回结果。 from:http://www.canway.net/Original/ruanjiankaifa/0120KR016.html
View DetailsMySQL中使用innobackupex、xtrabackup进行大数据的备份和还原教程
大数据量备份与还原,始终是个难点。当MYSQL超10G,用mysqldump来导出就比较慢了。在这里推荐xtrabackup,这个工具比mysqldump要快很多。 一、Xtrabackup介绍 1、Xtrabackup是什么 Xtrabackup是一个对InnoDB做数据备份的工具,支持在线热备份(备份时不影响数据读写),是商业备份工具InnoDB Hotbackup的一个很好的替代品。 Xtrabackup有两个主要的工具:xtrabackup、innobackupex 1、xtrabackup只能备份InnoDB和XtraDB两种数据表,而不能备份MyISAM数据表 2、 innobackupex是参考了InnoDB Hotbackup的innoback脚本修改而来的.innobackupex是一个perl脚本封装,封装了xtrabackup。主要是为了方便的 同时备份InnoDB和MyISAM引擎的表,但在处理myisam时需要加一个读锁。并且加入了一些使用的选项。如slave-info可以记录备份恢 复后,作为slave需要的一些信息,根据这些信息,可以很方便的利用备份来重做slave。 2、Xtrabackup可以做什么 : 在线(热)备份整个库的InnoDB、 XtraDB表 在xtrabackup的上一次整库备份基础上做增量备份(innodb only) 以流的形式产生备份,可以直接保存到远程机器上(本机硬盘空间不足时很有用) MySQL数据库本身提供的工具并不支持真正的增量备份,二进制日志恢复是point-in-time(时间点)的恢复而不是增量备份。 Xtrabackup工具支持对InnoDB存储引擎的增量备份,工作原理如下: (1)首先完成一个完全备份,并记录下此时检查点的LSN(Log Sequence Number)。 (2)在进程增量备份时,比较表空间中每个页的LSN是否大于上次备份时的LSN,如果是,则备份该页,同时记录当前检查点的LSN。 首 先,在logfile中找到并记录最后一个checkpoint(“last checkpoint LSN”),然后开始从LSN的位置开始拷贝InnoDB的logfile到xtrabackup_logfile;接着,开始拷贝全部的数据文 件.ibd;在拷贝全部数据文件结束之后,才停止拷贝logfile。 因为logfile里面记录全部的数据修改情况,所以,即时在备份过程中数据文件被修改过了,恢复时仍然能够通过解析xtrabackup_logfile保持数据的一致。 因为innobackupex支持innodb,myisam,所以本文说一下,怎么使用innobackupex。 二,安装xtrabackup 1、下载地址 http://www.percona.com/downloads/XtraBackup/ 2、安装 根据需求,选择不同的版本,我选择的是rpm安装包,如果报以下错误 复制代码代码如下: [root@localhost xtrabackup]# rpm -ivh percona-xtrabackup-2.2.4-5004.el6.x86_64.rpm warning: percona-xtrabackup-2.2.4-5004.el6.x86_64.rpm: Header V4 DSA/SHA1 Signature, key ID cd2efd2a: NOKEY error: Failed dependencies: perl(Time::HiRes) is needed by percona-xtrabackup-2.2.4-5004.el6.x86_64 解决办法: 复制代码代码如下: [root@localhost xtrabackup]# yum -y install perl perl-devel libaio libaio-devel perl-Time-HiRes perl-DBD-MySQL //安装依赖包 [root@localhost xtrabackup]# rpm -ivh percona-xtrabackup-2.2.4-5004.el6.x86_64.rpm //重新安装 warning: percona-xtrabackup-2.2.4-5004.el6.x86_64.rpm: Header V4 DSA/SHA1 Signature, key […]
View DetailsMySQL 数据备份与还原
一、数据备份 1、使用mysqldump命令备份 mysqldump命令将数据库中的数据备份成一个文本文件。表的结构和表中的数据将存储在生成的文本文件中。 mysqldump命令的工作原理很简单。它先查出需要备份的表的结构,再在文本文件中生成一个CREATE语句。然后,将表中的所有记录转换成一条INSERT语句。然后通过这些语句,就能够创建表并插入数据。 1、备份一个数据库 mysqldump基本语法: mysqldump -u username -p dbname table1 table2 …-> BackupName.sql 其中: dbname参数表示数据库的名称; table1和table2参数表示需要备份的表的名称,为空则整个数据库备份; BackupName.sql参数表设计备份文件的名称,文件名前面可以加上一个绝对路径。通常将数据库被分成一个后缀名为sql的文件; 使用root用户备份test数据库下的person表
|
1 |
mysqldump -u root -p test person > D:\backup.sql |
其生成的脚本如下: 文件的开头会记录MySQL的版本、备份的主机名和数据库名。 文件中以“--”开头的都是SQL语言的注释,以"/*!40101"等形式开头的是与MySQL有关的注释。40101是MySQL数据库的版本号,如果MySQL的版本比1.11高,则/*!40101和*/之间的内容就被当做SQL命令来执行,如果比4.1.1低就会被当做注释。 2、备份多个数据库 语法:
|
1 |
mysqldump -u username -p --databases dbname2 dbname2 > Backup.sql |
加上了--databases选项,然后后面跟多个数据库
|
1 |
mysqldump -u root -p --databases test mysql > D:\backup.sql |
3、备份所有数据库 mysqldump命令备份所有数据库的语法如下:
|
1 |
mysqldump -u username -p -all-databases > BackupName.sql |
示例:
|
1 |
mysqldump -u -root -p -all-databases > D:\all.sql |
2、直接复制整个数据库目录 MySQL有一种非常简单的备份方法,就是将MySQL中的数据库文件直接复制出来。这是最简单,速度最快的方法。 不过在此之前,要先将服务器停止,这样才可以保证在复制期间数据库的数据不会发生变化。如果在复制数据库的过程中还有数据写入,就会造成数据不一致。这种情况在开发环境可以,但是在生产环境中很难允许备份服务器。 注意:这种方法不适用于InnoDB存储引擎的表,而对于MyISAM存储引擎的表很方便。同时,还原时MySQL的版本最好相同。 3、使用mysqlhotcopy工具快速备份 一看名字就知道是热备份。因此,mysqlhotcopy支持不停止MySQL服务器备份。而且,mysqlhotcopy的备份方式比mysqldump快。mysqlhotcopy是一个perl脚本,主要在Linux系统下使用。其使用LOCK TABLES、FLUSH TABLES和cp来进行快速备份。 原理:先将需要备份的数据库加上一个读锁,然后用FLUSH TABLES将内存中的数据写回到硬盘上的数据库,最后,把需要备份的数据库文件复制到目标目录。 命令格式如下:
|
1 |
[root@localhost ~]# mysqlhotcopy [option] dbname1 dbname2 backupDir/ |
dbname:数据库名称; backupDir:备份到哪个文件夹下; 常用选项: --help:查看mysqlhotcopy帮助; --allowold:如果备份目录下存在相同的备份文件,将旧的备份文件加上_old; --keepold:如果备份目录下存在相同的备份文件,不删除旧的备份文件,而是将旧的文件更名; --flushlog:本次辈分之后,将对数据库的更新记录到日志中; --noindices:只备份数据文件,不备份索引文件; --user=用户名:用来指定用户名,可以用-u代替; --password=密码:用来指定密码,可以用-p代替。使用-p时,密码与-p之间没有空格; --port=端口号:用来指定访问端口,可以用-P代替; --socket=socket文件:用来指定socket文件,可以用-S代替; mysqlhotcopy并非mysql自带,需要安装Perl的数据库接口包;下载地址为:http://dev.mysql.com/downloads/dbi.html 目前,该工具也仅仅能够备份MyISAM类型的表。 二、数据还原 1、还原使用mysqldump命令备份的数据库的语法如下: mysql -u root -p [dbname] < backup.sq 示例:
|
1 |
mysql -u root -p < C:\backup.sql |
2、还原直接复制目录的备份 通过这种方式还原时,必须保证两个MySQL数据库的版本号是相同的。MyISAM类型的表有效,对于InnoDB类型的表不可用,InnoDB表的表空间不能直接复制。 from:http://www.cnblogs.com/kissdodog/p/4174421.html
View Detailsmysql数据库ibdata1文件瘦身
MYSQL运行2年之后ibdata1文件变的非常巨大,传说ibdata1是InnoDB的产物,而且只会增大不会减少。 上网搜了一下解决方法。大体思路就是备份数据,然后删除数据库再还原数据库。 # 备份数据库: mysqldump -uDBuser -pPassword --quick --force --routines --add-drop-database --all-databases --add-drop-table > /data/bkup/mysqldump.sql # 停止数据库 service mysqld stop # 删除这些大文件 rm /usr/local/mysql/var/ibdata1 rm /usr/local/mysql/var/ib_logfile* # 手动删除除Mysql之外所有数据库文件夹,然后启动数据库 service mysqld start # 还原数据 mysql -uDBuser -pPassword < /data/bkup/mysqldump.sql from:http://blog.sina.com.cn/s/blog_40ce02d7010169zr.html
View Details
三星i959 5.0 root教程_三星i959获取5.0系统的root方法
三星i959手机的最新系统也是5.0的,看到已经有不少的机友升到5.0的系统了,可是很多机友到了5.0的系统之后却不知道如何进行root,因此下面给大家整理了一下详细的root教程供大家参考一下了,因为这个手机的5.0的系统目前还没有专用的一键root软件,所以要想进行root的话还是需要采用别的方法,今天在这里就来给大家说另一种root方法,那就是采用卡刷的方式进行root了,下面一起来看看详细的root过程吧: 一:三星i959刷5.0系统root包前的准备工作: 1:下载迷你手机网提供的root包,点击这里下载,下载下来先放到电脑上进行解压,一会儿要用到。 2:确保手机能用usb数据线正常的连接电脑,连接电脑是为了把上面下载的root包复制到手机的sd卡里 3:因为是卡刷,所以手机里必须先要刷入第三方的recovery才可以,如果你的手机里还没有刷入第三方的recovery的话,点击这里查看详细的刷入recovery的教程,这个recovery是可以用来刷root包的 二:三星i959开始卡刷root包的操作: 1:手机用usb数据线连接上电脑之后,把上面下载下来的rar格式的root包在电脑上进行解压,解压出来一个文件夹,然后在解压出来的文件里的找到【Root-SuperSU-v2.45.zip】包复制到手机的sd卡的根目录下方便找到。 2:进入刷好的recovery中 (进入的方法:手机先关机,然后手机在关机的状态下,同时按住手机的音量键上键 + home键 + 电源键不松,数秒后手机即可进入recovery界面了) 3:返回主界面,按音量键选择【安装zip刷机包】然后再选择【从/sdcard读取刷机包】,然后找到刚才复制到手机sd卡根目录下的zip格式的root包,然后再选择【是的-安装Root-SuperSU-v2.45.zip】,按电源键确认 4:等待root包刷入完成后,回到recovery主界面,最后选择【重启设备】 5:root完成 (本文来源) http://www.netded.com/a/jingpinshouji/2015/0406/30335.html from:http://www.netded.com/a/jingpinshouji/2015/0406/30335.html
View Details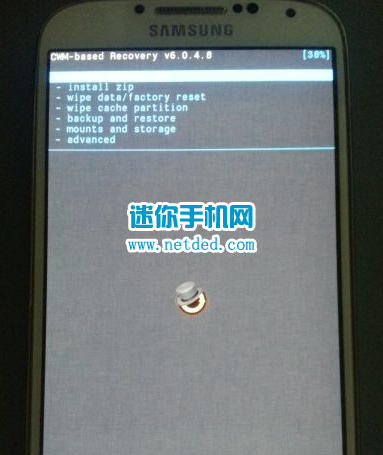
三星I959刷recovery的教程_三星I959中文recovery下载
在这里要说的是有关三星I959手机的第三方recovery,在网上已经看到很多机友发布出来了,现在很多人已经刷入了,为什么要说这个第三方的recovry呢,因为咱们的手机系统要想刷第三方的zip包的话,手机必须先要刷入第三方的recovery才可以,今天主要就是来给大家说说咱们的手机系统如何刷第三方的recovery了,这个recovery还是英文版的,有需要的可以一起来看看详细的操作: 一:三星I959刷recovery前的准备工作: 1:确认你的手机能和电脑用数据线正常的连接,这个是必须的 2:电脑上一定要安装的有三星I959的驱动,如果你的手机还没有安装驱动的话,点击这里下载安装>>>> 3:下载rar格式的recovery包,点击这里下载中文版recovery,点击这里下载英文版recovery,(大家根据自己的需求来下载自己喜欢的版本)下载下来放到电脑上进行解压就可以了 4:下载刷机工具包odin,点击这里下载,这个工具包下载下来放到电脑上解压 二:三星I959开始刷入recovery包: 1:手机先完全的关机,然后同时按住手机的音量下键 + HOME键 + 电源键,等待3秒,出现英文界面 2:然后再按音量上键,进入界面为绿色机器人,此为刷机模式 上图仅供参考 3:把上面下载下来的odin工具包解压出来,解压出来之后有一个文件夹,点击进入会看到多个版本的odin,并且都是exe格式的,咱们选择最新版的odin工具双击打开就行了。 4:打开odin软件之后软件会自动识别你的手机,识别成功后会在ID:COM处显示蓝色的(表示手机连接成功了,如果没有显示蓝色的,说明没有有连接好),然后勾选AP,选择上面下载并解压出来的tar格式的recovery包。 5:一切都选好之后,点击start开始刷入 6:刷完之后,上面会显示【PASS】字样就表示刷入成功了。 7:至此recovery刷入完毕 手动进入recovery的方法: 手机先关机,然后手机在关机状态下按住手机的音量上键 + Home键 + 电源键(三键一起按),一会就会进入recovery界面了。 上图是中文版recovery界面,仅供参考 上图是英文版recovery 如果显示上面的效果图的话,说明recovery刷入成功了。 from:http://www.netded.com/a/jingpinshouji/2014/0521/28270.html
View DetailsPowerShell DSC and implicit remoting broken in KB3176934
On August 23, Windows update KB3176934 released for Windows Client. Due to a missing .MOF file in the build package, the update breaks DSC. All DSC operations will result in an “Invalid Property” error. In addition, due to a missing binary in the build package the update breaks PowerShell implicit remoting. Implicit remoting is a PowerShell feature where PowerShell commands work on a remote session instead of locally. Specifically, importing a remote session no longer works: $remoteSession = New-PSSession -Cn TargetComputer Import-PSSession -Session $remoteSession Import-PSSession : Could not […]
View Details