【Kibana】Kibana入门教程
一、Kibana简介及下载安装
Kibana是专门用来为ElasticSearch设计开发的,可以提供数据查询,数据可视化等功能。
下载地址为:https://www.elastic.co/downloads/kibana#ga-release,请选择适合当前es版本的Kibana。
本教程使用Kibana4.5.4版本,以及es2.3.5版本。假定你已经具有es基本的知识。
1.1 安装步骤
安装步骤比较简单。
- 下载完后解压到任意目录。
- 启动es
- 配置config目录下的kibana.yml的elasticsearch.url指向es地址
- 运行bin目录下的kibana
- 如果没有修改配置文件的端口,那么在浏览器中输入http://localhost:5601
- 启动Kibana后,Kibana会自动在配置的es中创建一个名为.kibana的索引,用来存储数据,注意不要删除了。
1.2 数据准备
启动后如果显示如下界面:
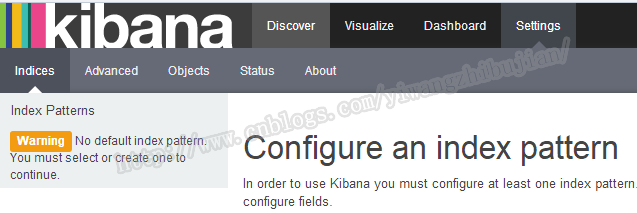
说明Kibana没有在es中找到合适的index用来展示,如果es中没有数据,那么可以导入官方测试数据,用来学习操作。
如果你的es中已经有可以用来测试的数据,那么可以略过本节。
首先下载三个数据文件:
- 莎士比亚完整的作品,shakespeare.json
- 虚构的随机的账目数据,accounts.zip
- 随机的日志文件,logs.jsonl.gz
下载后解压最后两个压缩包:
|
1 2 |
unzip accounts.zip gunzip logs.jsonl.gz |
设置莎士比亚的mapping,有三个index,因为假定是三天的日志,按天来生成索引:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
curl -XPUT http://localhost:9200/shakespeare -d ' { "mappings" : { "_default_" : { "properties" : { "speaker" : {"type": "string", "index" : "not_analyzed" }, "play_name" : {"type": "string", "index" : "not_analyzed" }, "line_id" : { "type" : "integer" }, "speech_number" : { "type" : "integer" } } } } } '; |
设置日志的mapping:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
curl -XPUT http://localhost:9200/logstash-2015.05.18 -d ' { "mappings": { "log": { "properties": { "geo": { "properties": { "coordinates": { "type": "geo_point" } } } } } } } '; |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
curl -XPUT http://localhost:9200/logstash-2015.05.19 -d ' { "mappings": { "log": { "properties": { "geo": { "properties": { "coordinates": { "type": "geo_point" } } } } } } } '; |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
curl -XPUT http://localhost:9200/logstash-2015.05.20 -d ' { "mappings": { "log": { "properties": { "geo": { "properties": { "coordinates": { "type": "geo_point" } } } } } } } '; |
最后将数据导入es:
|
1 2 3 |
curl -XPOST 'localhost:9200/bank/account/_bulk?pretty' --data-binary @accounts.json curl -XPOST 'localhost:9200/shakespeare/_bulk?pretty' --data-binary @shakespeare.json curl -XPOST 'localhost:9200/_bulk?pretty' --data-binary @logs.jsonl |
导入后,输入以下命令检查结果,当然如果导入的过程中没有报错也表明导入成功:
|
1 |
curl 'localhost:9200/_cat/indices?v' |
应该输出下面的结果,当然容量也有可能有些差别。
|
1 2 3 4 5 6 |
health status index pri rep docs.count docs.deleted store.size pri.store.size yellow open bank 5 1 1000 0 418.2kb 418.2kb yellow open shakespeare 5 1 111396 0 17.6mb 17.6mb yellow open logstash-2015.05.18 5 1 4631 0 15.6mb 15.6mb yellow open logstash-2015.05.19 5 1 4624 0 15.7mb 15.7mb yellow open logstash-2015.05.20 5 1 4750 0 16.4mb 16.4mb |
这样的话数据就准备完毕了。
1.3 配置index
一般情况下,当启动Kibana的时候会自动搜索可用来展示的索引,如果你需要的没有被搜到,或者如上面新增的数据的索引没有检测到,那么key手动添加索引。配置index的位置为:
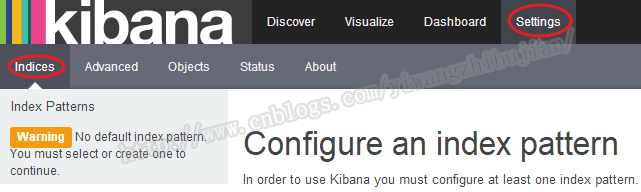
这样我们把刚才新增的数据的索引配置进去。
1.3.1 不带时间戳,或者没有字段表示时间戳
不要勾选包含时间的选项,输入index的名称,可以使用通配符,如果Create是灰色的,那么表明输入的索引不正确,请检查拼写。
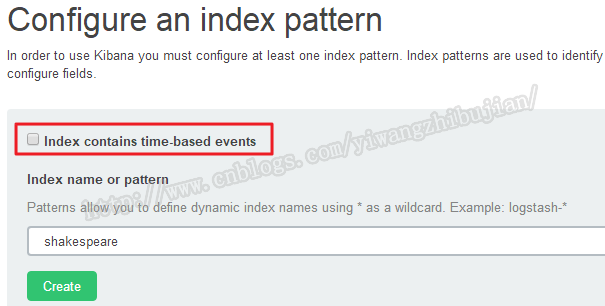
点击创建后,会出现当前索引的所有字段,可对这些字段进行一些属性编辑,具体不再本文介绍。按同样的方式把bank配置进去。
1.3.2 带时间戳的
继续新增index,这次是带时间戳的,至于带不带时间戳会有什么不一样的,后面介绍就会明白了。
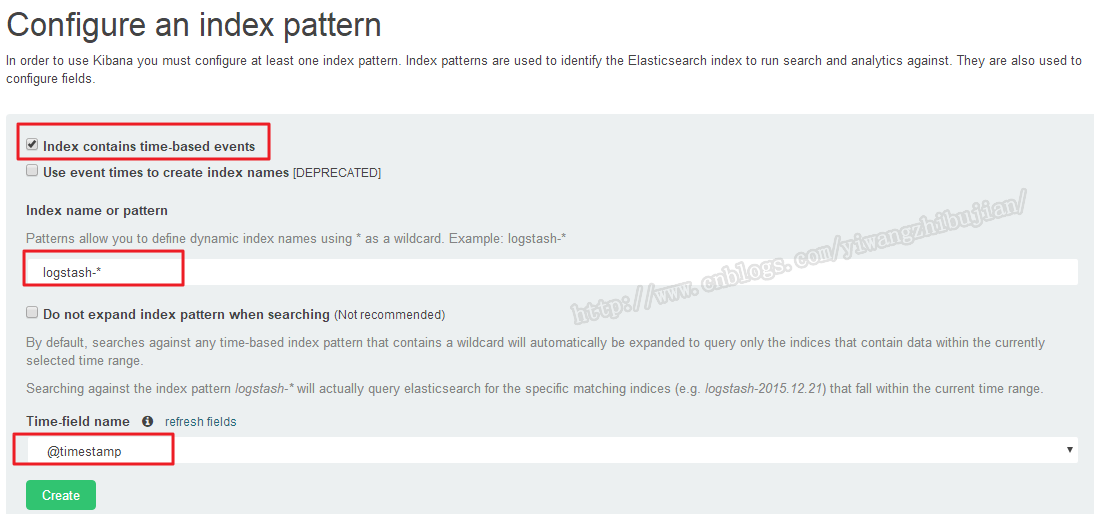
勾选包含时间,索引使用通配符,代表上面三个日志索引,时间字段选择@timestamp。点击创建就可以了。
这样基本工作就做好了,下面进入Kibana的实际讲解。
二、Kibana使用教程
首先看一下Kibana的主界面:
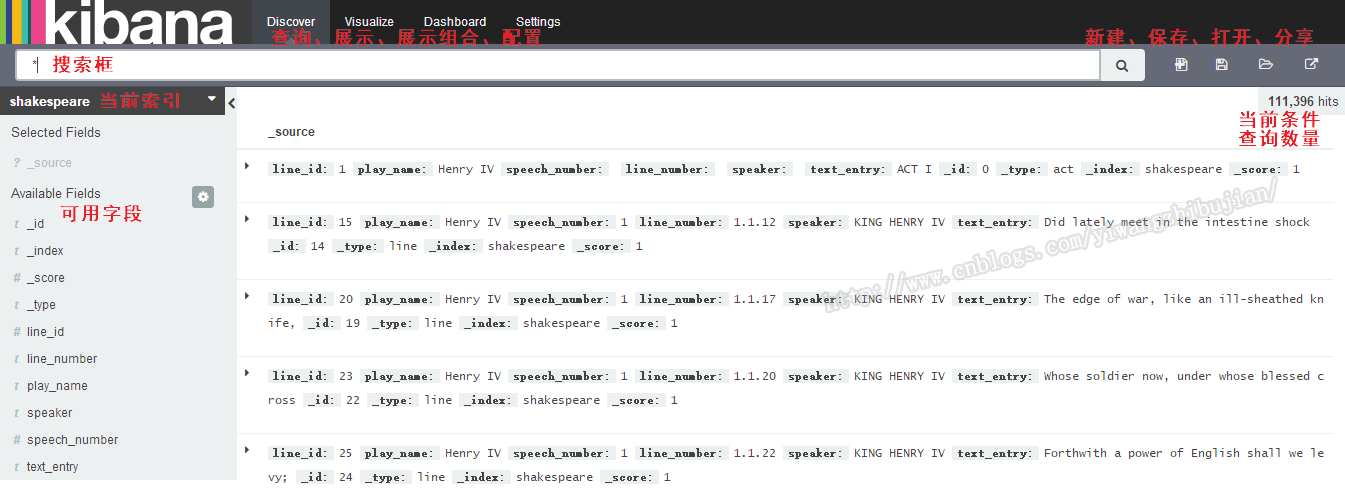
按照顺序讲解。
2.1 查询
查询是在指定索引的情况下查询,可以通过索引右侧下三角来选择其他索引。如果选择了logstash-*,没有数据也不要着急,后面会讲到。
2.1.1 查询语法
查询语法就是指明查询条件,用于过滤数据用的。
单纯的数据一个字符串,表明在当前索引的所有字段中,搜索包含当前字符串的记录:
如果要指定在某个字段中搜索,则使用filedname:searchtext的格式:

这样查询到一条数据,也可以使用区间,格式为filedname:[start TO end],如下面的语法就查询到10条数据。

也可以使用逻辑表达式并且可以带上括号,表达式符号为AND OR NOT。

表明在1000行内,有12行中包含love。
2.1.2 隐藏的时间查询限定条件
如果配置索引的时候选择了带时间戳,那么查询条件会默认加上一个时间条件,选择那样的索引后,右上角会出现时间条件:
所以,这个时候需要设置需要的时间:
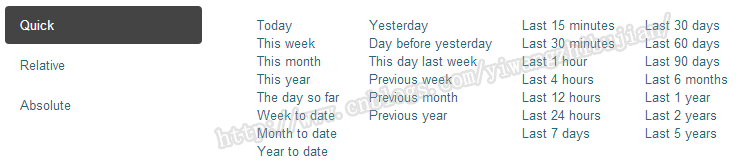
因为时间可以设置为绝对时间,也可以设置为相对时间。当设置为相对时间时,数据其实是不断发生变化的,比如设置为上一个小时,那么当前查询的数据结果,在下一分钟有可能就不是正常的,所以此时可以指定一个刷新时间,用来不断显示新的数据。

刷新时间默认不是开启的,需要手动开启,根据选择的时间范围来选择刷新间隔,相对时间范围越窄则刷新间隔应该越短。
2.1.3 指定显示查询结果
默认情况下,查询结果显示所有字段,即_source的内容:

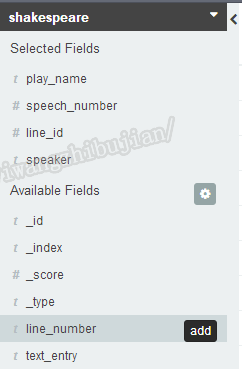
可以有时候只想关注一些指定的字段,那么可以将鼠标移动到索引下面的字段上,然后选在add即可,同样的移动上面已经选择的字段选择remove进行移除:
选择后,展示的结果就会以表格的形式进行展示:

2.1.4 复杂查询
通过搜索框进行查询的语法很多时候满足不了我们的要求,有时候我们需要使用自定义语法,在讲解复杂查询之前,先来讲另一个可玩的特性,就是说当我们点击某一个字段时,会把当前字段数量最多的前5个值及占比显示出来:
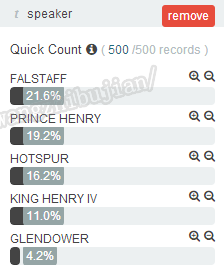
点击右侧的+号可以将当前值做为一个条件附加到搜索框的搜索条件上:
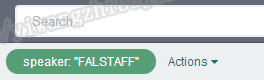
这个条件是在上面搜索结果的基础上继续进行筛选,鼠标移到上面会显示:

基本功能如图例所示,重点讲解最后一个即编辑,点击编辑后:
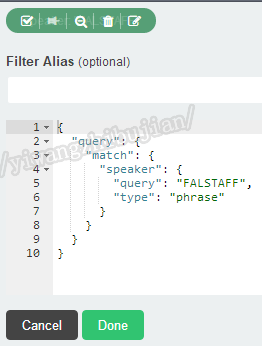
会出现熟悉的语法界面,在此处即可完成复杂的语法编写。
2.1.5 查询结果的保存
搜索界面的右侧 有四个图标,分别为新建、保存、打开、分享:

也就是说可以将当前查询的条件保存下来,供后续使用,也可以分享给别的用户来查看,保存下来的条件可以用做后续数据及图标的展示。
2.2 可视化展示
一般来说我们是很少给用户展示赤裸裸的数据,而用户也不想看到这些,他们想看的是一个结果,一种趋势图,一种比例图这种直观的结果,可视化展示就是满足这个需求的。
点击最上面的visualize即可进行编辑页面:
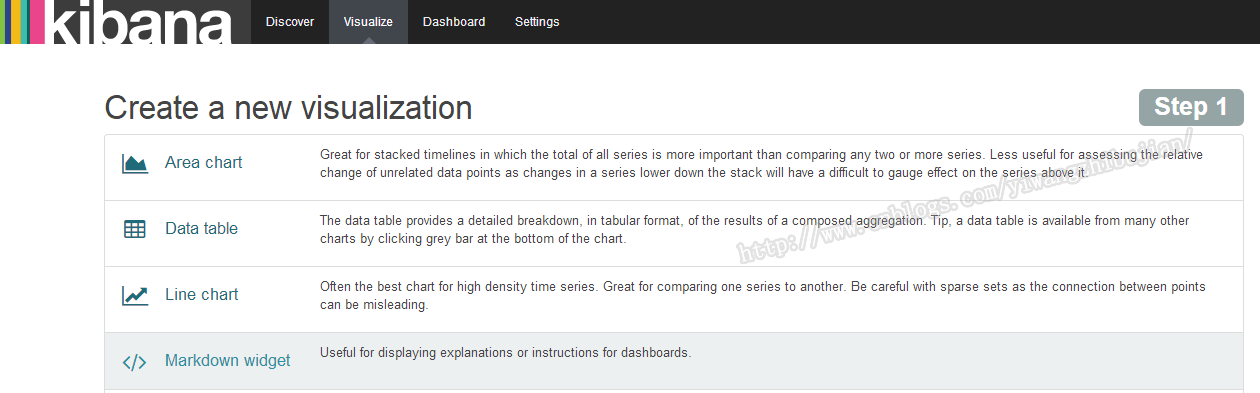
可以看到Kibana给我们提供了各种各样的用来展示的模板,根据你的需求来选择合适的,下面我就多创建几个来看看。创建步骤:
- 选择指定模板
- 选择搜索源,可以用刚才保存的也可新建
- 最后进行具体编辑
2.2.1 新建一个数据表格
点击Data Table,然后左侧选择Split Rows:
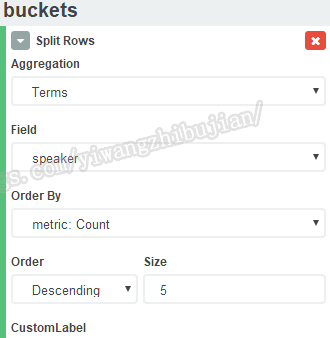
我们选择按照朗读者进行计数:
最后点击上面的三角箭头,会在右侧出现结果:

此时可以把它保存起来。
用同样的方式,再多建几个图例。
三、DashBoard 展示
上面的展示只是单个图标的展示,但是大部分情况下,我们需要同时查看多个图标,dashboard就提供这种功能给我们使用。
前提是我们有上面保存的展示。

然后点击+图标来把各种图例放进去,效果如下图:
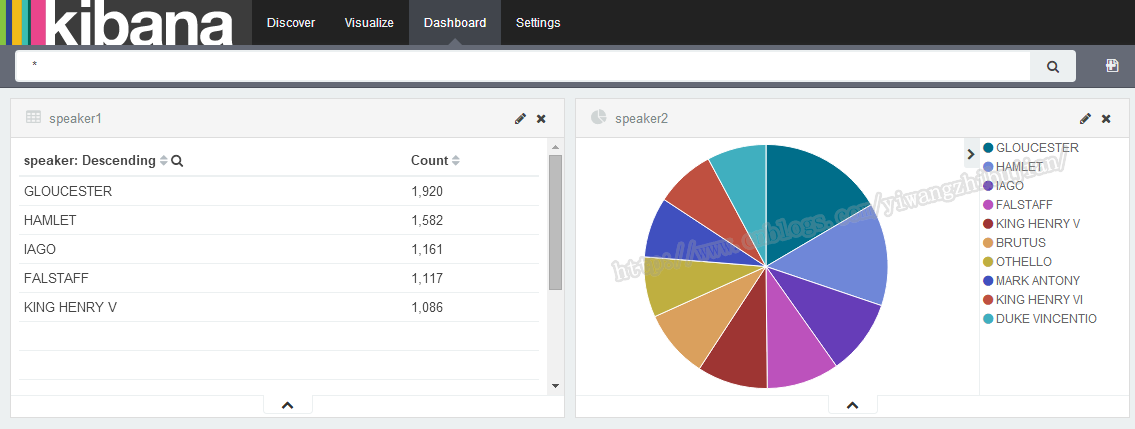
可以自由拖动各个组件以及修改它们的大小。
这就是Kibana的基本用法,如果还有没有介绍清楚的后续会补上,图片如果看不清可以查看原图。